Before you build anything interesting on top of a language model, it helps to know precisely what a language model is — and, just as importantly, what it isn’t. The gap between intuition and reality is bigger than most people realize, and almost every confusing thing about AI products later in this series traces back to a missed detail at this layer.
This post is the floor. The rung labeled LLM Core. By the end of it you’ll be able to look at any chatbot and sketch, in one diagram, exactly what happens between you pressing Enter and a reply appearing.
The model is a function
Here is the entire contract, written honestly:
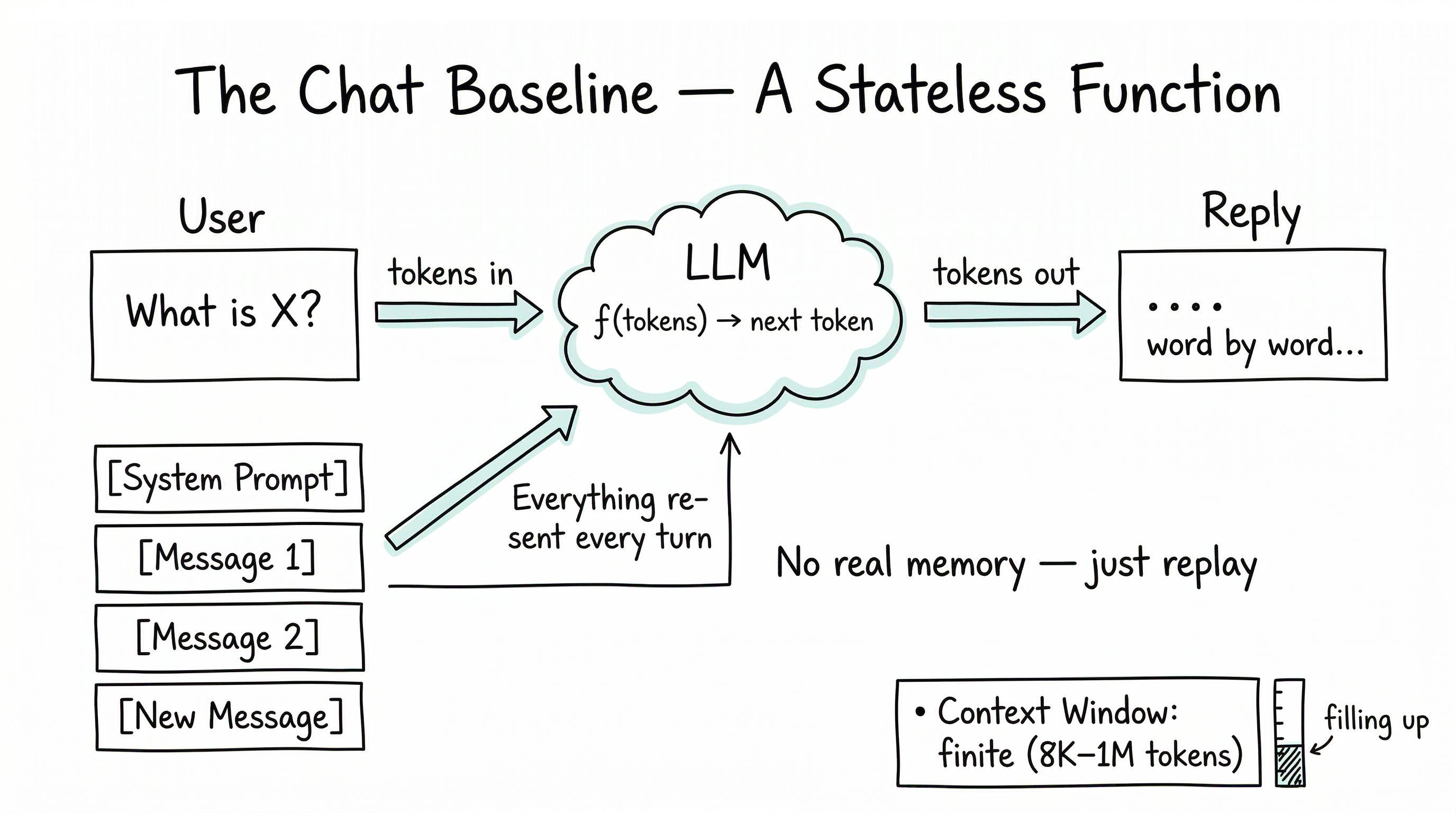
tokens_in → model → next_token_probabilities → sampled_next_tokenThat’s it. A large language model takes a sequence of tokens (roughly: pieces of words), and returns a probability distribution over what token should come next. An outer loop then samples one token from that distribution, appends it to the input, and asks the model again. Repeat until the model emits a “stop” token or the budget runs out.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M174.348%2c62L174.348%2c66.167C174.348%2c70.333%2c174.348%2c78.667%2c174.348%2c86.333C174.348%2c94%2c174.348%2c101%2c174.348%2c104.5L174.348%2c108' id='mermaid-0-L_IT_M_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_IT_M_0' data-points='W3sieCI6MTc0LjM0NzY1NjI1LCJ5Ijo2Mn0seyJ4IjoxNzQuMzQ3NjU2MjUsInkiOjg3fSx7IngiOjE3NC4zNDc2NTYyNSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M137.959%2c166L132.343%2c170.167C126.728%2c174.333%2c115.497%2c182.667%2c109.881%2c190.333C104.266%2c198%2c104.266%2c205%2c104.266%2c208.5L104.266%2c212' id='mermaid-0-L_M_PD_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_M_PD_0' data-points='W3sieCI6MTM3Ljk1ODkwOTI1NDgwNzY4LCJ5IjoxNjZ9LHsieCI6MTA0LjI2NTYyNSwieSI6MTkxfSx7IngiOjEwNC4yNjU2MjUsInkiOjIxNn1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M104.266%2c270L104.266%2c274.167C104.266%2c278.333%2c104.266%2c286.667%2c104.266%2c294.333C104.266%2c302%2c104.266%2c309%2c104.266%2c312.5L104.266%2c316' id='mermaid-0-L_PD_ST_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PD_ST_0' data-points='W3sieCI6MTA0LjI2NTYyNSwieSI6MjcwfSx7IngiOjEwNC4yNjU2MjUsInkiOjI5NX0seyJ4IjoxMDQuMjY1NjI1LCJ5IjozMjB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M104.266%2c374L104.266%2c378.167C104.266%2c382.333%2c104.266%2c390.667%2c104.266%2c398.333C104.266%2c406%2c104.266%2c413%2c104.266%2c416.5L104.266%2c420' id='mermaid-0-L_ST_AP_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_ST_AP_0' data-points='W3sieCI6MTA0LjI2NTYyNSwieSI6Mzc0fSx7IngiOjEwNC4yNjU2MjUsInkiOjM5OX0seyJ4IjoxMDQuMjY1NjI1LCJ5Ijo0MjR9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M104.266%2c478L104.266%2c482.167C104.266%2c486.333%2c104.266%2c494.667%2c110.609%2c507.405C116.952%2c520.143%2c129.638%2c537.286%2c135.981%2c545.857L142.324%2c554.429' id='mermaid-0-L_AP_SC_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AP_SC_0' data-points='W3sieCI6MTA0LjI2NTYyNSwieSI6NDc4fSx7IngiOjEwNC4yNjU2MjUsInkiOjUwM30seyJ4IjoxNDQuNzAzMzgwNjYzMjk4NTYsInkiOjU1Ny42NDQyNzU1ODY3MDE0fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M203.992%2c557.644L210.732%2c548.537C217.471%2c539.43%2c230.95%2c521.215%2c237.69%2c503.441C244.43%2c485.667%2c244.43%2c468.333%2c244.43%2c451C244.43%2c433.667%2c244.43%2c416.333%2c244.43%2c399C244.43%2c381.667%2c244.43%2c364.333%2c244.43%2c347C244.43%2c329.667%2c244.43%2c312.333%2c244.43%2c295C244.43%2c277.667%2c244.43%2c260.333%2c244.43%2c243C244.43%2c225.667%2c244.43%2c208.333%2c239.35%2c195.897C234.269%2c183.461%2c224.109%2c175.922%2c219.029%2c172.153L213.949%2c168.383' id='mermaid-0-L_SC_M_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_SC_M_0' data-points='W3sieCI6MjAzLjk5MTkzMTgzNjcwMTQ0LCJ5Ijo1NTcuNjQ0Mjc1NTg2NzAxNH0seyJ4IjoyNDQuNDI5Njg3NSwieSI6NTAzfSx7IngiOjI0NC40Mjk2ODc1LCJ5Ijo0NTF9LHsieCI6MjQ0LjQyOTY4NzUsInkiOjM5OX0seyJ4IjoyNDQuNDI5Njg3NSwieSI6MzQ3fSx7IngiOjI0NC40Mjk2ODc1LCJ5IjoyOTV9LHsieCI6MjQ0LjQyOTY4NzUsInkiOjI0M30seyJ4IjoyNDQuNDI5Njg3NSwieSI6MTkxfSx7IngiOjIxMC43MzY0MDMyNDUxOTIzMiwieSI6MTY2fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M174.348%2c667.406L174.348%2c673.573C174.348%2c679.74%2c174.348%2c692.073%2c174.348%2c703.74C174.348%2c715.406%2c174.348%2c726.406%2c174.348%2c731.906L174.348%2c737.406' id='mermaid-0-L_SC_OUT_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_SC_OUT_0' data-points='W3sieCI6MTc0LjM0NzY1NjI1LCJ5Ijo2NjcuNDA2MjV9LHsieCI6MTc0LjM0NzY1NjI1LCJ5Ijo3MDQuNDA2MjV9LHsieCI6MTc0LjM0NzY1NjI1LCJ5Ijo3NDEuNDA2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_IT_M_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_M_PD_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_PD_ST_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_ST_AP_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AP_SC_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(244.4296875%2c 347)'%3e%3cg class='label' data-id='L_SC_M_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(174.34765625%2c 704.40625)'%3e%3cg class='label' data-id='L_SC_OUT_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-IT-0' data-look='classic' transform='translate(174.34765625%2c 35)'%3e%3crect class='basic label-container' style='' x='-73.5859375' y='-27' width='147.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-43.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='87.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eInput tokens%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-M-1' data-look='classic' transform='translate(174.34765625%2c 139)'%3e%3crect class='basic label-container' style='' x='-51.7890625' y='-27' width='103.578125' height='54'/%3e%3cg class='label' style='' transform='translate(-21.7890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='43.578125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModel%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-PD-3' data-look='classic' transform='translate(104.265625%2c 243)'%3e%3crect class='basic label-container' style='' x='-90.03125' y='-27' width='180.0625' height='54'/%3e%3cg class='label' style='' transform='translate(-60.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='120.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eProb. distribution%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-ST-5' data-look='classic' transform='translate(104.265625%2c 347)'%3e%3crect class='basic label-container' style='' x='-96.265625' y='-27' width='192.53125' height='54'/%3e%3cg class='label' style='' transform='translate(-66.265625%2c -12)'%3e%3crect/%3e%3cforeignObject width='132.53125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSample next token%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-AP-7' data-look='classic' transform='translate(104.265625%2c 451)'%3e%3crect class='basic label-container' style='' x='-86.046875' y='-27' width='172.09375' height='54'/%3e%3cg class='label' style='' transform='translate(-56.046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='112.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAppend to input%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-SC-9' data-look='classic' transform='translate(174.34765625%2c 597.703125)'%3e%3cpolygon points='69.703125%2c0 139.40625%2c-69.703125 69.703125%2c-139.40625 0%2c-69.703125' class='label-container' transform='translate(-69.203125%2c 69.703125)'/%3e%3cg class='label' style='' transform='translate(-42.703125%2c -12)'%3e%3crect/%3e%3cforeignObject width='85.40625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStop token%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-OUT-13' data-look='classic' transform='translate(174.34765625%2c 768.40625)'%3e%3crect class='basic label-container' style='' x='-88.703125' y='-27' width='177.40625' height='54'/%3e%3cg class='label' style='' transform='translate(-58.703125%2c -12)'%3e%3crect/%3e%3cforeignObject width='117.40625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOutput complete%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
The model predicts the next token. Nothing more.
It does not reason in the way humans reason. It does not look anything up. It does not have a memory of previous conversations. It does not know what day it is, unless you tell it. It does not know whether its last answer was right, because it has no concept of “last answer” — by the time the next request arrives, it has already forgotten everything.
If this sounds reductive, it is also precise. Every impressive behavior you’ve seen from a modern model — reasoning, planning, apologizing for a mistake — is produced inside one continuous prediction pass. The model is not thinking; it is rapidly producing text that, statistically, is what thinking would look like if you wrote it down.
That is not a pejorative. It turns out to be incredibly useful. But the moment you forget it, you will over-trust the output.
The memory illusion
“But wait,” you say. “The chatbot I used yesterday clearly remembered what I asked earlier in the conversation.”
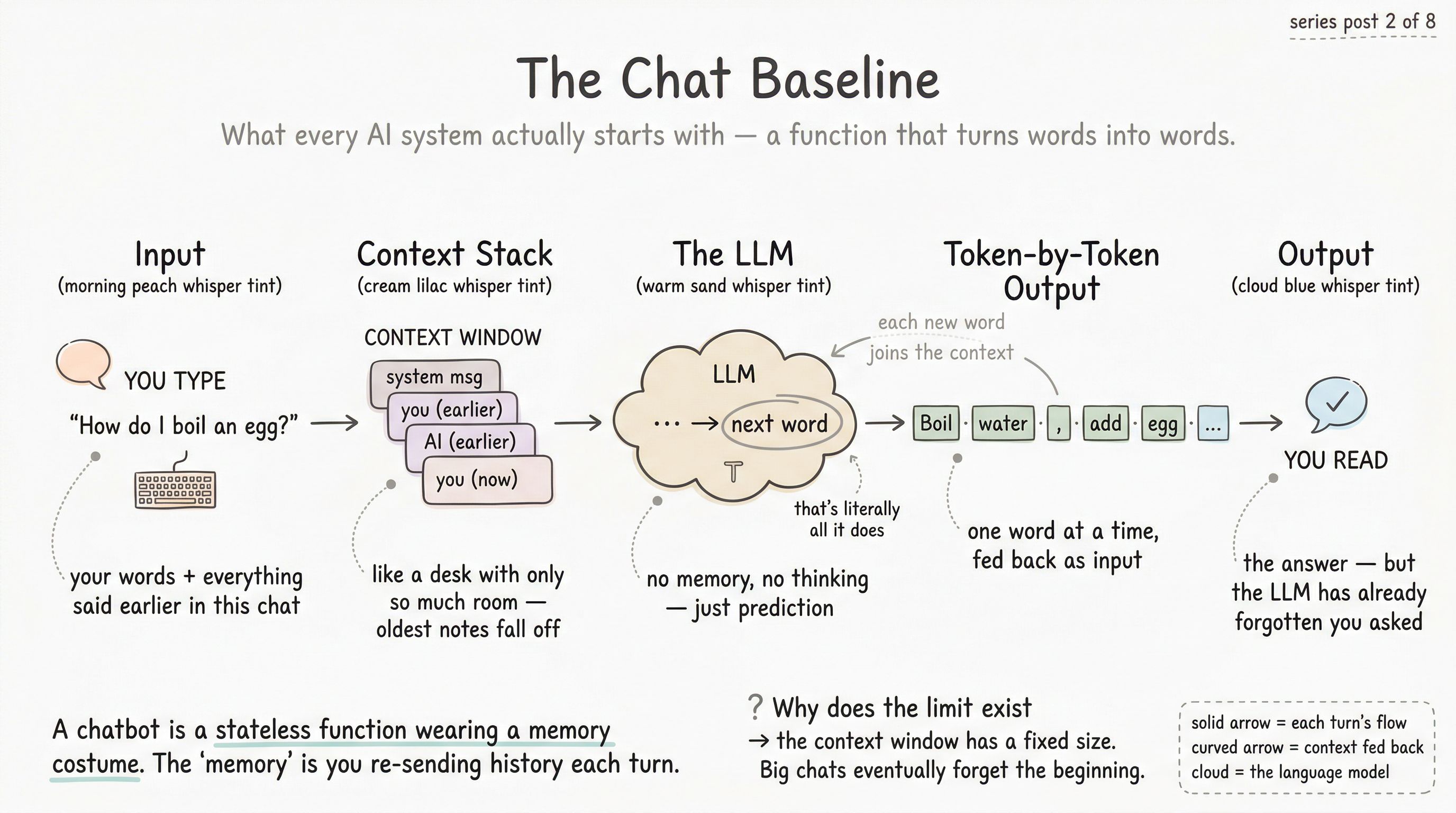
It did — but the model didn’t. Here is the trick, and it is the single most important thing to understand at this rung:
Every turn, the product re-sends the entire conversation so far.
%3b%7d%23mermaid-1 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M146.273%2c86L146.273%2c90.167C146.273%2c94.333%2c146.273%2c102.667%2c146.273%2c110.333C146.273%2c118%2c146.273%2c125%2c146.273%2c128.5L146.273%2c132' id='mermaid-1-L_T1_T2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T1_T2_0' data-points='W3sieCI6MTQ2LjI3MzQzNzUsInkiOjg2fSx7IngiOjE0Ni4yNzM0Mzc1LCJ5IjoxMTF9LHsieCI6MTQ2LjI3MzQzNzUsInkiOjEzNn1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M146.273%2c214L146.273%2c218.167C146.273%2c222.333%2c146.273%2c230.667%2c146.273%2c238.333C146.273%2c246%2c146.273%2c253%2c146.273%2c256.5L146.273%2c260' id='mermaid-1-L_T2_T3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T2_T3_0' data-points='W3sieCI6MTQ2LjI3MzQzNzUsInkiOjIxNH0seyJ4IjoxNDYuMjczNDM3NSwieSI6MjM5fSx7IngiOjE0Ni4yNzM0Mzc1LCJ5IjoyNjR9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M146.273%2c342L146.273%2c346.167C146.273%2c350.333%2c146.273%2c358.667%2c146.273%2c366.333C146.273%2c374%2c146.273%2c381%2c146.273%2c384.5L146.273%2c388' id='mermaid-1-L_T3_TN_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T3_TN_0' data-points='W3sieCI6MTQ2LjI3MzQzNzUsInkiOjM0Mn0seyJ4IjoxNDYuMjczNDM3NSwieSI6MzY3fSx7IngiOjE0Ni4yNzM0Mzc1LCJ5IjozOTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_T1_T2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_T2_T3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_T3_TN_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-T1-0' data-look='classic' transform='translate(146.2734375%2c 47)'%3e%3crect class='basic label-container' style='' x='-84.015625' y='-39' width='168.03125' height='78'/%3e%3cg class='label' style='' transform='translate(-54.015625%2c -24)'%3e%3crect/%3e%3cforeignObject width='108.03125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTurn 1 sends%3cbr /%3esystem %2b msg1%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-T2-1' data-look='classic' transform='translate(146.2734375%2c 175)'%3e%3crect class='basic label-container' style='' x='-102.2578125' y='-39' width='204.515625' height='78'/%3e%3cg class='label' style='' transform='translate(-72.2578125%2c -24)'%3e%3crect/%3e%3cforeignObject width='144.515625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTurn 2 sends%3cbr /%3esys%2bmsg1%2br1%2bmsg2%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-T3-2' data-look='classic' transform='translate(146.2734375%2c 303)'%3e%3crect class='basic label-container' style='' x='-138.2734375' y='-39' width='276.546875' height='78'/%3e%3cg class='label' style='' transform='translate(-108.2734375%2c -24)'%3e%3crect/%3e%3cforeignObject width='216.546875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTurn 3 sends%3cbr /%3esys%2bmsg1%2br1%2bmsg2%2br2%2bmsg3%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-TN-8' data-look='classic' transform='translate(146.2734375%2c 419)'%3e%3crect class='basic label-container' style='' x='-112.265625' y='-27' width='224.53125' height='54'/%3e%3cg class='label' style='' transform='translate(-82.265625%2c -12)'%3e%3crect/%3e%3cforeignObject width='164.53125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEach turn grows bigger%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-1-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
When you type a new message, the system gathers:
- The system message (hidden instructions — we’ll cover this in the next post)
- Every previous user message and assistant reply in the current chat
- Your new message
…concatenates them into one long string, and sends the whole thing to the model as a fresh request. The model reads it top-to-bottom, has no memory of having seen any of it before, and produces the next turn. Then the product appends the new reply to the record, and the next turn begins.
The “memory” you experience is a costume the product wears. The model underneath is as stateless as a calculator.
This has several immediate consequences that confuse people constantly:
- Long conversations get slower and more expensive. You’re sending a bigger and bigger transcript each turn.
- The model’s “personality” can drift as the system message gets diluted by user text accumulating above it.
- Anything the model “forgets” in a long chat is often a product choice, not a model limit: it’s the harness deciding to trim old messages to stay within a size limit.
The context window
The long string the model reads has a size limit, measured in tokens. That limit is called the context window, and it is the most physical constraint in the entire stack.
As of 2026, context windows range from around 8K tokens on older free-tier models to one million or more on newer paid models. One million tokens is roughly a thousand pages of text — the size of a novel trilogy, give or take. Enormous, by historical standards. Still finite.
When a conversation approaches the limit, one of three things happens depending on the product:
%3b%7d%23mermaid-2 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-2-gradient)%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M301.805%2c54.093L273.007%2c59.577C244.208%2c65.062%2c186.612%2c76.031%2c157.814%2c85.015C129.016%2c94%2c129.016%2c101%2c129.016%2c104.5L129.016%2c108' id='mermaid-2-L_CW_S1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_CW_S1_0' data-points='W3sieCI6MzAxLjgwNDY4NzUsInkiOjU0LjA5MjUwNjIyMzM1NDAzfSx7IngiOjEyOS4wMTU2MjUsInkiOjg3fSx7IngiOjEyOS4wMTU2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M402.055%2c62L402.055%2c66.167C402.055%2c70.333%2c402.055%2c78.667%2c402.055%2c86.333C402.055%2c94%2c402.055%2c101%2c402.055%2c104.5L402.055%2c108' id='mermaid-2-L_CW_S2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_CW_S2_0' data-points='W3sieCI6NDAyLjA1NDY4NzUsInkiOjYyfSx7IngiOjQwMi4wNTQ2ODc1LCJ5Ijo4N30seyJ4Ijo0MDIuMDU0Njg3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M502.305%2c52.971L533.944%2c58.642C565.583%2c64.314%2c628.862%2c75.657%2c660.501%2c84.828C692.141%2c94%2c692.141%2c101%2c692.141%2c104.5L692.141%2c108' id='mermaid-2-L_CW_S3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_CW_S3_0' data-points='W3sieCI6NTAyLjMwNDY4NzUsInkiOjUyLjk3MDUzNjc0ODI2OTY0fSx7IngiOjY5Mi4xNDA2MjUsInkiOjg3fSx7IngiOjY5Mi4xNDA2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M129.016%2c190L129.016%2c194.167C129.016%2c198.333%2c129.016%2c206.667%2c129.016%2c216.333C129.016%2c226%2c129.016%2c237%2c129.016%2c242.5L129.016%2c248' id='mermaid-2-L_S1_E1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S1_E1_0' data-points='W3sieCI6MTI5LjAxNTYyNSwieSI6MTkwfSx7IngiOjEyOS4wMTU2MjUsInkiOjIxNX0seyJ4IjoxMjkuMDE1NjI1LCJ5IjoyNTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M402.055%2c190L402.055%2c194.167C402.055%2c198.333%2c402.055%2c206.667%2c402.055%2c214.333C402.055%2c222%2c402.055%2c229%2c402.055%2c232.5L402.055%2c236' id='mermaid-2-L_S2_E2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_E2_0' data-points='W3sieCI6NDAyLjA1NDY4NzUsInkiOjE5MH0seyJ4Ijo0MDIuMDU0Njg3NSwieSI6MjE1fSx7IngiOjQwMi4wNTQ2ODc1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M692.141%2c190L692.141%2c194.167C692.141%2c198.333%2c692.141%2c206.667%2c692.141%2c214.333C692.141%2c222%2c692.141%2c229%2c692.141%2c232.5L692.141%2c236' id='mermaid-2-L_S3_E3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S3_E3_0' data-points='W3sieCI6NjkyLjE0MDYyNSwieSI6MTkwfSx7IngiOjY5Mi4xNDA2MjUsInkiOjIxNX0seyJ4Ijo2OTIuMTQwNjI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_CW_S1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_CW_S2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_CW_S3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S1_E1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S2_E2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S3_E3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-CW-0' data-look='classic' transform='translate(402.0546875%2c 35)'%3e%3crect class='basic label-container' style='' x='-100.25' y='-27' width='200.5' height='54'/%3e%3cg class='label' style='' transform='translate(-70.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='140.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContext window fills%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-S1-1' data-look='classic' transform='translate(129.015625%2c 151)'%3e%3crect class='basic label-container' style='' x='-66.46875' y='-39' width='132.9375' height='78'/%3e%3cg class='label' style='' transform='translate(-36.46875%2c -24)'%3e%3crect/%3e%3cforeignObject width='72.9375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStrategy 1%3cbr /%3eHard cut%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-S2-3' data-look='classic' transform='translate(402.0546875%2c 151)'%3e%3crect class='basic label-container' style='' x='-122.0390625' y='-39' width='244.078125' height='78'/%3e%3cg class='label' style='' transform='translate(-92.0390625%2c -24)'%3e%3crect/%3e%3cforeignObject width='184.078125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStrategy 2%3cbr /%3eSummarize old messages%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-S3-5' data-look='classic' transform='translate(692.140625%2c 151)'%3e%3crect class='basic label-container' style='' x='-118.046875' y='-39' width='236.09375' height='78'/%3e%3cg class='label' style='' transform='translate(-88.046875%2c -24)'%3e%3crect/%3e%3cforeignObject width='176.09375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStrategy 3%3cbr /%3eRetrieve relevant chunks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-E1-7' data-look='classic' transform='translate(129.015625%2c 279)'%3e%3crect class='basic label-container' style='' x='-121.015625' y='-27' width='242.03125' height='54'/%3e%3cg class='label' style='' transform='translate(-91.015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='182.03125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOldest messages drop off%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-E2-9' data-look='classic' transform='translate(402.0546875%2c 279)'%3e%3crect class='basic label-container' style='' x='-102.0234375' y='-39' width='204.046875' height='78'/%3e%3cg class='label' style='' transform='translate(-72.0234375%2c -24)'%3e%3crect/%3e%3cforeignObject width='144.046875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSummary reinserted%3cbr /%3eoriginals discarded%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-E3-11' data-look='classic' transform='translate(692.140625%2c 279)'%3e%3crect class='basic label-container' style='' x='-120.2734375' y='-39' width='240.546875' height='78'/%3e%3cg class='label' style='' transform='translate(-90.2734375%2c -24)'%3e%3crect/%3e%3cforeignObject width='180.546875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStash in searchable store%3cbr /%3efetch back when needed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-2-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- Hard cut. The oldest messages fall off. The model stops being able to see them, and the product, from your perspective, “forgets” the start of the chat.
- Summarization. The harness rewrites old messages as a short summary, reinserts that summary near the top, and drops the originals. Cheaper, but lossy.
- Retrieval. Older messages are stashed in a searchable store, and relevant bits are fetched back into context when the model needs them. We’ll meet this idea in post 4.
The important point for now: there is no magic. The model only ever sees what fits in the context window, and the context window is finite. Every “memory” feature you’ll meet in later posts is some variation of pretending to have a bigger window than you actually have.
Token-by-token generation
One more detail. The output is not generated whole, in one pass. It is generated one token at a time, and each new token is immediately fed back as input so the next token can be conditioned on it.
This is why streaming UIs work. It is also why models can seem to “change their mind” mid-sentence — they cannot revise what they’ve already written. Once a token is sampled, it is committed.
There is a small but real consequence: models are not great at producing text that depends on facts they’ve already stated incorrectly. If token 12 was a wrong number, tokens 13 onward will build on that wrong number. The only way out is to generate again from scratch.
It also means two decisions with lasting effects are made inside the sampling loop:
%3b%7d%23mermaid-3 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-3 .cluster text%7bfill:%23333%3b%7d%23mermaid-3 .cluster span%7bcolor:%23333%3b%7d%23mermaid-3 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-3 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-3 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-3 .icon-shape%2c%23mermaid-3 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-3 .icon-shape p%2c%23mermaid-3 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-3 .icon-shape .label rect%2c%23mermaid-3 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-3 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-3 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-3-gradient)%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M650%2c45.868L599.094%2c52.723C548.188%2c59.579%2c446.375%2c73.289%2c395.469%2c83.645C344.563%2c94%2c344.563%2c101%2c344.563%2c104.5L344.563%2c108' id='mermaid-3-L_Loop_Temp_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Loop_Temp_0' data-points='W3sieCI6NjUwLCJ5Ijo0NS44Njc5NjQyMjkzNTI5N30seyJ4IjozNDQuNTYyNSwieSI6ODd9LHsieCI6MzQ0LjU2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M811.406%2c51.344L840.75%2c57.287C870.094%2c63.229%2c928.781%2c75.115%2c958.125%2c84.557C987.469%2c94%2c987.469%2c101%2c987.469%2c104.5L987.469%2c108' id='mermaid-3-L_Loop_Stop_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Loop_Stop_0' data-points='W3sieCI6ODExLjQwNjI1LCJ5Ijo1MS4zNDM5NDIwNjc3OTA0Mn0seyJ4Ijo5ODcuNDY4NzUsInkiOjg3fSx7IngiOjk4Ny40Njg3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M250.078%2c158.787L224.441%2c164.156C198.805%2c169.525%2c147.531%2c180.262%2c121.895%2c189.131C96.258%2c198%2c96.258%2c205%2c96.258%2c208.5L96.258%2c212' id='mermaid-3-L_Temp_TL_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Temp_TL_0' data-points='W3sieCI6MjUwLjA3ODEyNSwieSI6MTU4Ljc4NjkzMDExOTg3NTR9LHsieCI6OTYuMjU3ODEyNSwieSI6MTkxfSx7IngiOjk2LjI1NzgxMjUsInkiOjIxNn1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M344.563%2c166L344.563%2c170.167C344.563%2c174.333%2c344.563%2c182.667%2c344.563%2c190.333C344.563%2c198%2c344.563%2c205%2c344.563%2c208.5L344.563%2c212' id='mermaid-3-L_Temp_TH_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Temp_TH_0' data-points='W3sieCI6MzQ0LjU2MjUsInkiOjE2Nn0seyJ4IjozNDQuNTYyNSwieSI6MTkxfSx7IngiOjM0NC41NjI1LCJ5IjoyMTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M439.047%2c157.745L466.983%2c163.288C494.919%2c168.83%2c550.792%2c179.915%2c578.728%2c190.958C606.664%2c202%2c606.664%2c213%2c606.664%2c218.5L606.664%2c224' id='mermaid-3-L_Temp_TX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Temp_TX_0' data-points='W3sieCI6NDM5LjA0Njg3NSwieSI6MTU3Ljc0NTM1NzUzNjczNzMyfSx7IngiOjYwNi42NjQwNjI1LCJ5IjoxOTF9LHsieCI6NjA2LjY2NDA2MjUsInkiOjIyOH1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M920.293%2c166L909.927%2c170.167C899.56%2c174.333%2c878.827%2c182.667%2c868.46%2c192.333C858.094%2c202%2c858.094%2c213%2c858.094%2c218.5L858.094%2c224' id='mermaid-3-L_Stop_SH_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Stop_SH_0' data-points='W3sieCI6OTIwLjI5MzI2OTIzMDc2OTMsInkiOjE2Nn0seyJ4Ijo4NTguMDkzNzUsInkiOjE5MX0seyJ4Ijo4NTguMDkzNzUsInkiOjIyOH1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M1054.644%2c166L1065.011%2c170.167C1075.377%2c174.333%2c1096.111%2c182.667%2c1106.477%2c192.333C1116.844%2c202%2c1116.844%2c213%2c1116.844%2c218.5L1116.844%2c224' id='mermaid-3-L_Stop_SN_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Stop_SN_0' data-points='W3sieCI6MTA1NC42NDQyMzA3NjkyMzA3LCJ5IjoxNjZ9LHsieCI6MTExNi44NDM3NSwieSI6MTkxfSx7IngiOjExMTYuODQzNzUsInkiOjIyOH1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Loop_Temp_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Loop_Stop_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Temp_TL_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Temp_TH_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Temp_TX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Stop_SH_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Stop_SN_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-3-flowchart-Loop-0' data-look='classic' transform='translate(730.703125%2c 35)'%3e%3crect class='basic label-container' style='' x='-80.703125' y='-27' width='161.40625' height='54'/%3e%3cg class='label' style='' transform='translate(-50.703125%2c -12)'%3e%3crect/%3e%3cforeignObject width='101.40625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSampling loop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-Temp-1' data-look='classic' transform='translate(344.5625%2c 139)'%3e%3crect class='basic label-container' style='' x='-94.484375' y='-27' width='188.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-64.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTemperature knob%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-Stop-3' data-look='classic' transform='translate(987.46875%2c 139)'%3e%3crect class='basic label-container' style='' x='-72.25' y='-27' width='144.5' height='54'/%3e%3cg class='label' style='' transform='translate(-42.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='84.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStop tokens%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-TL-5' data-look='classic' transform='translate(96.2578125%2c 255)'%3e%3crect class='basic label-container' style='' x='-88.2578125' y='-39' width='176.515625' height='78'/%3e%3cg class='label' style='' transform='translate(-58.2578125%2c -24)'%3e%3crect/%3e%3cforeignObject width='116.515625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLow: predictable%3cbr /%3egood for code%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-TH-7' data-look='classic' transform='translate(344.5625%2c 255)'%3e%3crect class='basic label-container' style='' x='-110.046875' y='-39' width='220.09375' height='78'/%3e%3cg class='label' style='' transform='translate(-80.046875%2c -24)'%3e%3crect/%3e%3cforeignObject width='160.09375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eHigh: creative%3cbr /%3egood for brainstorming%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-TX-9' data-look='classic' transform='translate(606.6640625%2c 255)'%3e%3crect class='basic label-container' style='' x='-102.0546875' y='-27' width='204.109375' height='54'/%3e%3cg class='label' style='' transform='translate(-72.0546875%2c -12)'%3e%3crect/%3e%3cforeignObject width='144.109375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eToo high: incoherent%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-SH-11' data-look='classic' transform='translate(858.09375%2c 255)'%3e%3crect class='basic label-container' style='' x='-99.375' y='-27' width='198.75' height='54'/%3e%3cg class='label' style='' transform='translate(-69.375%2c -12)'%3e%3crect/%3e%3cforeignObject width='138.75' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eHalt when triggered%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-SN-13' data-look='classic' transform='translate(1116.84375%2c 255)'%3e%3crect class='basic label-container' style='' x='-109.375' y='-27' width='218.75' height='54'/%3e%3cg class='label' style='' transform='translate(-79.375%2c -12)'%3e%3crect/%3e%3cforeignObject width='158.75' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo stop = runs forever%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-3-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- Temperature — how “creative” the sampling is. Near zero, the model picks the most likely token almost every time and behaves predictably (good for code, classification). Higher up, it samples from less-likely tokens (good for brainstorming, poetry). Too high, it gets incoherent.
- Stop tokens — signals that tell the loop to halt. Without good stop conditions, a model might happily keep going forever, especially on open-ended prompts.
Neither of these is the model itself. They are knobs on the harness. But they profoundly shape how the model appears to behave.
What this substrate can and cannot do
Given all of the above, here is an honest capability sheet for a pure chat baseline:
%3b%7d%23mermaid-4 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-4 .cluster text%7bfill:%23333%3b%7d%23mermaid-4 .cluster span%7bcolor:%23333%3b%7d%23mermaid-4 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-4 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-4 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-4 .icon-shape%2c%23mermaid-4 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-4 .icon-shape p%2c%23mermaid-4 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-4 .icon-shape .label rect%2c%23mermaid-4 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-4 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-4 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-4 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node rect%2c%23mermaid-4 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-4 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-4-gradient)%3bstroke-width:1px%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-4-subGraph1' data-look='classic'%3e%3crect style='' x='8' y='8' width='1350.8125' height='129'/%3e%3cg class='cluster-label' transform='translate(645.15625%2c 8)'%3e%3cforeignObject width='76.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCannot Do%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-4-flowchart-ND1-4' data-look='classic' transform='translate(147.28125%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-104.28125' y='-27' width='208.5625' height='54'/%3e%3cg class='label' style='' transform='translate(-74.28125%2c -12)'%3e%3crect/%3e%3cforeignObject width='148.5625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLook up outside data%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-ND2-5' data-look='classic' transform='translate(386.2578125%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-84.6953125' y='-27' width='169.390625' height='54'/%3e%3cg class='label' style='' transform='translate(-54.6953125%2c -12)'%3e%3crect/%3e%3cforeignObject width='109.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAct in the world%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-ND3-6' data-look='classic' transform='translate(649.65625%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-128.703125' y='-27' width='257.40625' height='54'/%3e%3cg class='label' style='' transform='translate(-98.703125%2c -12)'%3e%3crect/%3e%3cforeignObject width='197.40625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRemember across sessions%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-ND4-7' data-look='classic' transform='translate(939.28125%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-110.921875' y='-27' width='221.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-80.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='161.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eKnow if answer correct%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-ND5-8' data-look='classic' transform='translate(1212.0078125%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-111.8046875' y='-27' width='223.609375' height='54'/%3e%3cg class='label' style='' transform='translate(-81.8046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='163.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCatch its own mistakes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(124.359375%2c 179)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-4-subGraph0' data-look='classic'%3e%3crect style='' x='8' y='8' width='1102.09375' height='129'/%3e%3cg class='cluster-label' transform='translate(531.921875%2c 8)'%3e%3cforeignObject width='54.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCan Do%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-4-flowchart-CD1-0' data-look='classic' transform='translate(164.609375%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-121.609375' y='-27' width='243.21875' height='54'/%3e%3cg class='label' style='' transform='translate(-91.609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='183.21875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAnswer training questions%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-CD2-1' data-look='classic' transform='translate(447.140625%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-110.921875' y='-27' width='221.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-80.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='161.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMulti-turn conversation%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-CD3-2' data-look='classic' transform='translate(703.8671875%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-95.8046875' y='-27' width='191.609375' height='54'/%3e%3cg class='label' style='' transform='translate(-65.8046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='131.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFollow instructions%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-CD4-3' data-look='classic' transform='translate(962.3828125%2c 72.5)'%3e%3crect class='basic label-container' style='' x='-112.7109375' y='-27' width='225.421875' height='54'/%3e%3cg class='label' style='' transform='translate(-82.7109375%2c -12)'%3e%3crect/%3e%3cforeignObject width='165.421875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eProduce structured text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-4-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Can do:
- Answer one-turn questions about anything in the model’s training data.
- Carry on a multi-turn conversation, with memory degrading gracefully as the context fills.
- Follow instructions embedded in the prompt (“be concise”, “answer in French”).
- Produce structured text when asked (JSON, code, tables) — though without checks on whether it’s correct.
Cannot do:
- Look up anything outside the prompt it has been given.
- Take any action in the outside world.
- Remember anything across separate chats or sessions.
- Know whether its answer is correct — or admit, reliably, when it doesn’t know.
- Catch its own mistakes after they happen.
Almost every feature added in the rest of this series is a response to one of those limits. RAG fixes “can’t look anything up.” Tool use fixes “can’t take any action.” Memory fixes “can’t remember across sessions.” Agent loops fix “can’t catch its own mistakes.”
The floor is real, and it is small. That is why the tower matters.
The honest diagnostic
If someone tells you a product is “just a better chatbot,” you can test the claim with four questions:
%3b%7d%23mermaid-5 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-5 .cluster text%7bfill:%23333%3b%7d%23mermaid-5 .cluster span%7bcolor:%23333%3b%7d%23mermaid-5 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-5 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-5 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-5 .icon-shape%2c%23mermaid-5 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-5 .icon-shape p%2c%23mermaid-5 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-5 .icon-shape .label rect%2c%23mermaid-5 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-5 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-5 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-5 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node rect%2c%23mermaid-5 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-5 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-5-gradient)%3bstroke-width:1px%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M196.294%2c224.473L183.252%2c240.894C170.211%2c257.316%2c144.129%2c290.158%2c131.088%2c327.496C118.047%2c364.833%2c118.047%2c406.667%2c118.047%2c427.583L118.047%2c448.5' id='mermaid-5-L_Q1_A1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q1_A1_0' data-points='W3sieCI6MTk2LjI5MzU4MDAyMjY5OTczLCJ5IjoyMjQuNDczMjY3NTIyNjk5NzN9LHsieCI6MTE4LjA0Njg3NSwieSI6MzIzfSx7IngiOjExOC4wNDY4NzUsInkiOjQ1Mi41fV0=' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M319.347%2c224.473L332.388%2c240.894C345.429%2c257.316%2c371.512%2c290.158%2c384.553%2c312.079C397.594%2c334%2c397.594%2c345%2c397.594%2c350.5L397.594%2c356' id='mermaid-5-L_Q1_Q2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q1_Q2_0' data-points='W3sieCI6MzE5LjM0NzA0NDk3NzMwMDMsInkiOjIyNC40NzMyNjc1MjI2OTk3M30seyJ4IjozOTcuNTkzNzUsInkiOjMyM30seyJ4IjozOTcuNTkzNzUsInkiOjM2MH1d' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M344.562%2c545.968L332.59%2c560.974C320.618%2c575.979%2c296.674%2c605.989%2c284.702%2c640.426C272.73%2c674.862%2c272.73%2c713.724%2c272.73%2c733.155L272.73%2c752.586' id='mermaid-5-L_Q2_A2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q2_A2_0' data-points='W3sieCI6MzQ0LjU2MjA4OTE0MTE3OTIzLCJ5Ijo1NDUuOTY4MzM5MTQxMTc5M30seyJ4IjoyNzIuNzMwNDY4NzUsInkiOjYzNn0seyJ4IjoyNzIuNzMwNDY4NzUsInkiOjc1Ni41ODU5Mzc1fV0=' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M450.625%2c545.968L462.597%2c560.974C474.569%2c575.979%2c498.513%2c605.989%2c510.485%2c626.495C522.457%2c647%2c522.457%2c658%2c522.457%2c663.5L522.457%2c669' id='mermaid-5-L_Q2_Q3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q2_Q3_0' data-points='W3sieCI6NDUwLjYyNTQxMDg1ODgyMDc3LCJ5Ijo1NDUuOTY4MzM5MTQxMTc5M30seyJ4Ijo1MjIuNDU3MDMxMjUsInkiOjYzNn0seyJ4Ijo1MjIuNDU3MDMxMjUsInkiOjY3M31d' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M470.579%2c842.293L457.489%2c857.107C444.399%2c871.92%2c418.219%2c901.546%2c405.129%2c937.568C392.039%2c973.591%2c392.039%2c1016.01%2c392.039%2c1037.22L392.039%2c1058.43' id='mermaid-5-L_Q3_A3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q3_A3_0' data-points='W3sieCI6NDcwLjU3ODY0NzQ2ODk2NDczLCJ5Ijo4NDIuMjkzNDkxMjE4OTY0N30seyJ4IjozOTIuMDM5MDYyNSwieSI6OTMxLjE3MTg3NX0seyJ4IjozOTIuMDM5MDYyNSwieSI6MTA2Mi40Mjk2ODc1fV0=' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M574.335%2c842.293L587.425%2c857.107C600.515%2c871.92%2c626.695%2c901.546%2c639.785%2c921.859C652.875%2c942.172%2c652.875%2c953.172%2c652.875%2c958.672L652.875%2c964.172' id='mermaid-5-L_Q3_Q4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q3_Q4_0' data-points='W3sieCI6NTc0LjMzNTQxNTAzMTAzNTMsInkiOjg0Mi4yOTM0OTEyMTg5NjQ3fSx7IngiOjY1Mi44NzUsInkiOjkzMS4xNzE4NzV9LHsieCI6NjUyLjg3NSwieSI6OTY4LjE3MTg3NX1d' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M602.351%2c1160.164L591.932%2c1174.751C581.513%2c1189.338%2c560.674%2c1218.513%2c550.255%2c1238.6C539.836%2c1258.688%2c539.836%2c1269.688%2c539.836%2c1275.188L539.836%2c1280.688' id='mermaid-5-L_Q4_A4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q4_A4_0' data-points='W3sieCI6NjAyLjM1MTQ5MzQzMjUxNDUsInkiOjExNjAuMTYzOTkzNDMyNTE0Nn0seyJ4Ijo1MzkuODM1OTM3NSwieSI6MTI0Ny42ODc1fSx7IngiOjUzOS44MzU5Mzc1LCJ5IjoxMjg0LjY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M703.399%2c1160.164L713.818%2c1174.751C724.237%2c1189.338%2c745.076%2c1218.513%2c755.495%2c1238.6C765.914%2c1258.688%2c765.914%2c1269.688%2c765.914%2c1275.188L765.914%2c1280.688' id='mermaid-5-L_Q4_A5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q4_A5_0' data-points='W3sieCI6NzAzLjM5ODUwNjU2NzQ4NTUsInkiOjExNjAuMTYzOTkzNDMyNTE0Nn0seyJ4Ijo3NjUuOTE0MDYyNSwieSI6MTI0Ny42ODc1fSx7IngiOjc2NS45MTQwNjI1LCJ5IjoxMjg0LjY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(118.046875%2c 323)'%3e%3cg class='label' data-id='L_Q1_A1_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(397.59375%2c 323)'%3e%3cg class='label' data-id='L_Q1_Q2_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(272.73046875%2c 636)'%3e%3cg class='label' data-id='L_Q2_A2_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(522.45703125%2c 636)'%3e%3cg class='label' data-id='L_Q2_Q3_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(392.0390625%2c 931.171875)'%3e%3cg class='label' data-id='L_Q3_A3_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(652.875%2c 931.171875)'%3e%3cg class='label' data-id='L_Q3_Q4_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(539.8359375%2c 1247.6875)'%3e%3cg class='label' data-id='L_Q4_A4_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(765.9140625%2c 1247.6875)'%3e%3cg class='label' data-id='L_Q4_A5_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-5-flowchart-Q1-0' data-look='classic' transform='translate(257.8203125%2c 147)'%3e%3cpolygon points='139%2c0 278%2c-139 139%2c-278 0%2c-139' class='label-container' transform='translate(-138.5%2c 139)'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDoes more than produce text%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-A1-2' data-look='classic' transform='translate(118.046875%2c 479.5)'%3e%3crect class='basic label-container' style='' x='-110.046875' y='-27' width='220.09375' height='54'/%3e%3cg class='label' style='' transform='translate(-80.046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='160.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRung 1 LLM Core only%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-Q2-4' data-look='classic' transform='translate(397.59375%2c 479.5)'%3e%3cpolygon points='119.5%2c0 239%2c-119.5 119.5%2c-239 0%2c-119.5' class='label-container' transform='translate(-119%2c 119.5)'/%3e%3cg class='label' style='' transform='translate(-92.5%2c -12)'%3e%3crect/%3e%3cforeignObject width='185' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eKnows post-training data%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-A2-6' data-look='classic' transform='translate(272.73046875%2c 783.5859375)'%3e%3crect class='basic label-container' style='' x='-89.140625' y='-27' width='178.28125' height='54'/%3e%3cg class='label' style='' transform='translate(-59.140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='118.28125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo retrieval rung%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-Q3-8' data-look='classic' transform='translate(522.45703125%2c 783.5859375)'%3e%3cpolygon points='110.5859375%2c0 221.171875%2c-110.5859375 110.5859375%2c-221.171875 0%2c-110.5859375' class='label-container' transform='translate(-110.0859375%2c 110.5859375)'/%3e%3cg class='label' style='' transform='translate(-83.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='167.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRemembers last week%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-A3-10' data-look='classic' transform='translate(392.0390625%2c 1089.4296875)'%3e%3crect class='basic label-container' style='' x='-89.578125' y='-27' width='179.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-59.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='119.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo memory rung%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-Q4-12' data-look='classic' transform='translate(652.875%2c 1089.4296875)'%3e%3cpolygon points='121.2578125%2c0 242.515625%2c-121.2578125 121.2578125%2c-242.515625 0%2c-121.2578125' class='label-container' transform='translate(-120.7578125%2c 121.2578125)'/%3e%3cg class='label' style='' transform='translate(-94.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='188.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNotices and retries errors%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-A4-14' data-look='classic' transform='translate(539.8359375%2c 1311.6875)'%3e%3crect class='basic label-container' style='' x='-79.8203125' y='-27' width='159.640625' height='54'/%3e%3cg class='label' style='' transform='translate(-49.8203125%2c -12)'%3e%3crect/%3e%3cforeignObject width='99.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo agent loop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-A5-16' data-look='classic' transform='translate(765.9140625%2c 1311.6875)'%3e%3crect class='basic label-container' style='' x='-96.2578125' y='-27' width='192.515625' height='54'/%3e%3cg class='label' style='' transform='translate(-66.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='132.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFull rung coverage%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-5-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- Can it do anything other than produce text? If no, you’re at this rung.
- Does it know about things that happened after its training cutoff? If no, no retrieval rung.
- Does it remember what you told it in a conversation last week? If no, no memory rung.
- If it gives a wrong answer, does it notice and retry? If no, no agent loop.
A clean “no” to all four is not a failure — it just means the product lives at the chat baseline, and you should evaluate it on baseline terms: does it produce text that is genuinely useful to you in a single turn?
Most products that feel magical have climbed at least to rung 3 or 4. Almost none of them advertise clearly which rungs they’ve built. This series is, in part, a way to ask them better questions.
Where we go next
The cheapest, highest-leverage thing you can do to a chat baseline without climbing further is to write a serious system prompt. That’s the next post, and it’s where most products get far more value than people credit — or fail to, and then blame the model.
Read next: System Prompts & Personas: The Cheapest Control Surface.