A method you cannot place is a method you cannot trust. ADD draws from a long tradition, and naming that tradition precisely — what it borrows, what it re-points, and where it departs — is the thing that lets you hold it with confidence rather than accept it on faith. This is the final part of the series, and its job is to situate ADD among its intellectual predecessors and its closest living neighbors.
The lineage ADD inherits
ADD did not appear from nowhere. It sits where four long currents meet, and each leaves a specific imprint on the method.
TDD — the executable definition of done
Test-Driven Development gave us the most important idea in the entire lineage: the test is the definition of done, written before the code. The red/green discipline is exactly what ADD’s engine inherits. A feature in ADD is not done because it looks reasonable or because the diff reads cleanly — it is done when a suite of failing tests, written from scenarios before a single line of implementation exists, turns green. The “never weaken a test” rule is TDD’s constraint transported whole into the agentic context, and it matters more there, not less: an agent under pressure to turn a suite green will delete the obstacle if you let it. TDD’s discipline is what keeps the gate honest.
What ADD changes: TDD’s red tests were classically written by the same human who would implement the feature. In ADD the tests remain human-authored (or human-reviewed), but the implementation is the agent’s. That separation — human direction through tests, agent execution against them — is what makes the discipline productive at AI speed rather than merely ceremonial.
DDD — the shared language and the bounded map
Domain-Driven Design contributed two things ADD relies on every step of the way. The first is ubiquitous language — the discipline of using one precise name per concept, held consistently from the domain conversation through the spec, the contract, the tests, and the code. In ADD this is Step 0 (Ground) and the foundation layer: the glossary and the bounded contexts live in PROJECT.md, kept short, so that every new session re-orients against the same vocabulary rather than re-guessing it. The second DDD contribution is bounded contexts — the idea that a system is carved into regions, each with its own consistent model of the world. ADD’s contracts sit exactly at context boundaries: they name the interface where one region meets another, and they are frozen precisely because that boundary is where assumptions become load-bearing.
What ADD changes: DDD was designed for human teams reasoning about a complex domain over months. ADD collapses the timescale and makes the foundation executable: the glossary feeds directly into the spec prompt, the bounded context drives the contract surface, and the tests assert the invariants the domain declared. The language stays human; the enforcement becomes mechanical.
BDD — scenarios in domain language
Behavior-Driven Development gave ADD its Scenarios step almost intact. BDD’s Given/When/Then structure is the bridge between a human-readable rule and a machine-executable test. In ADD, Step 2 translates every Must and every Reject from the spec into a concrete pass/fail scenario in domain language — the same language the spec and the contract use — before a test file exists. The scenarios from ai-proxy’s SigV4 feature (SV1 verifying the AWS canonical vector byte-for-byte; SV5 asserting the secret never appears in headers or repr) are directly in this tradition. They are readable by a domain expert and checkable by a test runner at the same time.
What ADD changes: BDD classically assumed scenarios would drive acceptance tests written by QA or by the developer. In ADD the scenarios drive a red suite that the agent must make green — and they survive as the monitor definitions when the feature reaches Step 7 (Observe). The same concrete definition of “correct” that drove the tests now drives the production alerts.
Contract-first and API-first design
The frozen-contract step is ADD’s most direct debt to contract-first and API-first traditions. Both disciplines say the same thing: agree on the interface before building to it, because the interface is the hardest thing to change later. ADD takes this further in one specific direction: the contract is not just agreed, it is checksummed and locked — an md5 tripwire over the frozen body means even a comment edit trips the alarm. The agent that builds against it cannot silently change the surface it was given to implement.
This matters especially with an AI builder. A human developer who discovers mid-implementation that the interface needs to change will typically raise it with the team. An agent will sometimes just change it, because changing it makes the code consistent and the agent is optimizing for consistency. The frozen contract removes that option: the interface is a constraint the agent cannot cross, not a suggestion it can revise.
Literate and spec-driven traditions
The oldest thread is the one Knuth named: the idea that the specification, not the code, is the primary artifact. Spec-driven development in the AI era recovers this claim with sharper urgency: because a model can generate plausible code from almost any prompt, the cost of writing code approaches zero, and the value moves to the artifact that tells you what the code is supposed to do. ADD’s living spec (SDD), the append-only decision log, and the conventions file that grows a tagged entry every time the loop learns — these are the literate-programming tradition’s documents, but made active: the spec feeds directly into tests, the decision log is the onboarding document, and the conventions file is reused by name in the next milestone’s Ground prompt.
The code is the disposable output; the specification artifacts are the asset. The whole lineage, underneath ADD’s particular method, is trying to say this one thing.
The neighbors — where each method stops
Two living neighbors share most of ADD’s DNA. Understanding where each one ends is more useful than comparing them abstractly.
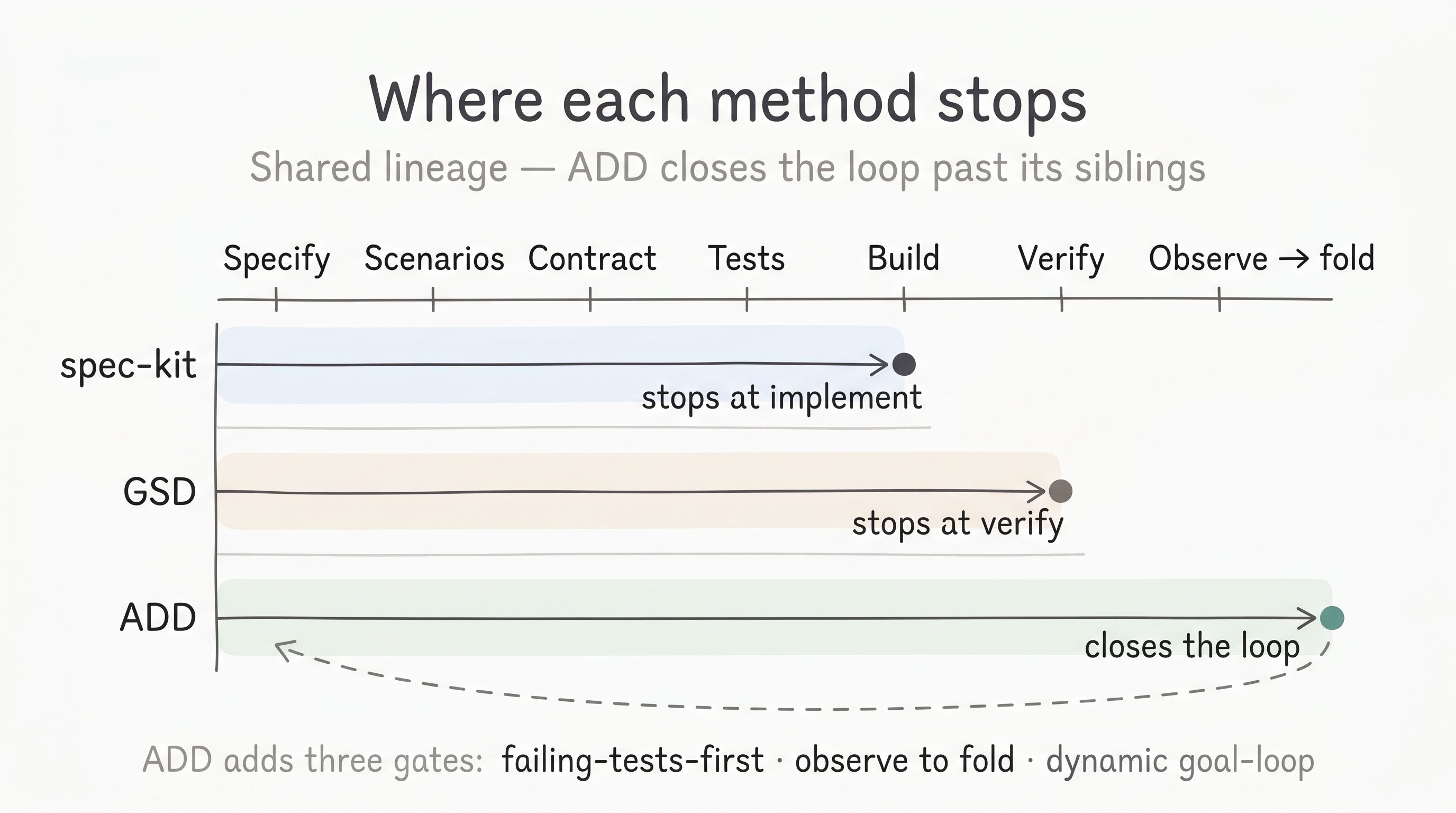
GitHub’s spec-kit runs constitution → specify → plan → tasks → implement. It treats the specification as the executable source of truth and its launch framing — task decomposition as “TDD for your AI agent” — is exactly the tradition above. It is a clean, well-grounded method. Where it stops: at implement. Once the tasks are built, the method’s job is done.
GSD is a spec-driven, context-engineering system built for the same Claude Code niche. It runs discuss → plan → execute → verify (with a fifth ship phase in GSD Core), runs each phase in a fresh subagent context to fight context rot, and produces a planning document per phase. It goes further than spec-kit by including a Verify step — a genuine walk of what was built, with fixes before declaring done. Where it stops: at verify.
| spec-kit | GSD | ADD | |
|---|---|---|---|
| Closest description | Spec as executable source of truth | Spec-driven, context-engineering by phase | Spec + frozen contract + tests, agent-built, loop closed |
| Phase model | constitution → specify → plan → tasks → implement | discuss → plan → execute → verify → ship | Ground → Specify → Scenarios → Contract → Tests → Build → Verify → Observe |
| Where it stops | At implement | At verify | Past verify — Observe folds production signal back in |
| Failing-tests-first gate | Not a first-class gate | Not a first-class gate | Yes — no build until tests are red for the right reason |
| Frozen contract | plan.md and contracts (not checksummed) | Not explicit | Checksummed; agent cannot alter it unilaterally |
| Self-improvement loop | — | — | Observe → fold: lessons consolidate into a versioned foundation |
| Doc overhead | Moderate | Higher — a document per phase | Lean — one human approval per task |
| Definition of done | Tasks implemented | Checklist complete | Exit criteria met — goal-loop reopens tasks until they are |
The fair reading is not “better” but “where each stops and what that costs when an agent writes the code.” With a human developer, stopping at implement is often fine: the developer runs the code, notices it is wrong, and fixes it. The feedback loop is immediate and cheap. With an agent, the gap between “the tasks are built” and “the result is correct” is wider and harder to see. The agent’s output looks plausible; it often passes the tests it wrote for itself. Stopping at implement leaves that gap unexamined.
GSD’s verify step closes much of that gap. Walking what was built, with fixes before declaring done, is real quality control. What it does not provide — and what ADD adds — is a mechanism for production reality to re-enter the method. A feature that verifies cleanly in staging can still surface a new edge case or an unspoken assumption in the first week of real traffic. Without Observe and the fold step, that signal lives in a ticket, the spec is never updated, and the incident recurs in the next milestone.
What is genuinely new in ADD
The lineage is real, and the neighbors are good. What ADD adds — specifically, as first-class gates neither sibling carries — is three things:
The failing-tests-first gate. No build starts until the tests are red for the right reason. This sounds like basic TDD discipline, and it is — but it requires explicit enforcement with an AI builder, because an agent will sometimes write a test that passes vacuously, against code that does not exist yet, and report it as green. Confirming the suite is “red for the right reason” before the build begins is what makes the later green meaningful. In ai-proxy, this gate caught test bugs that would have produced red-for-the-wrong-reason at build time — the entire discipline of the suite depends on this check holding.
Observe and fold. After every feature ships, production behavior re-enters the method. Confirmed learnings consolidate back into the versioned foundation — tagged, dated, reusable by name in the next milestone’s Ground prompt. This is the recursive self-improvement current turned inward on the method itself: the way ai-proxy converted a recurring boot-failure pattern into a formal spec → test → fix task, then generalized it into a boot guard that every later milestone inherited. The method improved itself across loops. Neither spec-kit nor GSD has a mechanism for this.
The dynamic goal-loop. The engine holds a milestone open and reopens tasks until its exit criteria are met, rather than declaring done when a checklist empties. A checklist can empty while an exit criterion remains unmet; that gap is where quiet failures live. The goal-loop is what prevented ai-proxy’s 23 milestones from declaring done prematurely — the engine kept reopening until the evidence bundle was complete.
Adopting it honestly
The chapter on adoption in the full ADD material makes a point worth carrying here: start on one real product, not as an all-at-once mandate. The 90-day rollout starts by locking the foundation on a single pilot service (days 1–15), running one feature end to end at the Express profile (days 16–45), wiring the gates into the pipeline (days 46–75), and only then promoting to Standard (days 76–90). The method is genuinely lean at the Express profile — one human approval per task, a short foundation document, no per-phase planning documents. The overhead grows with the risk profile, deliberately.
Onboarding follows the same principle in reverse: bring people in from the concrete end and move them toward judgment. Start with Build and Tests — implement against a spec that was handed to you; make a red test green without weakening it. Contracts and design come next, then Scenarios and Specify, then domain discovery. Deciding what to build is the senior skill, not the entry skill.
The thing not to over-engineer: the foundation. PROJECT.md is meant to be short. A conventions file that runs to hundreds of lines in the first week is a sign the method is being applied ceremonially rather than instrumentally. The foundation is what the agent reads to orient itself; it serves the agent, not the other way around. Trim it to what the next session actually needs.
Closing the series
This series opened with a single claim: the marginal cost of writing code has fallen close to zero, and that collapse moves value to whatever is still scarce — direction and verification. Nine parts have built out the full architecture of how to supply them.
Part 1 named the four AI-era SDLC failures and the thesis that answers them: constrain the what, free the how, verify by evidence. Parts 2 through 5 built the foundation and the engine — the five competencies, the spec and scenarios, the frozen contract, the red tests and the build loop. Parts 6 and 7 covered the two steps that give the method its distinctive shape: Verify, which turns trust-by-inspection into trust-by-evidence, and Observe, which turns production signal into the next loop’s specification. Part 8 grounded everything in ai-proxy — 23 milestones, 120 tasks, six days, zero waivers, graduated to production. And this final part has placed ADD in its lineage and named precisely where it sits among its neighbors.
The method is a recombination of proven ideas — TDD’s executable definition of done, DDD’s ubiquitous language, BDD’s scenarios, contract-first’s frozen surface, literate development’s specification-as-asset — re-pointed at an AI builder and closed into a loop. The loop already runs: by 2026, more than 80 percent of the code merged at Anthropic was Claude-authored. What it does not yet supply on its own is the discipline to trust the output. The frozen contract, the never-weaken-a-test rule, the evidence-over-inspection gate, and the security HARD-STOP that no autonomy level may auto-pass are what supply that discipline — and as the loop grows more capable, those gates matter more, not less.
Clamp the what, free the how, and verify the result. The forward look is not complicated: the same method, applied to larger scopes and faster loops, as agents grow more capable. The gates do not loosen with capability — they are what make capability trustworthy.
The series begins at Part 1 — How AI-Driven Development Fixes the SDLC for Agent Coding, if you want to read it from the start. The loop is complete.