For the whole history of software, writing code was the slow, expensive, central act. Every methodology we have — waterfall, agile, scrum, kanban — is, underneath, an arrangement for managing that one expensive act: how to plan it, divide it, review it, and ship it. The SDLC is a set of rituals optimized around a single assumption: typing the code is the hard part.
Then a coding agent started producing a working module in the time it takes to describe one. The marginal cost of writing a piece of code — and of re-writing it — fell close to zero.
When the cost of one activity collapses, value moves to whatever is still scarce. And most of our SDLC ceremony is now optimizing the cheap thing. This post is about the method that moves the bottleneck back where it belongs: AI-Driven Development (ADD) — five competencies and eight steps. We will walk the method end to end, and at every step ground it in a real system: ai-proxy, a multi-tenant AI gateway built entirely this way in six days.
The new failure mode: fast waste
Here is the trap that catches every team the first week they hand real work to an agent.
An AI agent is fast in whatever direction it is pointed.
If the direction is vague, the agent does not slow down and ask. It produces a confident, plausible, complete-looking result built on an assumption you never made, missing an edge case you never stated. Because it looks finished, the error survives a quick read — and surfaces later, in production, when it is expensive to fix.
Speed in the wrong direction is not progress. It is faster waste. It shows up as four specific failures of the AI-era SDLC:
- Fast waste — the agent sprints confidently past an ambiguity instead of stopping at it.
- Context rot — the model degrades over a long session, and every new session starts cold; the design lives in someone’s head, so the agent re-guesses it each time.
- Trust-by-inspection breaks down — AI code is frequently plausible and wrong. You cannot establish correctness by reading the diff and finding it reasonable.
- Verification is the real ceiling — when an agent produces more than your team can review, the excess is not speed. It is unreviewed risk, accumulating.
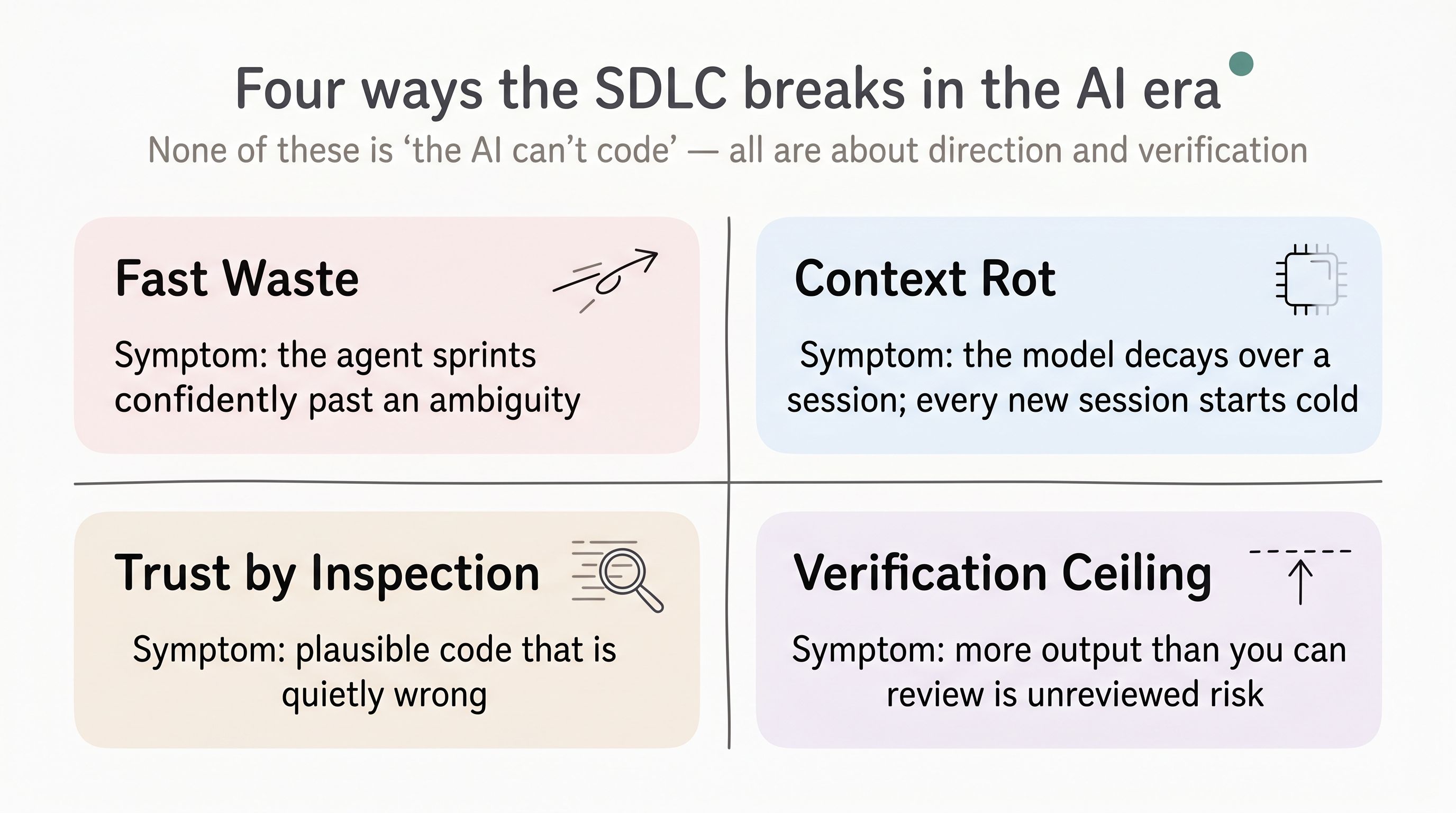
Notice that none of these is “the AI cannot write code.” It writes code fine. The failures are all about direction and verification — the two things AI cannot reliably do alone, and exactly the two things our code-centric process never made explicit, because when humans typed every line, direction and verification came bundled into the typing.
ADD’s entire thesis is to unbundle them and protect them:
Build the right thing (direction), prove it is right (verification), and let the AI do the building in between.
The reframe: constrain the what, free the how
Before the mechanics, the idea that makes the mechanics make sense.
When you hand a feature to a coding agent, you have two instincts, and both fail. Over-specify — write pseudocode and have the agent transcribe it — and you waste the model’s actual strength; you are back to typing the code, just by proxy. Under-specify — one line and a prayer — and you invite the hallucination circle of scope: given unbounded freedom over what to build, the agent fills every ambiguity with a confident guess. It invents an endpoint, assumes a currency, adds an unrequested feature. And it all looks finished.
The mistake both instincts share is treating “freedom” as one dial. It is two. There is freedom over the what — the behavior, the interface, the definition of done — and freedom over the how — the data structures, the algorithm, the internal design. The art is to clamp the first and open the second.
ADD draws a tight boundary around the what:
- the spec — Must do, must Reject (each with a named error code), the After-state;
- the frozen contract — the interface, data shapes, and error codes, locked and checksummed;
- the red test suite — the executable definition of done.
And it deliberately leaves the how wide open. The build instruction is “make every test pass; do not change the tests or the contract” — and it says nothing about implementation. Crucially, the tests assert observable behavior, not internals, precisely so the code underneath can be thrown away and regenerated freely. That open field is where the model gets to be good.

It helps to see this against the two things it is not.
| Traditional SDLC | Vibe-prompting an agent | AI-Driven Development | |
|---|---|---|---|
| Who writes the code | Humans, line by line | The agent, from a vague prompt | The agent, against fixed tests |
| Source of truth | The code itself | Whatever is in the chat right now | Spec + frozen contract + tests |
| Freedom over the WHAT | Bounded by slow human typing | Unbounded — scope hallucinates | Clamped: spec, contract, red tests |
| Freedom over the HOW | Bounded by the same typing | Unbounded and unverified | Wide open — internals are disposable |
| How correctness is shown | Reading the diff (plausible) | It looks done | Passing tests + adversarial verify |
| Dominant failure | Slow delivery | Fast waste, silent wrongness | Bounded by your verify capacity |
The middle column is where most teams are stuck today: maximum speed, maximum risk. ADD is the rightmost column — and the rest of this post is how it is built.
Five competencies: the foundation and the engine
ADD organizes the work into five disciplines, and the order of the layers is the whole point. Three are a human-led foundation the agent stands on; two are the engine where the work happens.
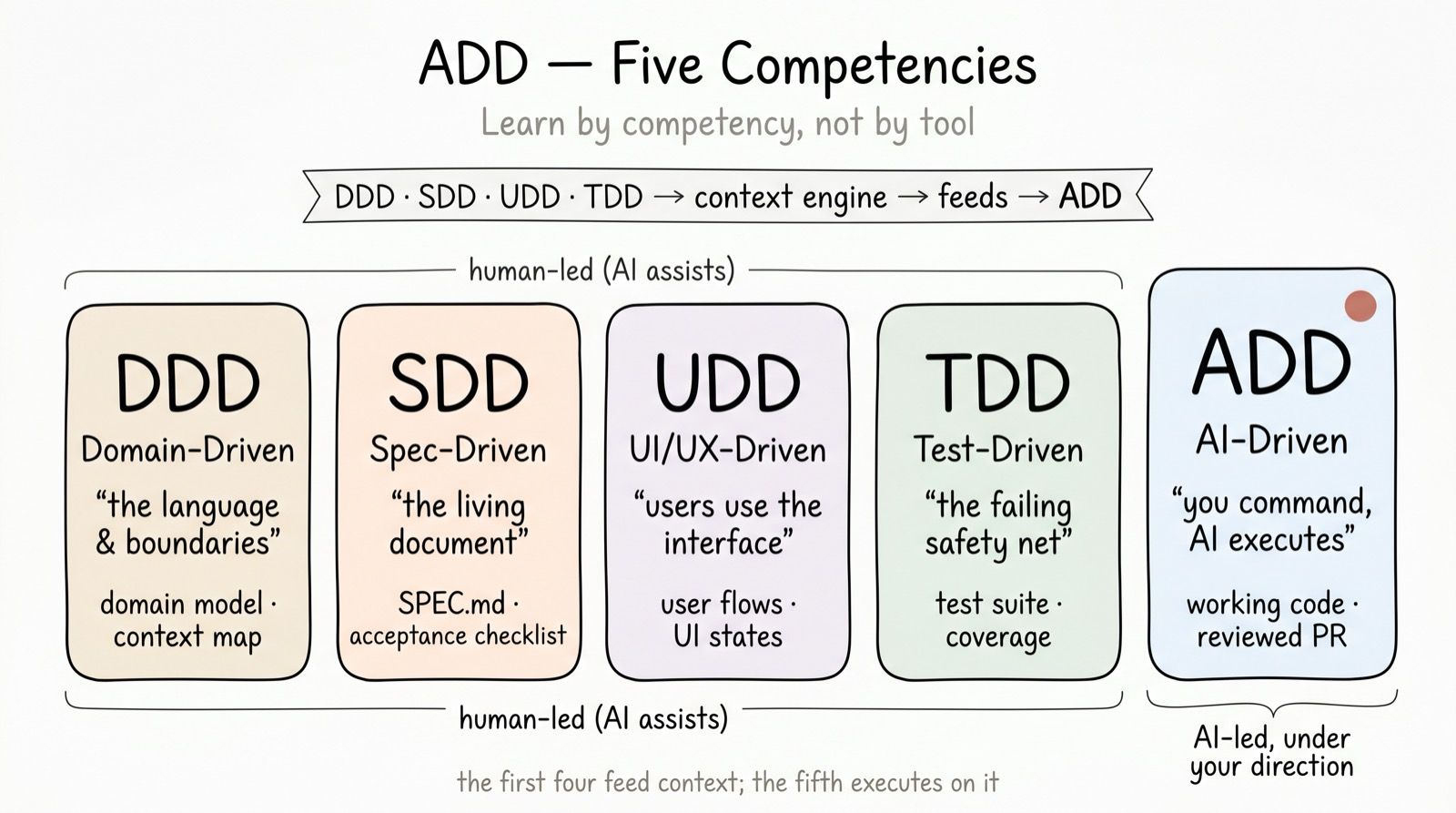
The foundation — the context the agent stands on:
- DDD — Domain. The shared, precise language and the boundaries it lives in: the core concepts, the contexts they belong to, and the invariants that must always hold. One name per concept — the same name the spec, the contract, the tests, and the code all use.
- SDD — Spec. The living document of what is being built right now, and what is settled versus still open. Not a frozen plan signed once — a layer that changes as the loop learns.
- UDD — UI/UX. Users use the interface, not the spec. The user flows, the states every screen must handle (loading, empty, error, success), and a design source of truth. The AI can generate a prototype; a person owns the empathy.
The engine — where the work happens:
- TDD ⇄ ADD. The tight red/green loop: write the failing test, let the AI generate code until it is green, repeat.
The crucial relationship is directional: the first four feed context up to the fifth, where the AI executes. An engine needs something to stand on. Every loop quietly assumes context that no single task owns — what the words mean, what we are building, how users experience it. When that context lives only in a person’s head, the agent fills the gap with plausible guesses (there is fast waste again). The foundation is what kills context rot: ADD writes all of it into one living PROJECT.md, kept short, that the engine reads first every session. State lives on disk, not in the chat — so you close your laptop, come back tomorrow, and the agent re-orients instantly instead of re-guessing.
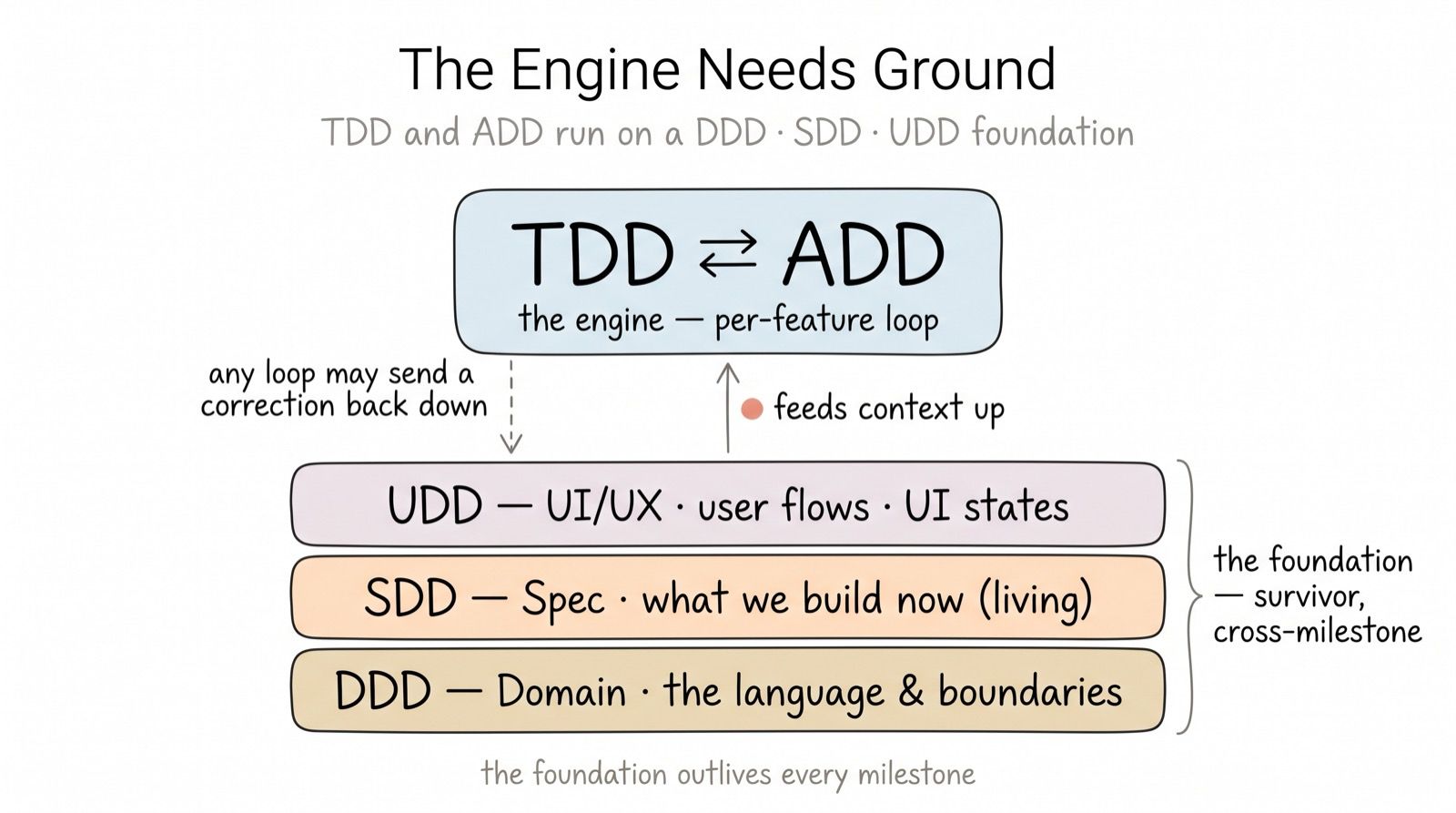
Eight steps: direction before speed, evidence before trust
The engine itself is one repeatable flow. Six steps build a feature, a seventh feeds production reality back in, and a step-0 preamble grounds the whole thing in the code as it actually is.
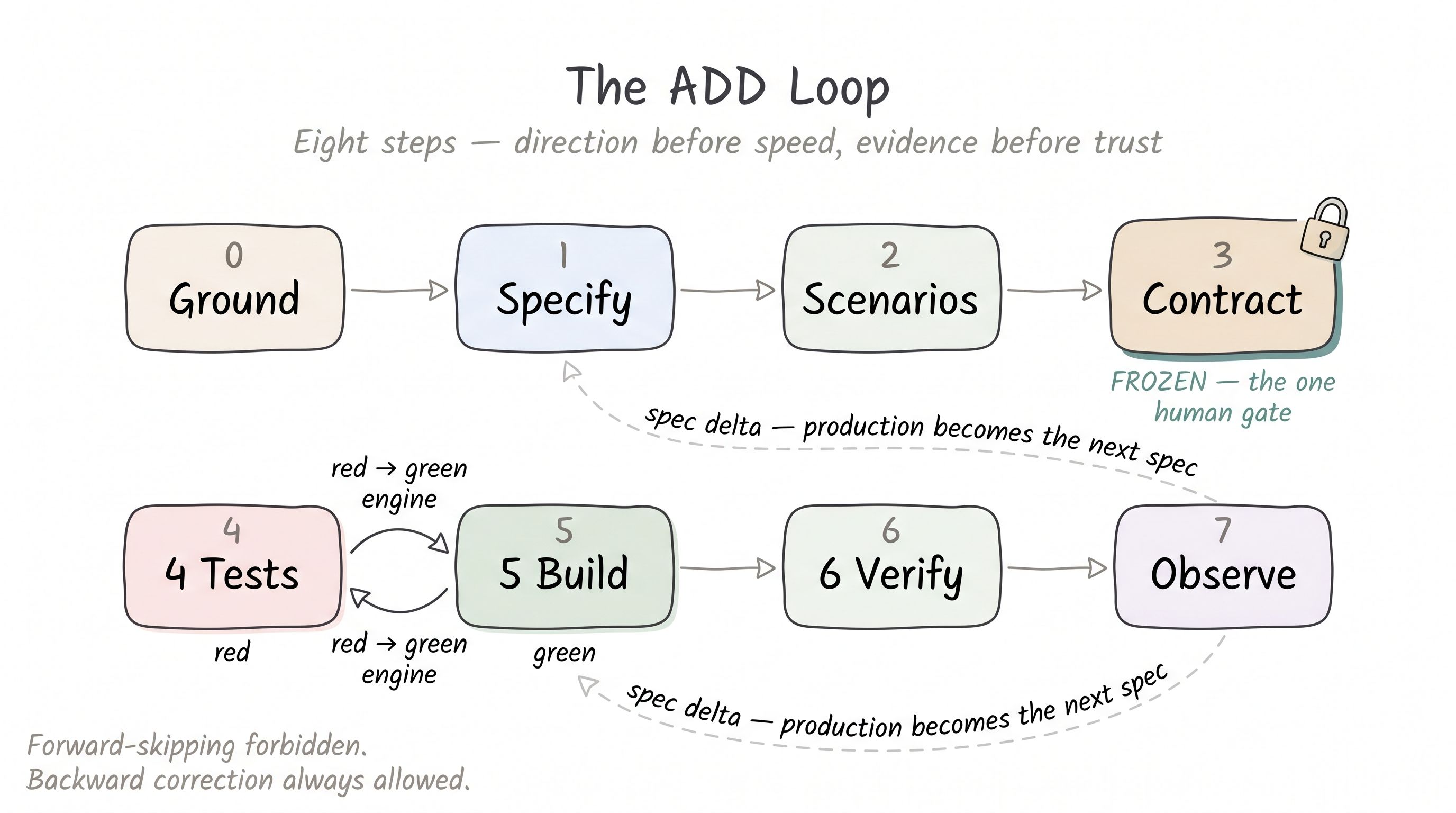
| # | Step | Produces | Resolves which AI-era failure |
|---|---|---|---|
| 0 | Ground | a map of the real files, symbols, and conventions the task touches | aims the spec at reality, not assumption |
| 1 | Specify | the rules the feature must obey, lowest-confidence assumption flagged first | kills fast waste — the ambiguity is surfaced, not sprinted past |
| 2 | Scenarios | the rules as pass/fail cases (Given/When/Then) | makes “correct” concrete before any code |
| 3 | Contract | the frozen data + interface shape | the one human decision point — the agent never freezes the interface it then builds against |
| 4 | Tests | a failing-first (red) suite | proves the contract is executable before a line of code exists |
| 5 | Build | the code, until every test is green | the AI runs fast and safe because everything it needs is already fixed |
| 6 | Verify | a recorded outcome (PASS / RISK-ACCEPTED / HARD-STOP) | replaces trust-by-inspection with trust-by-evidence |
| 7 | Observe | a spec delta + lessons learned | turns production signal into the next Specify |
Two rules govern movement, and they never conflict. Forward-skipping is forbidden: you never start a step before its input artifact exists — skip forward and the AI builds against a guess. Backward correction is always allowed: any step may send you back to repair an earlier artifact. A Build that exposes a missing rule sends you back to Specify — and that is the method working, not failing.
Let me walk each step, and ground every one in ai-proxy — the production gateway I will introduce properly in a moment.
0 · Ground
Before specifying anything, the agent gathers the actual current code the task touches — real files, symbols, signatures, conventions — into a lean grounding map. This aims everything downstream at reality instead of assumption.
It earns its place immediately. When ai-proxy started its UI redesign milestone, the foundation documents described a design system as if it existed. Ground reported the truth: shadcn/ui was not installed, there were no design tokens (globals.css was literally one line), and the “dark-mode-first” goal was aspirational — zero dark: variants in the codebase. The spec was re-aimed at what was real before a single component was written.
1 · Specify
The agent drafts the rules in plain language — what the feature Must do, what it must Reject (each paired with a named error code), and the After-state once it succeeds — then ranks its own assumptions lowest-confidence first, flagging the one or two things most likely to be wrong with why and what it costs if wrong.
# SPEC.md — bedrock-sigv4-authMust: - sign_request produces the EXACT AWS SigV4 Authorization header for a given (method, url, body, service, region, credentials, timestamp), matching AWS's published known-answer vectors byte-for-byte. - the secret access key NEVER appears in returned headers, logs, or repr/str.Reject: - missing region or credentials -> provider absent (returns None)Assumptions — lowest-confidence first: ⚠ canonical-request edge rules (URI-encoding the path, the empty-payload SHA-256 sentinel, header trimming) are easy to get subtly wrong.The human reads that flagged line first — the one most likely to be wrong and most expensive if it is — and confirms or corrects it. The single riskiest guess is killed in one sentence, before any code exists. In ai-proxy, this is where a glossary rule of “argon2 for all keys” collided with the 50–200 ms it would add to the hot auth path — caught at spec time, fixed at zero cost, because no code existed yet.
2 · Scenarios
Each rule from the spec becomes one concrete, pass-or-fail scenario — Given a situation, When an action, Then an observable result (and, for rejections, what must not change). Scenarios are readable by people and checkable by machines at the same time; they are the bridge between the human-led and machine-led halves of the flow.
Scenario: SV1 — AWS canonical vector Given the AWS published creds, region us-east-1, a fixed timestamp When sign_request signs the documented canonical request Then the Authorization header equals AWS's expected signature byte-for-byte
Scenario: SV5 — the secret never leaks Given any credentials When sign_request returns and the credentials are repr'd Then the secret substring appears in NEITHER the headers NOR the repr3 · Contract — the one human gate
This is the single human decision point of the whole method in its default flow. The agent drafts the spec, scenarios, contract, and failing tests as one bundle; the human gives one approval at the contract freeze. Freezing fixes the external shape — interfaces, data structures, names, error cases — and it is the precondition for granting the agent real autonomy in build. Without it, every regeneration risks silently changing an interface another part of the system relies on.
sign_request(*, method, url, body, service, region, credentials, timestamp) -> { "x-amz-date", "x-amz-content-sha256", "Authorization": "AWS4-HMAC-SHA256 ..." } # PURE · TOTAL · DETERMINISTIC (timestamp injected, no IO, no globals)AwsCredentials(access_key_id, secret_access_key) # secret_access_key: repr=FalseStatus: FROZEN @ v1Once frozen, the contract does not change casually. A needed change is a change request: return to Specify, adjust, re-freeze at a new version. In ai-proxy this freeze is mechanically enforced — an md5 tripwire over the frozen body means that even editing a pseudocode comment after the snapshot trips the alarm. The agent never alters a frozen contract on its own initiative.
4 · Tests
The agent generates the suite from the scenarios and contract — then runs it, and it must fail, because no implementation exists yet. A test that passes before any code is written is testing nothing; it is a false reassurance that will later wave bad code through. Confirming the suite is “red for the right reason” is what makes it genuinely protective.
This discipline catches bugs in the tests before they can mislead the build. In ai-proxy, the agent repeatedly found and fixed its own test bugs at this gate — for example an assertion reading .status_code on an error that only exposed .status, which would have produced a red-for-the-wrong-reason at build time. Strengthen the front; never weaken it.
5 · Build
Now, and only now, the agent writes code — to make every failing test pass, under one non-negotiable rule.
Implement the feature so that EVERY test passes. - Do NOT change any test. - Do NOT change the contract. - Stop and ask if any requirement is unclear — do not guess.This inverts the usual agent failure mode. An agent under pressure to turn a suite green will, if allowed, weaken or delete the failing test. That must be forbidden absolutely: a test changed to fit the code inverts the entire method. Inside these fixed walls, the how is the model’s to invent — and this is exactly where it shines. For ai-proxy’s JSON-mode feature, nobody prescribed the implementation; the agent reused an existing tool-coercion mechanism wholesale — a synthetic tool whose output is unwrapped back into message content — rather than writing a parallel translation layer. The contract fixed the behavior; the model found the elegant path.
6 · Verify — trust by evidence, not inspection
Trust is established here, and not by reading the diff and finding it plausible (that is the exact trap). It is established by evidence plus a check of the things tests cannot catch: concurrency and timing, security, architecture conformance. Then the adversarial move that defines ADD — an earned-green refute-read: an independent reviewer argues the green was not earned, hunting for code overfit to fixtures, vacuous assertions, or real logic stubbed away. Every verify ends in exactly one recorded outcome — PASS, RISK-ACCEPTED (a signed waiver, never for security), or HARD-STOP. There are no silent skips.
This is the step that turns the thesis into receipts. On the very SigV4 feature above, every original test used the path / (the canonical AWS vector), and the implementation passed clean. The refute-read added a test using a real Bedrock model ID containing a colon (...sonnet-20241022-v1:0). AWS canonicalizes : to %3A; the signer was passing the raw path. The new test went red against the “green” code. Every versioned-model call would have returned 403 in production. A green suite of seven tests would have shipped it.
7 · Observe — production becomes the next spec
Release deliberately — behind a flag or a gradual rollout — and reuse the scenarios from step 2 as monitors: the same definition of “correct” that drove the tests now drives the alerts. Every defect, surprise, or new need becomes a spec delta that re-enters the flow at step 1. And confirmed lessons fold back into the versioned foundation, tagged by competency, so later milestones reuse proven patterns by name instead of re-deriving them.
In ai-proxy, Observe noticed a recurring boot failure (an empty provider key producing a client-side protocol error) across milestones and promoted the pattern to a formal spec → test → fix task with a boot guard. The method improved itself across loops.
Proof: a 23-milestone gateway, built this way
The SigV4 story is one thread; here is the cloth. ai-proxy is a LiteLLM-class multi-tenant AI gateway — six upstream providers, an OpenAI-compatible /v1 surface, metering and billing, budgets, key governance, a load-balancing router, caching, SSO/OIDC, and an enterprise dashboard. It was built end to end through ADD: 23 versioned milestones, roughly 120 tasks, six days, zero risk-waivers, graduated to production. Its foundation carries an append-only log of 140+ decisions — the method’s own audit trail. (The full field notes live in the project’s DEVLOG-add-retro.md.)
Three findings stand out, because each is a failure mode above turning into evidence.
Green suites shipped clean while hiding real defects. A live end-to-end run caught a defect that 326 passing tests missed — a PII marker silently never recorded. A later milestone’s live pass caught two production-dead code paths that 399 passing tests waved through. That is “trust-by-inspection breaks down,” measured rather than asserted — and exactly why ADD makes live verification and the refute-read load-bearing on top of the suite. The refute-read alone also caught a coverage regression a --no-coverage run had hidden, and a fail-open identity bypass where a followed redirect could chain to a trusted response.
Security stopped hard, every time. An independent security subagent found that a raise ... from exc would carry an upstream client_secret on the exception’s __cause__ — invisible today, harvested by any future crash reporter. The author’s own refute-read had missed it. It escalated as a HARD-STOP, became its own remediation task, then generalized into a project-wide sweep — 13 secret-bearing error paths hardened across every provider adapter. No security finding was ever auto-passed.
The foundation compounded. A 600-plus-line conventions document accumulated lessons that could not have been written up front — split-stream parsing rules, live-harness pacing under rate limits, realistic-input testing for protocol signers. Later milestones went faster because earlier ones folded what they learned. Two whole milestones existed only to pay down tracked debt, on the record.
And the agent’s behavior changed with the method: it surfaced its least-confident assumption and asked before building, froze the contract and then refused to touch it, attacked its own green with a refute-read and an independent security subagent, escalated every security finding to a human, and treated a passing suite as necessary but never sufficient.
Living documents: the rot old-school methods hide
Every old-school methodology produces documents, and every one shares the same fate: each is true the day it is signed and a little less true every day after. The PRD, the architecture decision record, the onboarding wiki — they describe the system as someone once imagined it, not as it is now. The gap stays invisible until it bites: a new engineer builds on a design doc that no longer matches the code; a settled decision gets re-litigated because nobody remembers why it was made; a “done” feature quietly drifts from its spec.
ADD’s answer is not “write better docs” — discipline always loses to deadlines. It is to make a small set of documents living, kept current by the loop itself rather than by anyone’s good intentions. Here is the contrast, drawn from ai-proxy’s six days.
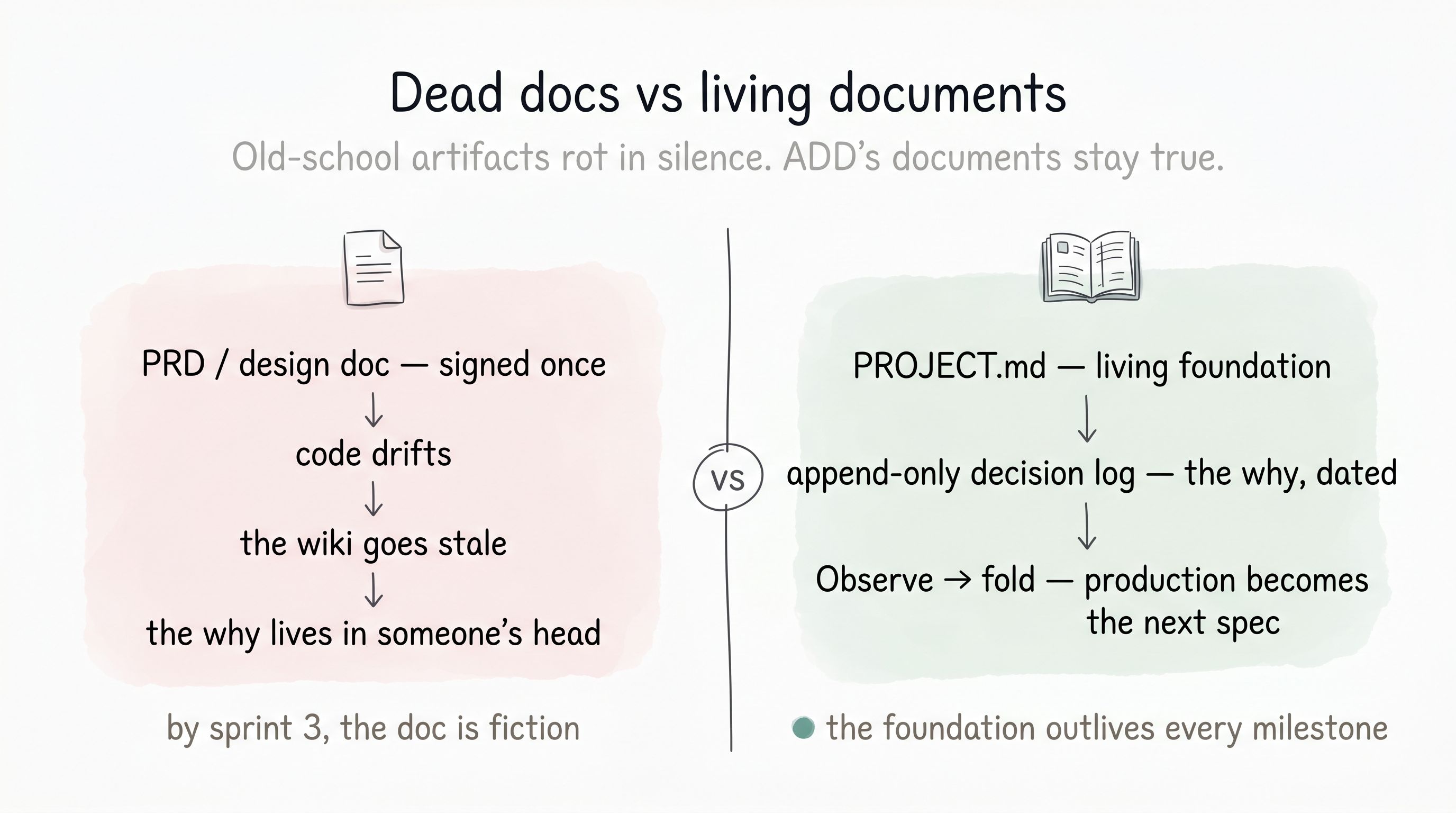
The same contrast, point by point:
| Old-school artifact | ADD living document | |
|---|---|---|
| Requirements / spec | A PRD signed once; the code quietly drifts away from it | SDD — a living spec; production signal returns as a spec delta at Specify |
| Design / architecture | A diagram of the system as imagined, not as built | Ground re-checks the docs against the real code every task |
| The 'why' of a decision | Buried in a chat thread or a former teammate's memory | An append-only, dated decision log — 140+ entries on ai-proxy |
| Lessons learned | A retro nobody reads twice | Folded into CONVENTIONS.md, tagged, reused by name next milestone |
| Onboarding | Read the stale wiki, then ask around | The foundation is the onboarding; a cold session re-orients itself |
| Spotting decay | Invisible — looks authoritative until it misleads you | Worn on the sleeve: settled vs open, FROZEN at a version, dated, append-only |
Three scenarios from the build make it concrete.
The design doc that lied. When ai-proxy reached its dashboard redesign, the foundation documents described a design system — shadcn/ui, design tokens, a dark-mode-first theme — as if it were already there. None of it was; globals.css was a single line. In an old-school flow, that doc is read as truth and a sprint is built on a system that does not exist. ADD’s Ground step checked the doc against the actual code, caught the gap, and the spec was re-aimed at reality before a component was written.
The decision nobody could explain. Why argon2 and not SHA-256 for API keys? Why does the dashboard now verify a session token it once trusted? On most teams those answers live in a closed thread or a former teammate’s head, and six months later someone reverts the change and reintroduces the bug. On ai-proxy each is an append-only, dated entry in a 140-plus-decision log — so a cold session, or a new teammate, re-orients instead of re-guessing.
The spec production rewrote. A recurring boot failure — an empty provider key producing a client-side error — kept resurfacing across milestones. Old-school, that becomes a ticket, the spec is never updated, and the incident recurs. In ADD, Observe turned the pattern into a spec delta that re-entered at Specify as a dedicated boot-guard task, and the lesson folded into CONVENTIONS.md so later milestones inherited it by name.
The deeper value is transparency. Old-school documents hide their own decay — they look authoritative right up to the moment they mislead you. ADD’s documents wear their state on their sleeve: the spec marks what is settled versus still open, the contract is stamped FROZEN at a version, the decision log is append-only and dated, and the conventions file grows a tagged entry every time the loop learns. You can always see what is true, what changed, and why — which is exactly what a binder of signed-once documents can never tell you.
Where it sits: ADD vs spec-kit vs GSD
ADD did not appear from nowhere. It is spec-driven development and tests-first discipline pointed at agent coding, and it has close siblings. GitHub’s spec-kit runs constitution → specify → plan → tasks → implement, treating the specification as the executable source of truth — its own launch framed task decomposition as “TDD for your AI agent.” GSD is a spec-driven, context-engineering system for the same Claude-Code niche, organizing work into phases and milestones with a planning document per phase. Both are real, both are good, and ADD inherits from both. The honest comparison is not “better” but “where each one stops.”
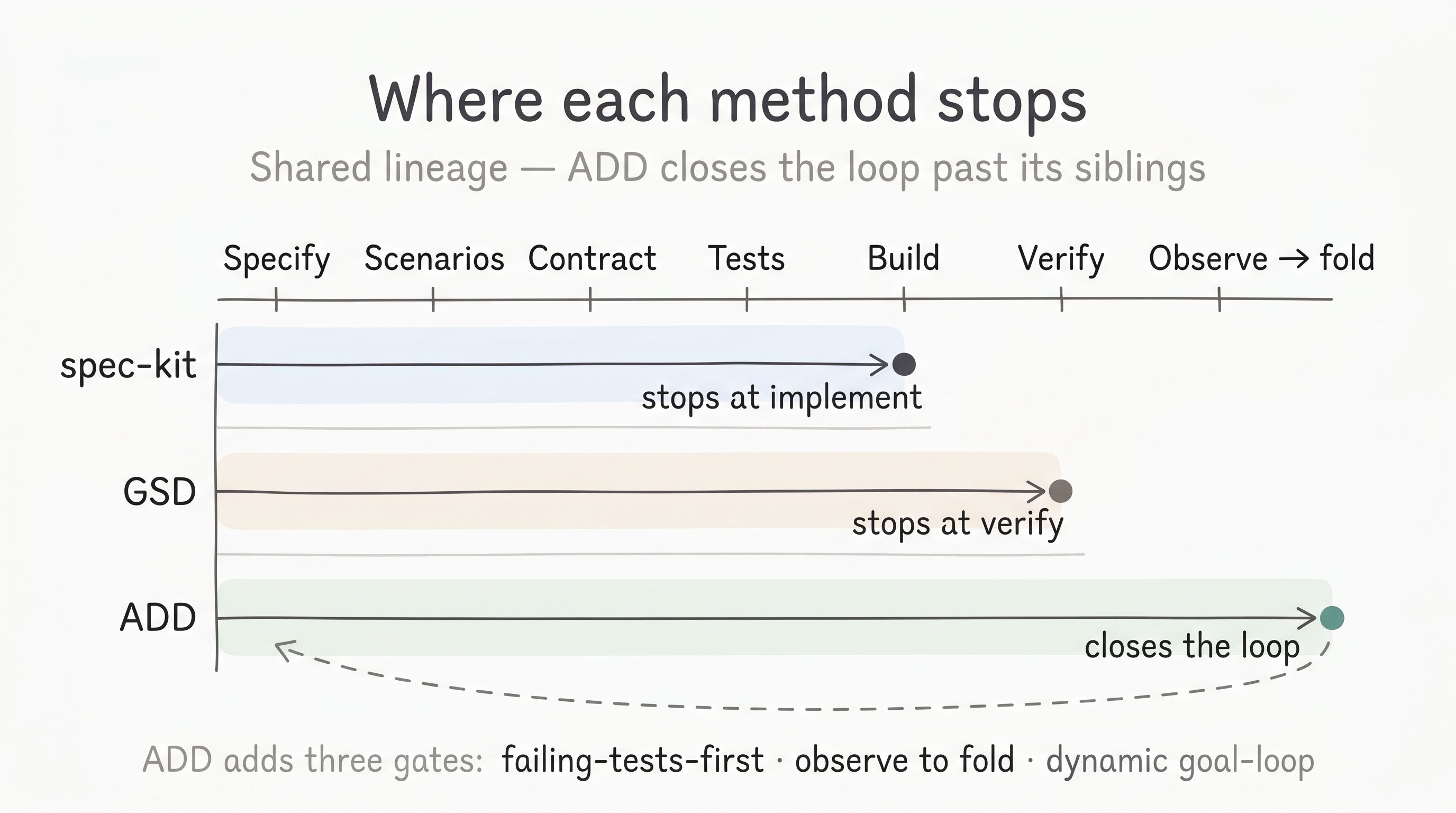
| spec-kit | GSD | ADD | |
|---|---|---|---|
| Core idea | Spec as executable source of truth | Spec-driven, context-engineering by phase | Spec + frozen contract + tests, agent-built |
| Workflow | constitution → specify → plan → tasks → implement | Phase/milestone plans, then build & verify | Ground → Specify → Scenarios → Contract → Tests → Build → Verify → Observe |
| Where it stops | At implement | At verify | Past verify — Observe folds back in |
| Failing-tests-first gate | Not a first-class gate | Not a first-class gate | Yes — no build until tests are red for the right reason |
| Self-improvement loop | — | — | Observe → fold: lessons consolidate into a versioned foundation |
| Definition of done | Tasks implemented | Checklist complete | Exit criteria met (dynamic goal-loop reopens tasks) |
| Doc overhead | Moderate | Higher (a document per phase) | Lean (one human approval per task) |
So ADD’s distinctive contribution is three gates neither sibling carries as first-class:
- a failing-tests-first gate — no build starts until the tests are red for the right reason, so the contract is proven executable before any code exists;
- an observe → fold step — confirmed lessons consolidate back into a versioned foundation, so the method improves itself across loops;
- a dynamic goal-loop — the engine holds a milestone open and reopens tasks until its exit criteria are met, rather than declaring done when a checklist empties.
Everything beneath those gates is inherited from the lineage. ADD’s claim is narrow and specific: it is the part that closes the loop and earns the trust.
Why this actually fixes the AI-era SDLC
Walk the four failures back through the method:
- Fast waste dies at Specify and the frozen Contract. The agent’s ambiguity is surfaced and confirmed before the speed turns on — direction before acceleration, every time.
- Context rot dies at the foundation. The durable context lives in
PROJECT.mdand on disk, not in a chat window that decays. A new session re-orients instead of re-guessing. - Trust-by-inspection dies at the red-tests gate and Verify. A feature is trusted because its tests pass and its non-functional risks were checked — not because the code reads plausibly. The artifacts are the durable asset; the code is one disposable implementation that satisfies them.
- The verification ceiling is respected and raised. You cannot move faster than you can verify — but a passing suite, a contract check, and an adversarial verifier are all verification, and they scale in a way human reading never will. Verify can auto-gate on complete evidence, while security always stops for a human. Autonomy is earned by more verification, not by a lower bar.
The agentic loop already runs — by 2026, more than 80% of the code merged at Anthropic was Claude-authored. What the loop does not supply on its own is the discipline to trust the output. That is the whole job now, and it is harder than typing ever was: turning a fuzzy need into a buildable definition, and proving the result correct through evidence.
The code got cheap. Direction and verification did not. Clamp the what, free the how, and verify the result — build the right thing, prove it is right, and let the AI do the building in between.