
The previous series proved something narrow and specific: AI-Driven Development works for agent coding. A 23-milestone production gateway — six upstream providers, metering, billing, multi-tenant key governance — built end to end through the ADD loop in six days, zero risk-waivers, zero critical defects shipped. The software-native version of this method is documented there in full.
This series asks the harder question. Was ADD useful because it addressed something specific about software, or because it addressed something general about delegating generative work to a fast, fallible producer?
The answer matters now, because the thing that broke the software development lifecycle — a producer that generates confident, plausible, complete-looking output faster than you can verify it — has arrived everywhere. A marketing team prompts for campaign briefs. A recruiter uses AI to screen and score candidates. A finance team builds its FP&A model with AI-generated assumptions. A legal team drafts contracts from AI playbooks. The producer is now an AI in every knowledge-work domain. And the same four failures appear, in every one of them, within weeks of adoption.
ADD was never really about code. It is about a loop. This post explains why, lays out the universal translation that every domain post in this series uses, and shows in three brief cross-domain examples that the translation holds.
Why it generalizes
The software-native ADD loop rests on one insight: coding agents failed not because they could not write code — they could — but because direction and verification were being handled by whoever typed the prompt, which is exactly the wrong person to do it at that moment. The agent needed a fixed what (spec, frozen contract, red tests) before it could be trusted to produce the how (implementation).
That insight has nothing to do with code. It is a claim about delegated generative work. The structure of that delegation is now identical across domains: in marketing, a language model drafts campaign copy that looks professionally finished and may be strategically wrong; in recruiting, it screens candidates that are operationally ranked and may be systematically biased; in finance, it generates forecasts that are numerically coherent and may be built on a misread assumption; in legal, it drafts contracts that are syntactically clean and may introduce liability a partner would catch in forty seconds.
The producer has changed — it is now an AI — but the human’s job in the presence of a fast, fallible producer is the same job it always was: decide what the output must accomplish, and verify that it does. ADD is a protocol for doing that job without letting the producer’s speed or plausibility override it.
The four failures, everywhere
The four AI-era failures that ADD diagnosed in software recur verbatim in every knowledge-work domain. Their names stay the same; their costumes change.
Fast waste surfaces when direction is vague and the producer is confident. A recruiting AI that receives “find strong candidates for a senior role” will return a ranked list. The list will look thorough. It will reflect whatever correlation the model found salient — years at brand-name firms, credential patterns — which may have nothing to do with the actual job requirements the hiring manager had in mind. The waste accumulates invisibly until the wrong candidates are deep in the pipeline and the right ones were filtered at the screen.
Context rot surfaces when the governing policy lives in someone’s head rather than in a document the producer reads first. A finance team that builds its AI forecasting workflow without a grounding document for pricing strategy, regional rules, and inter-company eliminations will find that every new session re-guesses those rules. The model is not wrong — it is working from an empty context. The rot is not in the AI; it is in the gap between the organization’s actual policy and what the producer was told.
Trust-by-inspection breaks down the moment the output exceeds the domain expert’s available attention. A legal playbook drafted by AI and reviewed by a partner who reads it “looks fine” is precisely as safe as a code diff reviewed by an engineer who reads it “looks fine.” Both are assessing plausibility, not correctness. In law, as in software, there is a meaningful gap between prose that sounds right and prose that is right.
The verification ceiling is the hard limit that makes the other three dangerous. An organization that can generate ten times its previous output has not created ten times the throughput — it has created ten times the surface area to verify. Output beyond your capacity to verify is not productivity. It is unreviewed risk, accumulating quietly while the team measures generation speed.
The universal translation
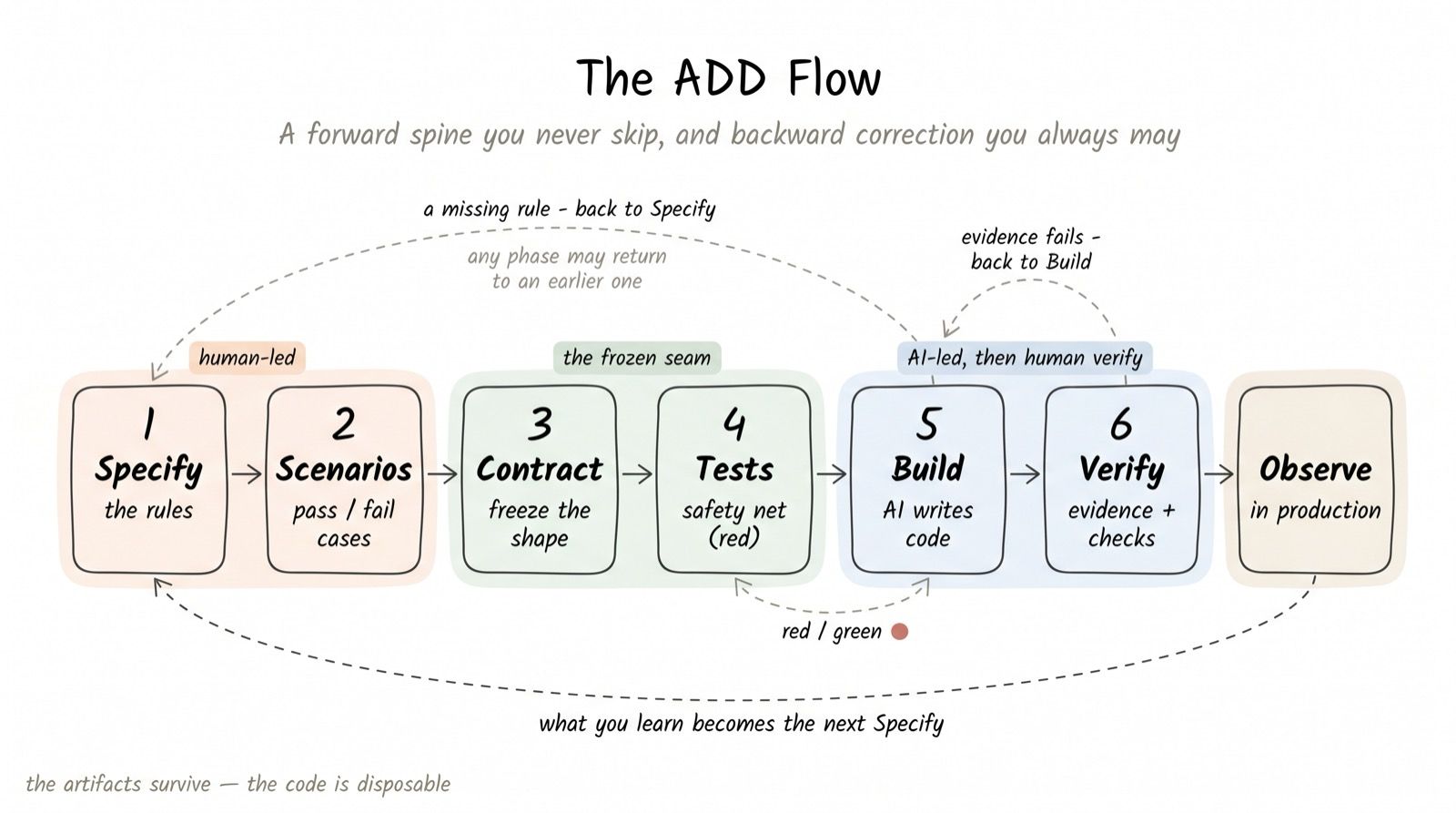
The ADD loop has eight steps. In software, each step produces a concrete artifact: a grounding map, a spec, a set of scenarios, a frozen contract, a red test suite, a green build, a verify record, and a spec delta. Across every other knowledge-work domain, those steps produce analogous artifacts in the domain’s own language.
This table is the single frame the entire series uses. Every domain post maps its concrete artifacts onto these rows:
| ADD step (software) | Universal form (any domain) |
|---|---|
| 0 · Ground | Load the domain context — brand, policy, prior decisions, constraints — into one place the producer reads first. |
| 1 · Specify | The brief: what the output must do, what it must not do (each refusal paired with a named reason), and the after-state that defines success. |
| 2 · Scenarios | Concrete examples in domain language: the model case, the edge case, the failure case. |
| 3 · Contract (FROZEN — the one human gate) | The approved, locked definition-of-done at the boundary. The single human sign-off, before the work is produced. |
| 4 · Acceptance checks (the “red tests”) | A written, checkable definition of done the output must pass — failing before the work exists. |
| 5 · Produce (the “green build”) | The producer (AI or person) makes every check pass. The how is unconstrained and disposable. |
| 6 · Verify by evidence | Prove it is right with evidence — data, adversarial “refute-read” — not “looks good.” |
| 7 · Observe & fold | Real-world results fold back into the next brief. The playbook stays living, not signed-once-and-rotting. |
The mechanics of each step change by domain. The order, the logic, and the gate structure do not. Step 3 is always the single human sign-off, always before production begins. Step 6 is always evidence — never plausibility. Step 7 always folds back in. That rigidity is the point: the loop is trustworthy precisely because the domain cannot opt out of the expensive steps.
The invariant beneath all eight steps is the same sentence in every domain:
Constrain the what — outcome and acceptance criteria. Free the how — execution. Verify the result by evidence, not by appearance.

The briefing document, the frozen contract, and the acceptance checklist are the what. The producer — human or AI — owns the how completely. The verify step requires evidence of a kind the domain specifies in advance: an A/B result, a bias audit, a backtest, a redline review, a control test. “It reads fine” is not evidence. It is the trust-by-inspection failure wearing a professional tone.
Three quick proofs of breadth
Three cases show that the translation is not metaphorical — it is structural.
Marketing: the campaign brief is the spec. A marketing team that prompts an AI for copy without a grounding brief is giving the equivalent of a one-line feature request to a coding agent. The output will be fluent and directionally wrong — the wrong positioning claim, the wrong audience register, the wrong call to action — and it will look professional enough to survive a casual review. The ADD translation is direct: the brief is the spec (must do, must not do, after-state), the frozen contract is the approved message hierarchy the AI writes toward rather than inventing, and the acceptance checks are the criteria the copy must satisfy before it leaves the team. The Part 2 deep-dive — Add for Marketing — walks every artifact.
Machine learning: the evaluation set is the frozen contract. An ML team that lets the model influence its own evaluation set has eliminated the one gate that separates measurement from performance theater. The evaluation set is ADD’s frozen contract: it must be defined and locked before training runs, and it must not be modified based on the model’s results. When it is, the acceptance checks (benchmark scores) become self-referential, and the green build is green for no trustworthy reason. The Part 9 deep-dive maps every ADD step onto the ML workflow, including where this specific failure appears and how the frozen-contract gate stops it.
Legal: the playbook is the frozen contract. A legal team that uses an AI to draft contracts without a signed-off playbook (approved clause library, defined escalation triggers, jurisdiction-specific carve-outs) has the same problem as the coding agent that has no frozen interface to build against: the producer will invent the shape of the thing it is producing, and the human at the end will catch some of those inventions and miss others. The playbook is the frozen contract. The acceptance checks are the redline criteria applied before a draft goes to the other side. The Part 11 deep-dive grounds this in contract negotiation and regulatory filing.
None of these is a stretched metaphor. The ADD structure maps directly in each case because the underlying situation is identical: a producer faster than verification, generating output that is plausible before it is correct. The domain changes the vocabulary; it does not change the logic.
The rest of the series
Eleven domain posts follow this one. Each takes the universal frame above and instantiates it with concrete artifacts, domain-specific acceptance criteria, and honest caveats about where the analogy strains or where human judgment stays irreducible.
The full roster:
- Part 2 — ADD for Marketing: brief as spec, message hierarchy as frozen contract, A/B as verification.
- Part 3 — ADD for Sales: qualification criteria as spec, ICP as frozen contract.
- Part 4 — ADD for Customer Support: policy as spec, approved resolution library as frozen contract.
- Part 5 — ADD for HR & People Ops: role definition as spec, structured rubric as frozen contract.
- Part 6 — ADD for Project Management: scope doc as spec, milestone exit criteria as frozen contract.
- Part 7 — ADD for Engineering Leadership: strategy brief as spec, architecture decision record as frozen contract.
- Part 8 — ADD for DevOps & SRE: runbook as spec, incident acceptance criteria as frozen contract.
- Part 9 — ADD for Machine Learning: model brief as spec, evaluation set as frozen contract.
- Part 10 — ADD for Finance & FP&A: model brief as spec, locked assumptions as frozen contract.
- Part 11 — ADD for Legal & Contracts: playbook as spec, clause library as frozen contract.
- Part 12 — ADD for Compliance & Risk: control framework as spec, evidence checklist as frozen contract.
Start with Part 2 — ADD for Marketing — the most accessible domain translation and the clearest illustration of how a brief, a frozen message hierarchy, and an A/B result replace “it looks good” with evidence. The frame is the same in every post that follows.