
I want to show you something. Take one real feature, one AI agent, one codebase — and build it twice. Once the way most people use AI, once the way a pro does. Same everything. The only variable is how you drive. The gap between the two outcomes is the whole point.
Let me set the scene first, because the feature matters.
Imagine a tab running at a bar you can’t see. Every drink your customers order, you get charged for. You’re supposed to pass that charge along — but the till only rings up some of the rounds. Nobody notices until the bar slides the month’s bill across the counter, and it’s bigger than everything you collected.
Swap the bar for an AI provider and the drinks for API calls, and that’s the quiet nightmare of running an AI proxy — a gateway between an app and the model providers (OpenAI, Anthropic, Google) that bills each request. Every call costs you upstream and is supposed to bill the customer downstream. When the two drift apart, you bleed money on every request and find out 30 days late.
Here’s the actual leak, one row at a time, in a ledger that can never be edited:
| request | provider charged us | we billed the customer |
|---|---|---|
| #1 | $0.012 | $0.018 ✅ |
| #2 | $0.040 | $0.060 ✅ |
| #3 | $0.030 | $0.000 🔴 |
Row #3 is the nightmare. One row is a rounding error; ten thousand is a budget hole. The job, in plain English:
Reconcile every dollar the provider charges us against what we billed the customer, and raise an alarm the moment they drift — so an upstream charge with no matching customer charge can never go unnoticed.
This is a true story — milestone v29 of a production proxy (internally hydroa) that’s shipped 50 milestones. Now let’s build that feature twice.
The apples-to-apples rules: same goal sentence, same AI model, same existing codebase, same engineer. The only thing that changes is the method. On one side, Normal AI use — describe it, accept what comes back, ship it. On the other, Pro AI use — the discipline its practitioners call ADD (AI-Driven Development), whose one-liner is: “Build the right thing, prove it’s right, and let the AI do the building in between.”
First, the only thing that changes: your opening move
Before the five rounds, look at the two literal prompts. Same goal, same model (Claude Opus), same codebase — read them side by side, because this is the entire difference. Everything that happens later flows from it.
🟠 Normal — hand the AI the wheel and say “go”:
Add an endpoint so an admin can see billing drift across all tenants,and fire an alert if the drift goes over a threshold. Use our existingusage table.🟢 Pro — invoke the /add skill, state the goal, drop a few keynotes:
# /add <describe your goal in one sentence>/add reconcile what each provider charged us against what we billed thecustomer, and alert when the two drift past a threshold.Notice how short the Pro prompt is — it’s the same one-sentence goal, just handed to /add. You don’t spell out the steps, because the skill already runs them: it grounds itself in the real code, drafts the spec, then interviews you to freeze a contract, writes the tests red-first, and verifies on evidence. You give it the goal; the method supplies the rigor — and stops to ask you only at the few moments that genuinely need a human call (the contract freeze, and any security finding).
So the difference isn’t effort, and it isn’t word count. The Normal prompt quietly hands over every decision nobody spelled out — what “drift” means, who may see it, what “too high” is — for the AI to guess. The Pro prompt invokes a method instead of a guess.
After you hit enter: who finishes the prompt?
A prompt is a beginning, not a deliverable — something has to carry it from “described” to “done.” The whole difference is who that something is.
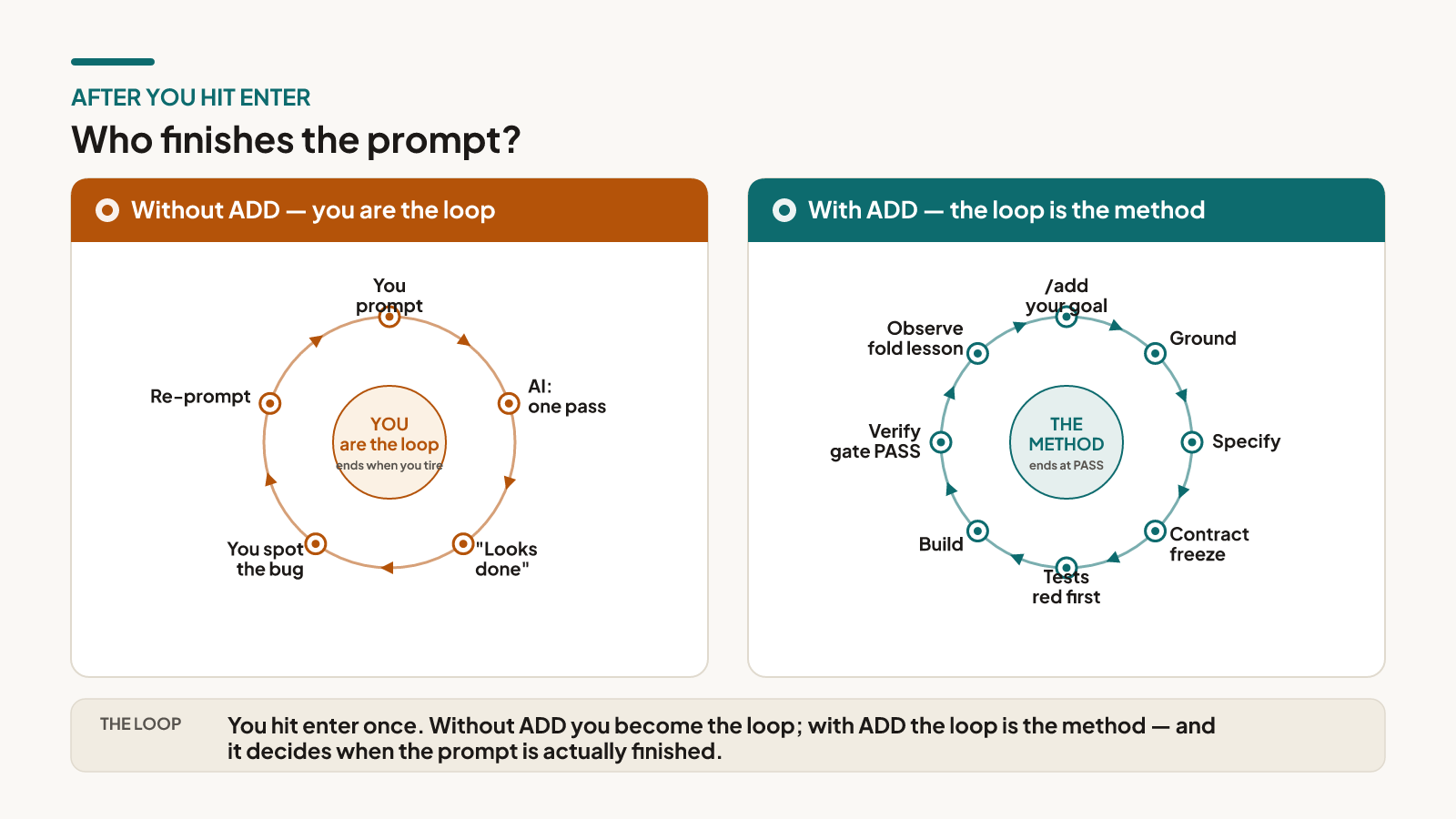
Here’s that loop, one step at a time:
The build, step by step: with ADD vs without
Same one-sentence goal, same model. Here’s the entire build collapsed into the five ADD steps — what each one produced on v29, next to what “just let the AI do it” produces. Read it as one story, because the pattern repeats in every row: every place ADD wins, it wins by doing something before the code that the Normal path skips.

Notice the rhythm down the rows. The Normal path is always faster to look done and slower to be trustworthy. ADD spends a little judgment up front — yours at the contract freeze, the method’s everywhere else — and buys back the long tail of incidents, refunds, and 11pm debugging.
The two scorecards, side by side
Same feature. Same AI. Same week. Stop looking at the code and look at the results — the measures you’d actually report to a stakeholder:
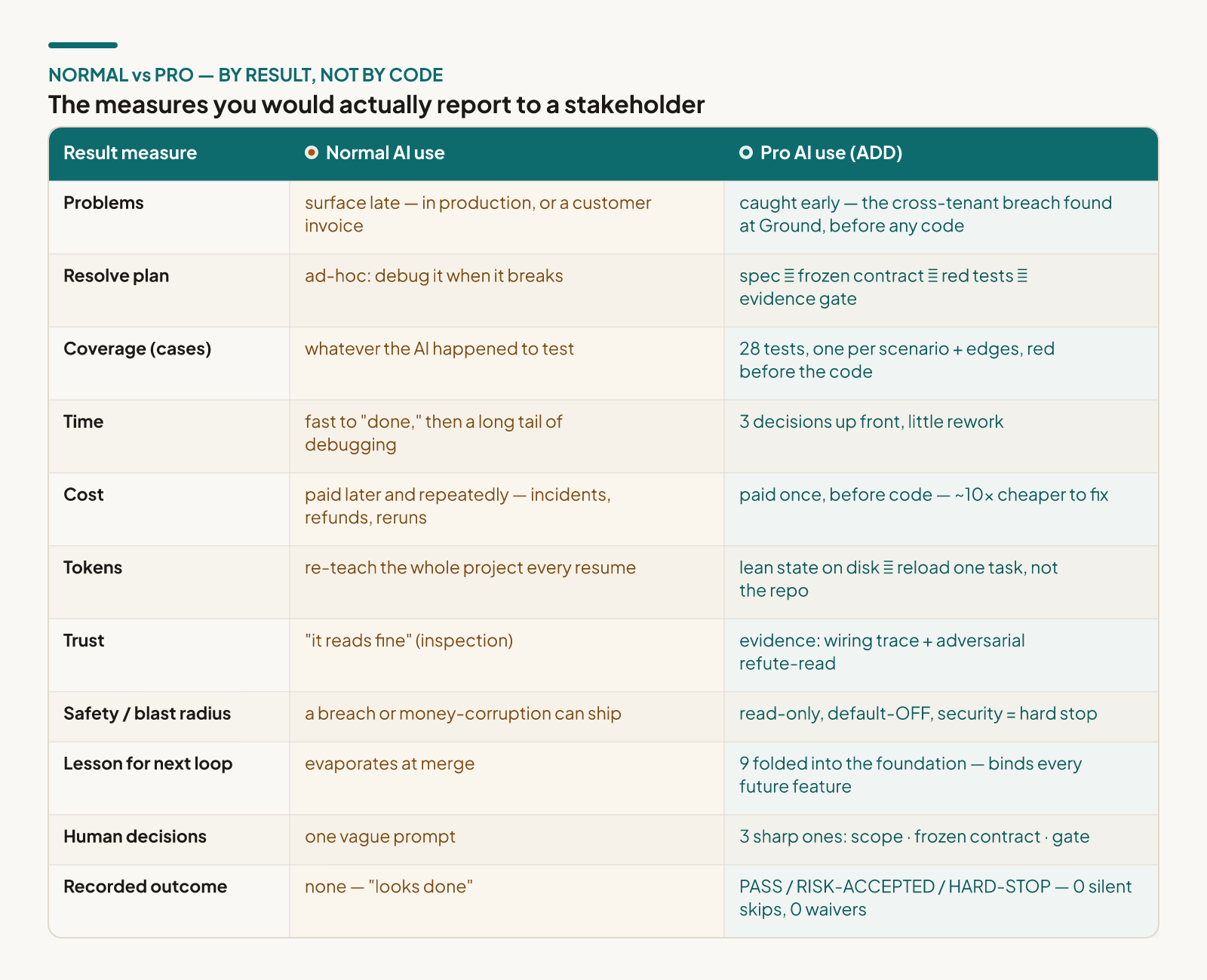
Look at the Human decisions row, because it’s the one people get backwards. Pro use isn’t more of your time — it’s less of the wrong kind. Three sharp decisions up front instead of a long tail of 11pm debugging. The thinking was always yours to do; the method just moves it to where it’s 10× cheaper — before the code, not inside a customer’s invoice.
So what does “pro” actually buy you?
Strip it all down and here’s the trade. With Normal AI use, speed costs you trust — you go fast and hope. With Pro AI use, you keep the speed and you can prove it’s right, because trust comes from recorded evidence, not from you reading every diff.
You stay in the only two seats where a human is still scarce — deciding what to build and confirming it’s correct — and you safely hand the typing to the machine. Breaches die before code exists. “Done” means proven, not plausible. The AI is built to doubt itself, so you’re not the lone gatekeeper. And the whole system gets a little harder to fool every time it ships.
That’s not a story about a smarter AI. It’s the same AI, both times. It’s a story about how you use it.
Conclusion — you don’t have to learn all of this
Look back at the five steps: grounding the real code, ranking the lowest-confidence assumption, writing tests red-first, tracing the wiring, running an adversarial refute-read, folding lessons into the foundation. That’s years of hard-won engineering judgment on display.
Here’s the relief: you don’t have to carry any of it in your head. That’s the whole point of ADD — the rigor lives in the loop, not in you. You don’t memorize the verification tricks, the test patterns, or the security checks; the method runs them and escalates only the handful of calls that genuinely need a human. Your job shrinks to the two things only you can do: say what to build, and confirm it’s right.
So don’t try to become a one-person QA-plus-security-plus-architecture team. Just run ADD inside the AI agent you already use — Claude Code, Cursor, Codex, whatever’s on your screen — and let the loop carry the discipline. To start, take one money- or data-critical path you already ship and ask it the three questions that separate the two columns:
- Where’s its frozen contract? (Did you decide what it means, or did the AI guess?)
- Where’s the test that was red before the code existed? (Or did you trust a green that was never earned?)
- What did shipping it teach you that the next feature inherits? (Or did the lesson evaporate at merge?)
If you can’t answer all three, that path isn’t pro-grade yet — it’s just Normal AI use that hasn’t been caught.
The AI didn’t make this proxy trustworthy. The way it was used did. You don’t need to learn everything the method knows — you just need to let it drive.
Get ADD
ADD is open source — the method, the engine, and the full docs live at github.com/pilotspace/ADD.
- Drop it into any repo. Add the
.add/engine and docs to your project — it rides alongside whatever agent you already use (Claude Code, Cursor, Codex). - Run your first task. Type
/add <your goal in one sentence>and let the loop ground, specify, freeze a contract with you, test red-first, build, and verify. - Keep the lessons. Each milestone folds what it learned into your foundation, so the next prompt starts smarter.
Star it, read the book, and run one real task this week: github.com/pilotspace/ADD. Rent the model — own the loop.