Every team that adopts AI coding keeps its SDLC. The stand-ups still happen, the pull requests still open, the release train still leaves on Thursday. What changes is invisible: the assumptions inside each stage quietly stop holding.
“Requirements” used to mean a document a human would slowly translate into code — now it is a prompt an agent sprints past. “Code review” used to mean reading a diff a human wrote line by line — now it is reading a diff a machine generated faster than anyone can think. “Tests passed” used to mean a person watched them pass — now it can mean a suite that asserted nothing went green.
Here is that last one, exactly as it happened on a real project. A Playwright suite for an admin portal had a test that imported a bill through the real UI, then checked the import dialog closed. It was green. It had been green for two runs. It was importing zero bills — a static fixture invoice already existed in the persistent dev database, so the backend returned imported=0, the dialog closed anyway, and the assertion was satisfied by a result that proved nothing happened.
The traditional SDLC has a stage whose entire job is to catch that: testing and QA. It would have waved this through, because the suite was green. A different stage caught it — and the point of this post is which stage, and why.
AI-Driven Development (ADD) is usually explained as its own eight-step loop. This post takes the inverse view: it starts from the nine SDLC stages you already run and shows, stage by stage, what AI broke inside each one and what ADD does about it. Two real systems supply the evidence throughout — scla-mono, a Next.js admin portal with a real-backend end-to-end harness, and ai-proxy (internally hydroa), a multi-tenant LLM gateway, at its v5 production milestone.
The spine: ADD doesn’t add a stage, it rewires every stage
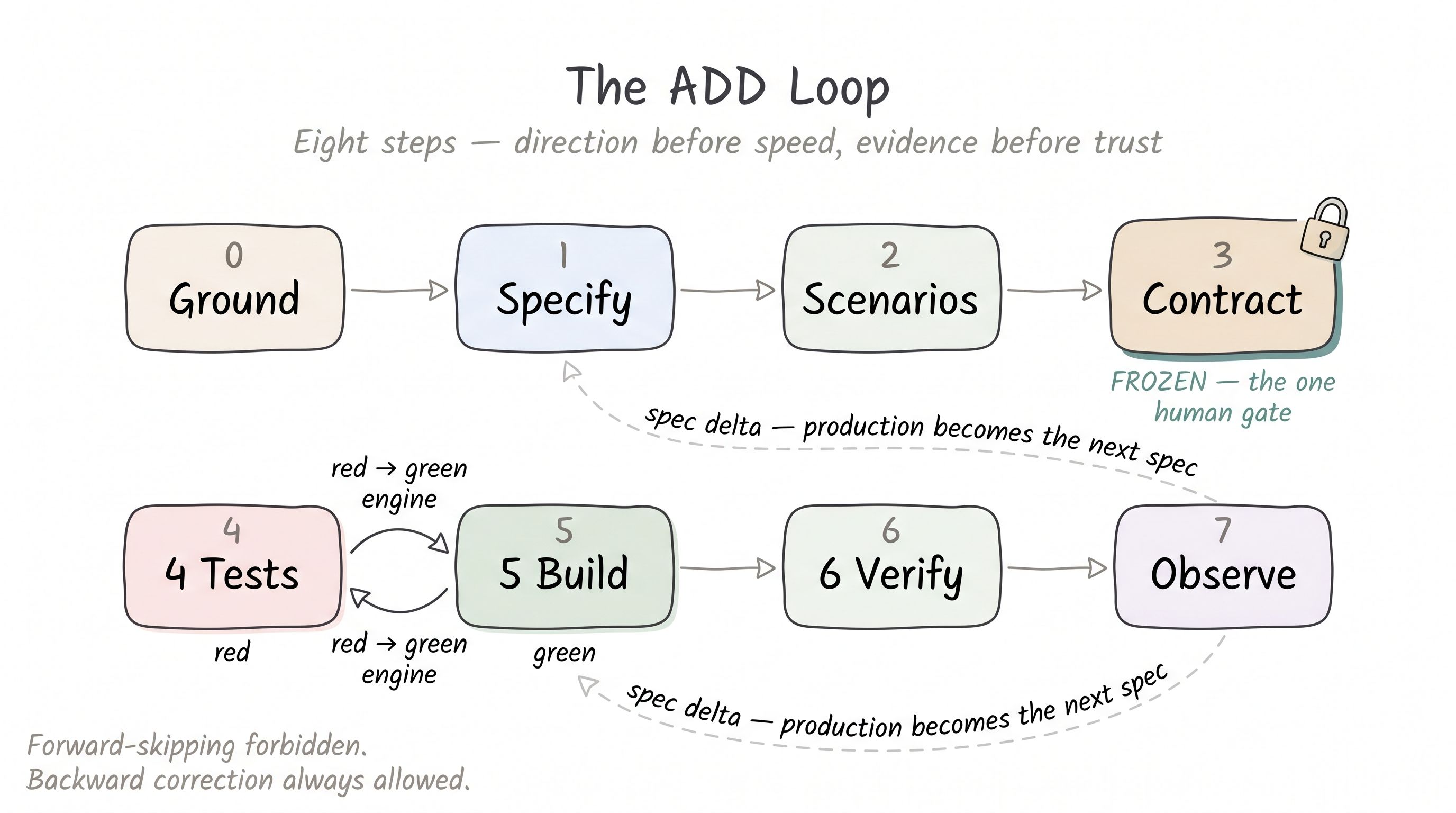
Before the map, the two structural changes that make the map make sense. ADD is not a tenth stage you bolt onto the end. It changes two things about the stages you already have.
It reorders the line. In the classic SDLC, tests come after development — QA receives a build and probes it. ADD moves the test suite before the build: you write the failing tests from the spec, confirm they are red for the right reason, and only then let the agent write code to turn them green. Development stops being the first creative act and becomes the constrained one. The definition of done exists before the thing being done.
It redefines done. In the classic SDLC, a stage completes when a human signs off — the review is approved, the checklist is empty, the ticket is closed. ADD completes a stage on evidence: a suite red for the right reason, then green; an adversarial reviewer who failed to break the green; a live run that proves the behavior through the real edge. Sign-off is replaced by receipts.

The mechanism behind both changes is one idea: clamp the what, free the how. Pin down the behavior, the interface, and the definition of done; leave the implementation entirely open. That boundary is what lets an agent run fast without running into a wall — and it is enforced differently at every stage of the lifecycle.
The eight steps that carry it are the loop below. The rest of this post maps them onto the nine stages of the SDLC you already run.
The map, in one table
| SDLC stage | What AI broke inside it | ADD's move | Step |
|---|---|---|---|
| 1 · Requirements | Agent fills ambiguity with confident guesses (fast waste) | Map the real code, then state Must/Reject/After and rank the riskiest assumption first | Ground + Specify |
| 2 · Architecture & design | Agent silently changes interfaces mid-build for 'consistency' | Freeze the contract — checksummed; the one human gate | Contract |
| 3 · Development | Wrong thing built fast; tests weakened to go green | Make every red test green; never touch a test or the contract | Build |
| 4 · Code review | Plausible-and-wrong code passes a reasonableness read | Attack the green: an independent refute-read hunts vacuous passes | Verify |
| 5 · Testing & QA | A suite that asserts nothing goes green; staging-green ≠ correct | Red-for-the-right-reason before code; verify on live evidence | Tests + Verify |
| 6 · Security review | Silent secret leaks and injection surfaces in plausible code | Security is the one outcome that can never auto-pass — always HARD-STOP | Verify |
| 7 · Release | More code shipped than verified = unreviewed risk | Release deliberately; close on an evidence bundle, not a checklist | Observe |
| 8 · Deploy & operate | Monitors drift from the intent they were meant to watch | The scenarios that drove the tests become the production monitors | Observe |
| 9 · Maintenance & iteration | Bugs become tickets; the spec never updates; incidents recur | Production signal becomes a spec delta; lessons fold into the foundation | Observe → fold |
The nine sections that follow walk each row with the real evidence behind it.
1 · Requirements & discovery — Ground, then Specify
What the stage is for: turning a need into something buildable.
What AI broke: an agent does not slow down at ambiguity. Hand it a vague requirement and it produces a confident, complete-looking result built on an assumption you never made. The requirement stage is where that fast waste is born.
ADD’s move: two steps, in order. Ground gathers the real files, symbols, and conventions the work touches — reality, not the design doc’s memory of reality. Specify then states the rules as Must / Reject (each with a named error) / After-state, and ranks its own assumptions lowest-confidence first, flagging the one or two most likely to be wrong with why and what they cost.
On scla-mono, Ground refused to trust the repo’s own docs. It found a precondition bug nobody had filed: the backend’s docker-compose.yml had no PORT env, so uvicorn bound :3000 while the compose healthcheck probed :8000 — make up --wait failed and nothing served on the host port the tests needed. That was caught before a single line of test code, and the fix was carried into the task’s own scope.
Then Specify surfaced the riskiest guess in one sentence:
Assumptions — lowest-confidence first: ⚠ Auth hydration from storageState alone — the access token is in-memory (never persisted); a spec started from the saved cookie relies on the SessionProvider's silent refresh to mint a token before the first API call. Lowest confidence: I have not observed the hydration timing in a real browser. If wrong: protected specs bounce to /admin/login or race the first call. Cost: low-med — fall back to a UI login per spec.The human reads that line first — the most-likely-wrong, most-expensive guess — and confirms or kills it before any code exists. On ai-proxy, the same discipline operates at milestone scope as an explicit In / Out boundary: semantic caching is in (as a layer over the existing exact-match cache); Presidio/NER-based PII is out (“package weight: spacy models; regex-v2 first — revisit only if a task spec proves regex insufficient”). The scope of what is drawn before the how is touched.
2 · Architecture & design — freeze the contract
What the stage is for: deciding the shapes — interfaces, data, boundaries — before building to them.
What AI broke: a human who discovers mid-build that an interface needs to change will usually raise it. An agent will sometimes just change it, because changing it makes the code consistent and the agent optimizes for consistency. Design decisions silently dissolve into the implementation.
ADD’s move: the Contract step freezes the external shape — interfaces, data structures, names, error cases — and locks it with a checksum. This is the single human decision point of the default flow. Freezing is the precondition for granting the agent real autonomy in build: once the surface cannot move, every regeneration underneath it is safe.
ai-proxy’s v5 milestone makes design-as-contract explicit at the top of the plan — freeze the risky ones first:
## Shared / risky contracts (freeze these first)- usage_records.team_id column + ledger-derived rollup shape -> team-attribution- tenants OIDC provider-config table + admin API shape -> oidc-tenant-config- JWKS failure semantics (ERR_OIDC_TOKEN_INVALID, fail-CLOSED) -> oidc-jwks- guardrail_configs JSONB extension for custom PII patterns -> pii-v2- semantic-cache key/similarity contract (tenant-scoped, opt-in)-> semantic-cacheThe riskiest interfaces are fixed before the tasks that build against them even start. scla-mono shows the other half of the boundary — clamp the what, free the how — inside a single contract. Its frozen §3 pins the observable outcomes each test must prove, but carries a green-compat selector addendum for the locators:
── OBSERVABLE OUTCOMES (FROZEN) ──prov.toggle : Enable/Disable on the row → badge text flips AND persists after reload── GREEN-COMPAT SELECTOR ADDENDUM (locator-tunable in build) ──prov : row getByRole("button",{name:"Enable"|"Disable"}) · badge getByText("Enabled"|"Disabled")The outcome is frozen; the selector is the agent’s to adjust against the live DOM. That is the design discipline exactly: the contract is the behavior, not the keystrokes.
3 · Development — Build against red tests
What the stage is for: producing the working implementation.
What AI broke: almost nothing about writing code — agents do that fluently. What breaks is the failure mode under pressure: an agent told to turn a suite green will, if allowed, weaken or delete the failing test. That inverts the entire method.
ADD’s move: Build starts only after the red suite exists, and it runs under one non-negotiable rule — make every test pass; do not change any test; do not change the contract; stop and ask if anything is unclear. Inside those walls, the how is the model’s to invent.
By the time Build began on scla-mono, the specs were already written and red. The build proceeded as ordered batches — backend precondition fix, idempotent unit seed, static .xlsx fixture, global-setup wiring, package scripts, then green twice over — and it touched only harness files. The verify record confirms the discipline held: “no test or contract was altered during build; build touched only harness files.” The contract fixed the behavior; the agent found the path. This is the reorder paying off: development is no longer the first creative act, it is the bounded one.
4 · Code review — attack the green, don’t read the diff
What the stage is for: a second pair of eyes confirming the change is correct.
What AI broke: the whole premise. Reviewing meant reading a diff and finding it reasonable — but AI code is frequently plausible and wrong, and it arrives faster than anyone can read. A reasonableness read is precisely the trap.
ADD’s move: the Verify step replaces inspection with an adversarial earned-green refute-read — an independent reviewer argues the green was not earned, hunting for code overfit to fixtures, vacuous assertions, and real logic stubbed away.
This is the stage that caught the opening story. On scla-mono, the refute-read found two vacuous greens that the passing suite had hidden:
Adversarial refute-read — 2 real defects, both FIXED by strengthening: (1) the import test false-greened on re-runs: a static invoice pre-existed on the persistent dev DB → imported=0 still closed the dialog → green. Fix: global-setup DELETEs the invoice each run; the test now asserts imported === 1 from the real POST /bills/import response. (2) the month-filter test was vacuous: a single-bill DB shows the row with or without the filter. Fix: assert a DIFFERENT month HIDES the row (count 0), then clearing restores it.Neither defect was visible in the diff — both tests read fine. They were only exposed by someone trying to prove the green was a lie. That is what code review becomes when a machine writes the code: not “does this look right,” but “show me this green was earned.”
5 · Testing & QA — red first, then live
What the stage is for: establishing the change actually works.
What AI broke: two assumptions at once. First, that a green suite means correct — an agent will happily write a test that passes vacuously. Second, that staging-green is enough — the gap between “verified in staging” and “correct in production” is wider and harder to see when an agent wrote the code.
ADD’s move: the reorder, plus a higher bar for evidence. Tests are written from scenarios before any code and must fail for the right reason — a test that passes before the implementation exists is testing nothing. And final trust comes from a live run through the real edge, not a staging smoke test.
scla-mono recorded the red gate explicitly:
RED evidence (backend down): playwright test → webServer booted, global-setupthrew "backend_unreachable", suite aborted — red for the RIGHT reason(missing impl = the booted backend via the compose fix). 9 tests discovered.The suite proved itself executable before a line of implementation. ai-proxy shows why the live bar matters: its v5 milestone close was held until live_v5_verify.py ran 24/24 twice in a row against the same long-lived stack through the real TLS edge (Envoy, https://localhost:8443) — and that live pass surfaced two production defects in the OIDC tenant-config wiring that 399 passing unit tests had waved through. The close was held until both were re-proven live. A green suite is necessary; it is never sufficient.
6 · Security review — the gate that never auto-passes
What the stage is for: ensuring the change does not introduce a vulnerability.
What AI broke: plausible code hides security defects beautifully. A raise ... from exc that carries an upstream secret on the exception’s cause reads as ordinary error handling. Under deadline, the security stage is also the one most often waved.
ADD’s move: in Verify, security is the single outcome that can never auto-resolve. Every verify ends in exactly one recorded result — PASS, RISK-ACCEPTED (a signed waiver, never for security), or HARD-STOP — and a security finding is always HARD-STOP, escalated to a human.
ai-proxy v5 carries this as a standing rule on its most dangerous data:
client_secret is encrypted at rest or write-only — NEVER returned by GET,NEVER logged (carried HARD-STOP).And it treats tenant input as hostile by construction: per-tenant custom PII patterns are validated at write time because “a tenant-supplied regex is untrusted input: ReDoS is a security surface” — re-compiled with length and complexity caps, a dangerous pattern rejected 422. Security here is not a late checklist; it is a property of the contract, enforced at the gate, that no level of autonomy is allowed to skip.
7 · Release — close on evidence, not a checklist
What the stage is for: getting the change to users.
What AI broke: when an agent produces more than a team can review, shipping on schedule means shipping unreviewed risk. A checklist can empty while a goal stays unmet.
ADD’s move: the Observe step begins at release — ship deliberately, behind a flag or a gradual rollout, and treat the milestone as open until its observable exit criteria are met, each mapped to the task that delivers it.
ai-proxy v5 reads its release as a bundle of provable claims, not a closed ticket list:
## Exit criteria (observable; map each to the task that delivers it)- [x] forged RS256 ID token → 401 ERR_OIDC_TOKEN_INVALID; valid token verified against the IdP JWKS — proven LIVE through the TLS edge- [x] a semantically similar prompt served cached=true, cost 0, tenant-scoped (a second tenant with the same prompt MISSES)- [x] two tenants authenticate via two DIFFERENT IdP configs in one deployment; GET of the config never returns client_secretThe milestone closed when the evidence existed for every criterion — verified live, twice — not when the tasks were marked done. Release is the moment the receipts are complete.
8 · Deploy & operate — scenarios become the monitors
What the stage is for: running the system and watching it in production.
What AI broke: monitoring is usually a separate artifact, written after the feature, drifting from the intent it was meant to watch. With an agent in the loop, the distance between “what we tested” and “what we alert on” only grows.
ADD’s move: reuse the scenarios from step 2 as the production monitors. The same concrete definition of “correct” that drove the tests now drives the alerts — one source of truth, from spec to dashboard.
scla-mono’s Observe section names the reuse directly:
Watch (reuse scenarios as monitors):- the auth-guard scenario (unauth /bills → /admin/login) doubles as a session-integrity monitor- the import scenario's `imported===1` assertion is a seed-integrity monitor (a 0 means the self-seed cleanup regressed)- a rising gotoAuthed retry count is an early signal the cold-load auth race is worseningNo new monitoring code was invented. The operational signals are the acceptance scenarios, pointed at live traffic.
9 · Maintenance & iteration — the loop closes here
What the stage is for: fixing what production reveals and improving the system over time.
What AI broke: the classic failure — a defect becomes a ticket, the spec is never updated, the fix is local, and the same class of bug returns next quarter. Retros are written and not read.
ADD’s move: Observe → fold. Every defect or surprise becomes a spec delta that re-enters the loop at Specify; confirmed lessons fold into the versioned foundation, tagged by competency, reusable by name; and a dynamic goal-loop reopens tasks until exit criteria are genuinely met.
scla-mono’s Observe step did far more than log a pass. It emitted competency deltas — and one of them was a real application bug the harness had merely tolerated:
[UDD] cold-load auth race — every protected hard-load silently refreshes; hydrate + the 401-interceptor fire TWO concurrent refreshes; the second reuses the single-use rotating token → theft-detection revokes all → bounce to /admin/login (~40% per protected cold load). Needs its own task: single-flight the refresh. ("Both, sequenced" — agreed follow-up.)[TDD] an e2e "green" can be vacuously earned (the import + filter findings).[ADD] the scope-walk did not prune .next build output — ~692 generated .sst files tripped a false scope_violation; fix: exclude the whole gitignored build-output class (.turbo, dist, build, coverage) next time.The auth race was promoted to its own spec → test → fix task instead of being patched in place. The testing lesson and the tooling lesson folded back so the next frontend e2e task inherits them by name. On ai-proxy, the same instinct held the v5 close open until the two live-surfaced production defects were re-proven fixed — maintenance folded back before the milestone was allowed to close. The method improved itself across loops, which is the entire point of having a ninth stage that feeds the first.
What you keep, and what you change
The reassuring part: you do not throw away your SDLC. Every stage above is one your team already runs. ADD keeps the stages and re-points two things inside them — it moves tests before code, and it swaps human sign-off for machine-checkable evidence. The gates are enforced in the pipeline, not in the agent, which is why the method does not depend on any one AI coding tool.
Walk the failures back through the nine stages and the shape is clear. Fast waste dies at Requirements, where the riskiest assumption is surfaced before the speed turns on. Silent interface drift dies at Design, where the contract is frozen and checksummed. Plausible-and-wrong dies at Review and Testing, where the green is attacked and proven live rather than read. Secret leaks die at Security, which can never auto-pass. And recurrence dies at Maintenance, where production signal becomes the next spec instead of the next ticket.
The code got cheap. Direction and verification did not — and they are distributed across every stage of the lifecycle, not concentrated in one. Clamp the what, free the how, and verify the result at each stage in turn.
If you want the method from first principles rather than the stage map, start with How AI-Driven Development Fixes the SDLC for Agent Coding, and see Where ADD Sits for how it relates to spec-kit and GSD. This guide is the translation layer between that method and the process you already have — pick one real service, run a single feature through all nine stages this way, and keep the artifacts you would be upset to lose.