At the last rung, we gave the model hands. It can now call a tool, read a file, send an email, query a database, run a piece of code. But every example in that post was a single call — the model decides to do one thing, the harness does it, the result comes back, and the model composes a reply.
Most real work is not one thing. It is a sequence.
“Find me a flight to Tokyo next Wednesday under $800 that leaves after 9 AM.” That request, on inspection, is four tool calls long and requires looking at results between each one. If the flight search returns no matches, the model should notice, widen the date range, and try again. If the budget’s too tight, it should say so rather than silently giving up. The work is not a call. It is a loop.
This rung is that loop.
From one call to a loop
If the previous post’s mental model was offer → decide → execute → feed back, the agent loop is that cycle running multiple times per user turn, until the goal is genuinely done.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-AgentLoop' data-look='classic'%3e%3crect style='' x='8' y='8' width='972.296875' height='293.578125'/%3e%3cg class='cluster-label' transform='translate(455.890625%2c 8)'%3e%3cforeignObject width='76.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAgent loop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M173.984%2c164.789L180.234%2c164.789C186.484%2c164.789%2c198.984%2c164.789%2c210.818%2c164.789C222.651%2c164.789%2c233.818%2c164.789%2c239.401%2c164.789L244.984%2c164.789' id='mermaid-0-L_B1_B2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B1_B2_0' data-points='W3sieCI6MTczLjk4NDM3NSwieSI6MTY0Ljc4OTA2MjV9LHsieCI6MjExLjQ4NDM3NSwieSI6MTY0Ljc4OTA2MjV9LHsieCI6MjQ4Ljk4NDM3NSwieSI6MTY0Ljc4OTA2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M321.594%2c137.789L333.005%2c122.991C344.417%2c108.193%2c367.24%2c78.596%2c393.331%2c63.798C419.422%2c49%2c448.781%2c49%2c480.216%2c49C511.651%2c49%2c545.161%2c49%2c570.919%2c50.618C596.677%2c52.236%2c614.683%2c55.471%2c623.685%2c57.089L632.688%2c58.707' id='mermaid-0-L_B2_B3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B2_B3_0' data-points='W3sieCI6MzIxLjU5NDA5NzM3NDUwMjQsInkiOjEzNy43ODkwNjI1fSx7IngiOjM5MC4wNjI1LCJ5Ijo0OX0seyJ4Ijo0NzguMTQwNjI1LCJ5Ijo0OX0seyJ4Ijo1NzguNjcxODc1LCJ5Ijo0OX0seyJ4Ijo2MzYuNjI1LCJ5Ijo1OS40MTQzNjAyMDg1ODQwMzZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M754.438%2c70L762.021%2c70C769.604%2c70%2c784.771%2c70%2c802.643%2c80.815C820.516%2c91.63%2c841.095%2c113.261%2c851.384%2c124.076L861.673%2c134.891' id='mermaid-0-L_B3_B4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B3_B4_0' data-points='W3sieCI6NzU0LjQzNzUsInkiOjcwfSx7IngiOjc5OS45Mzc1LCJ5Ijo3MH0seyJ4Ijo4NjQuNDMwMTM1NjU3OTE2NSwieSI6MTM3Ljc4OTA2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M864.698%2c191.789L853.905%2c203.254C843.111%2c214.719%2c821.524%2c237.648%2c793.33%2c249.113C765.135%2c260.578%2c730.333%2c260.578%2c693.456%2c260.578C656.578%2c260.578%2c617.625%2c260.578%2c581.393%2c260.578C545.161%2c260.578%2c511.651%2c260.578%2c480.216%2c260.578C448.781%2c260.578%2c419.422%2c260.578%2c394.51%2c249.601C369.598%2c238.624%2c349.133%2c216.669%2c338.901%2c205.692L328.669%2c194.715' id='mermaid-0-L_B4_B2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B4_B2_0' data-points='W3sieCI6ODY0LjY5ODI5ODMzOTI0NjQsInkiOjE5MS43ODkwNjI1fSx7IngiOjc5OS45Mzc1LCJ5IjoyNjAuNTc4MTI1fSx7IngiOjY5NS41MzEyNSwieSI6MjYwLjU3ODEyNX0seyJ4Ijo1NzguNjcxODc1LCJ5IjoyNjAuNTc4MTI1fSx7IngiOjQ3OC4xNDA2MjUsInkiOjI2MC41NzgxMjV9LHsieCI6MzkwLjA2MjUsInkiOjI2MC41NzgxMjV9LHsieCI6MzI1Ljk0MTI4Njc3ODE5OTIsInkiOjE5MS43ODkwNjI1fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M352.563%2c164.789L358.813%2c164.789C365.063%2c164.789%2c377.563%2c164.789%2c389.396%2c164.789C401.229%2c164.789%2c412.396%2c164.789%2c417.979%2c164.789L423.563%2c164.789' id='mermaid-0-L_B2_B5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B2_B5_0' data-points='W3sieCI6MzUyLjU2MjUsInkiOjE2NC43ODkwNjI1fSx7IngiOjM5MC4wNjI1LCJ5IjoxNjQuNzg5MDYyNX0seyJ4Ijo0MjcuNTYyNSwieSI6MTY0Ljc4OTA2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M511.476%2c147.546L522.675%2c141.753C533.875%2c135.961%2c556.273%2c124.375%2c576.505%2c115.274C596.738%2c106.174%2c614.803%2c99.559%2c623.836%2c96.252L632.869%2c92.944' id='mermaid-0-L_B5_B3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B5_B3_0' data-points='W3sieCI6NTExLjQ3NTk3MTg4MDc2MjEzLCJ5IjoxNDcuNTQ2Mjg0MzgwNzYyMTN9LHsieCI6NTc4LjY3MTg3NSwieSI6MTEyLjc4OTA2MjV9LHsieCI6NjM2LjYyNSwieSI6OTEuNTY5MDI4Njk3MDE4MzN9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M519.638%2c173.87L529.477%2c176.023C539.316%2c178.176%2c558.994%2c182.483%2c576.492%2c184.636C593.99%2c186.789%2c609.307%2c186.789%2c616.966%2c186.789L624.625%2c186.789' id='mermaid-0-L_B5_B6_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B5_B6_0' data-points='W3sieCI6NTE5LjYzNzY0ODI0MDI0NDksInkiOjE3My44NzAxNjQyNTk3NTUxN30seyJ4Ijo1NzguNjcxODc1LCJ5IjoxODYuNzg5MDYyNX0seyJ4Ijo2MjguNjI1LCJ5IjoxODYuNzg5MDYyNX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B1_B2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B2_B3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B3_B4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B4_B2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B2_B5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(572.48239%2c 115.99059)'%3e%3cg class='label' data-id='L_B5_B3_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(578.671875%2c 186.7890625)'%3e%3cg class='label' data-id='L_B5_B6_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-B1-8' data-look='classic' transform='translate(109.7421875%2c 164.7890625)'%3e%3crect class='basic label-container' style='' x='-64.2421875' y='-27' width='128.484375' height='54'/%3e%3cg class='label' style='' transform='translate(-34.2421875%2c -12)'%3e%3crect/%3e%3cforeignObject width='68.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser goal%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B2-9' data-look='classic' transform='translate(300.7734375%2c 164.7890625)'%3e%3crect class='basic label-container' style='' x='-51.7890625' y='-27' width='103.578125' height='54'/%3e%3cg class='label' style='' transform='translate(-21.7890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='43.578125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModel%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B3-11' data-look='classic' transform='translate(695.53125%2c 70)'%3e%3crect class='basic label-container' style='' x='-58.90625' y='-27' width='117.8125' height='54'/%3e%3cg class='label' style='' transform='translate(-28.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='57.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B4-13' data-look='classic' transform='translate(890.1171875%2c 164.7890625)'%3e%3crect class='basic label-container' style='' x='-52.6796875' y='-27' width='105.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-22.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='45.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eResult%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B5-17' data-look='classic' transform='translate(478.140625%2c 164.7890625)'%3e%3cpolygon points='50.578125%2c0 101.15625%2c-50.578125 50.578125%2c-101.15625 0%2c-50.578125' class='label-container' transform='translate(-50.078125%2c 50.578125)'/%3e%3cg class='label' style='' transform='translate(-23.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='47.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDone%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B6-21' data-look='classic' transform='translate(695.53125%2c 186.7890625)'%3e%3crect class='basic label-container' style='' x='-66.90625' y='-27' width='133.8125' height='54'/%3e%3cg class='label' style='' transform='translate(-36.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='73.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFinal reply%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1022.296875%2c 84.7890625)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-Single' data-look='classic'%3e%3crect style='' x='8' y='8' width='965.8125' height='124'/%3e%3cg class='cluster-label' transform='translate(454.4375%2c 8)'%3e%3cforeignObject width='72.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSingle call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M208.656%2c70L214.906%2c70C221.156%2c70%2c233.656%2c70%2c245.49%2c70C257.323%2c70%2c268.49%2c70%2c274.073%2c70L279.656%2c70' id='mermaid-0-L_A1_A2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A1_A2_0' data-points='W3sieCI6MjA4LjY1NjI1LCJ5Ijo3MH0seyJ4IjoyNDYuMTU2MjUsInkiOjcwfSx7IngiOjI4My42NTYyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M387.234%2c70L393.484%2c70C399.734%2c70%2c412.234%2c70%2c424.068%2c70C435.901%2c70%2c447.068%2c70%2c452.651%2c70L458.234%2c70' id='mermaid-0-L_A2_A3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A2_A3_0' data-points='W3sieCI6Mzg3LjIzNDM3NSwieSI6NzB9LHsieCI6NDI0LjczNDM3NSwieSI6NzB9LHsieCI6NDYyLjIzNDM3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M580.047%2c70L586.297%2c70C592.547%2c70%2c605.047%2c70%2c616.88%2c70C628.714%2c70%2c639.88%2c70%2c645.464%2c70L651.047%2c70' id='mermaid-0-L_A3_A4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A3_A4_0' data-points='W3sieCI6NTgwLjA0Njg3NSwieSI6NzB9LHsieCI6NjE3LjU0Njg3NSwieSI6NzB9LHsieCI6NjU1LjA0Njg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M760.406%2c70L766.656%2c70C772.906%2c70%2c785.406%2c70%2c797.24%2c70C809.073%2c70%2c820.24%2c70%2c825.823%2c70L831.406%2c70' id='mermaid-0-L_A4_A5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A4_A5_0' data-points='W3sieCI6NzYwLjQwNjI1LCJ5Ijo3MH0seyJ4Ijo3OTcuOTA2MjUsInkiOjcwfSx7IngiOjgzNS40MDYyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A1_A2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A2_A3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A3_A4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A4_A5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-A1-0' data-look='classic' transform='translate(127.078125%2c 70)'%3e%3crect class='basic label-container' style='' x='-81.578125' y='-27' width='163.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-51.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='103.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser message%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A2-1' data-look='classic' transform='translate(335.4453125%2c 70)'%3e%3crect class='basic label-container' style='' x='-51.7890625' y='-27' width='103.578125' height='54'/%3e%3cg class='label' style='' transform='translate(-21.7890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='43.578125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModel%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A3-3' data-look='classic' transform='translate(521.140625%2c 70)'%3e%3crect class='basic label-container' style='' x='-58.90625' y='-27' width='117.8125' height='54'/%3e%3cg class='label' style='' transform='translate(-28.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='57.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A4-5' data-look='classic' transform='translate(707.7265625%2c 70)'%3e%3crect class='basic label-container' style='' x='-52.6796875' y='-27' width='105.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-22.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='45.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eResult%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A5-7' data-look='classic' transform='translate(885.859375%2c 70)'%3e%3crect class='basic label-container' style='' x='-50.453125' y='-27' width='100.90625' height='54'/%3e%3cg class='label' style='' transform='translate(-20.453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='40.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReply%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
The model is not “an agent” by virtue of being smart. It’s an agent by virtue of being embedded in this outer loop. The same model that behaves as a chatbot when called once behaves as an agent when called in a loop. The difference is not in the model; it is in the scaffolding.
A minimal agent loop, in pseudocode:
context = [system_prompt, user_goal]
while True: response = model.generate(context, tools=TOOLS)
if response.is_text(): return response.text # done — model is replying
if response.is_tool_call(): result = run_tool(response.tool, response.input) context.append(response) # record the call context.append(result) # record the result continue # loop back
if response.asks_for_clarification(): return response.text # surface the question to the userThat’s the whole thing. An agent is literally a few dozen lines of Python around the model call from post 5.
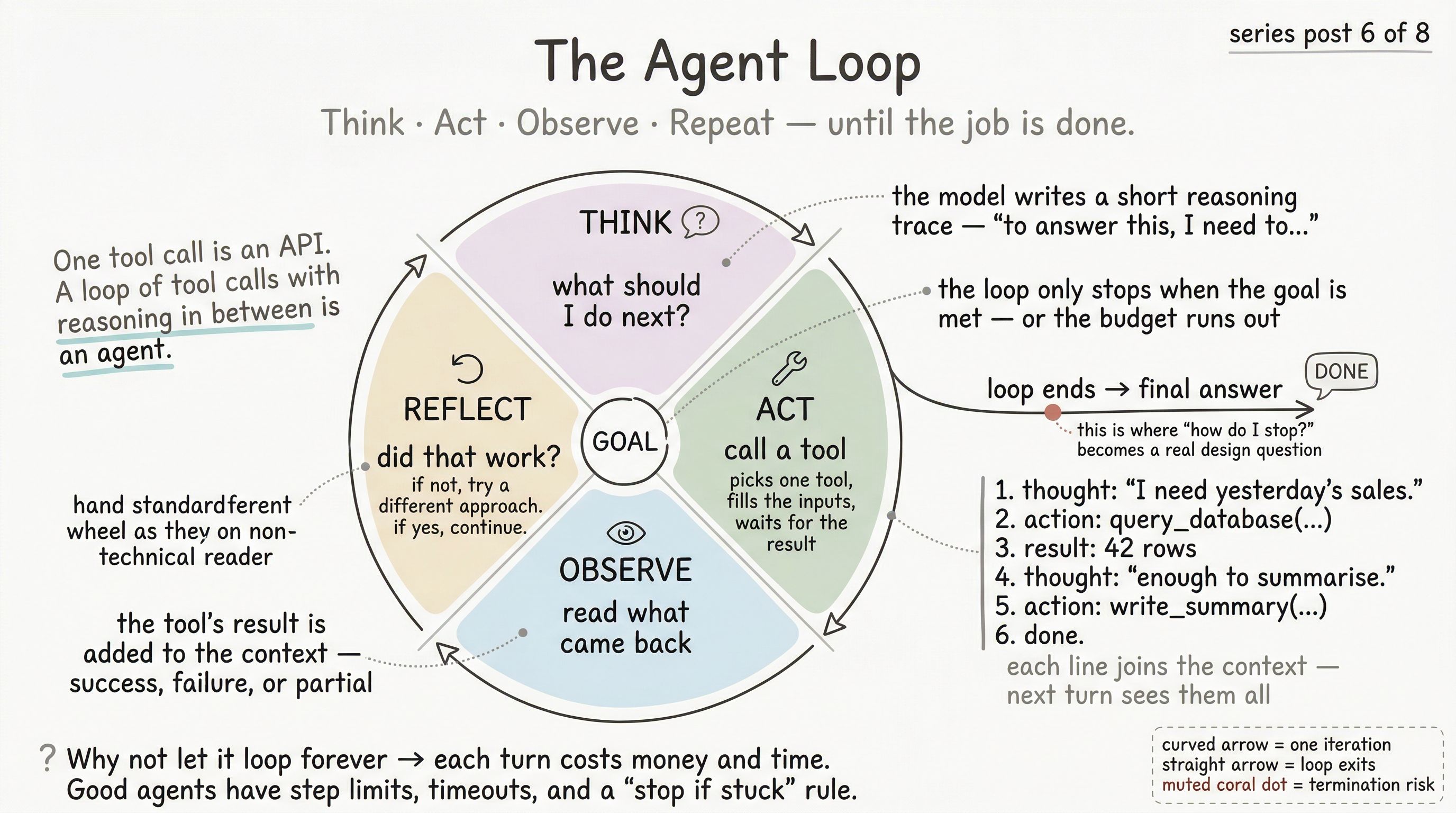
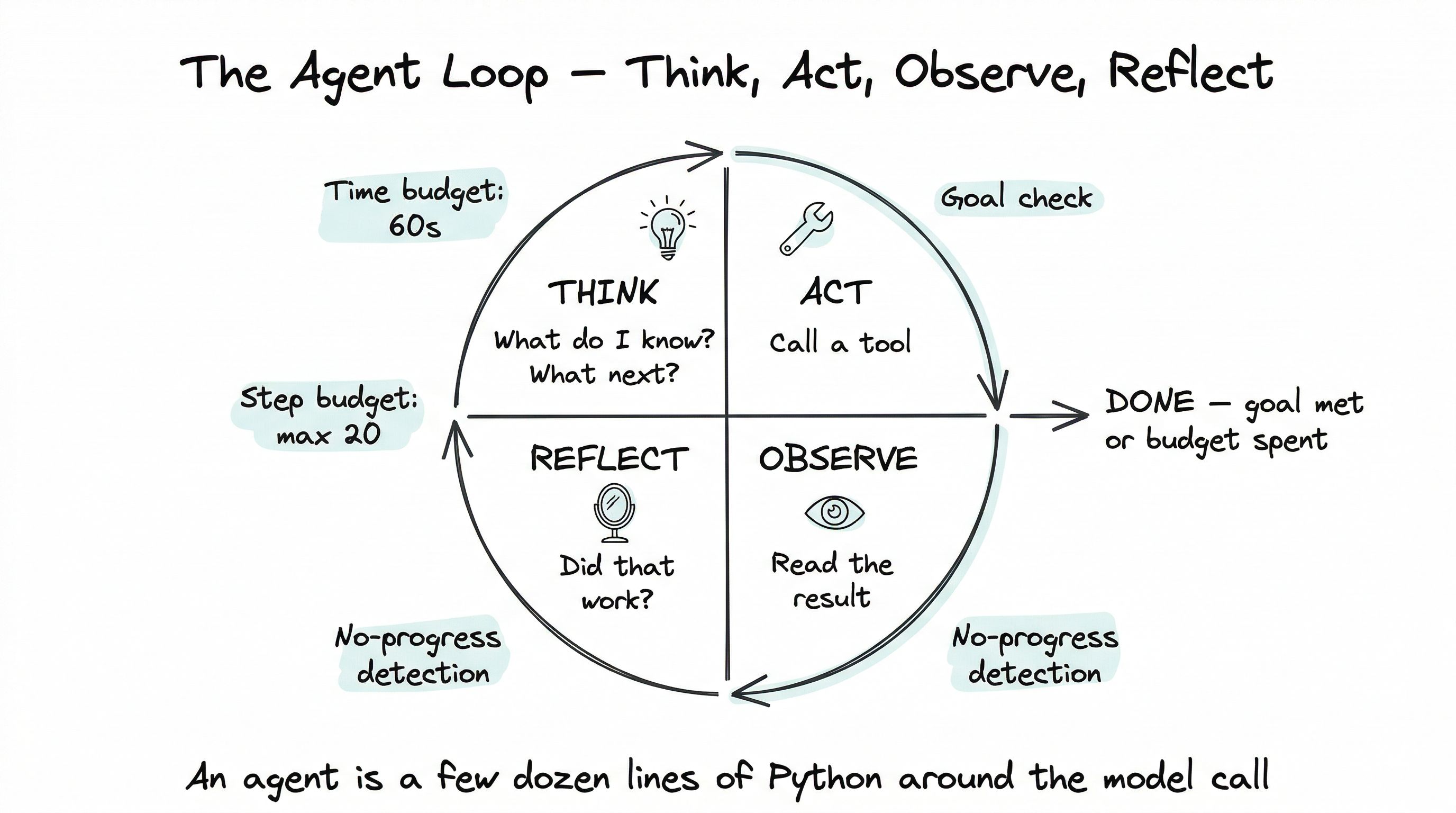
The four-step cycle, named
The loop above has a name in the AI literature: ReAct (short for “Reason + Act”), introduced in a 2022 paper and since adopted as the default mental model for simple agents. The idea is that the model interleaves two kinds of outputs:
%3b%7d%23mermaid-1 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M117.67%2c86L113.73%2c90.167C109.791%2c94.333%2c101.911%2c102.667%2c97.971%2c110.333C94.031%2c118%2c94.031%2c125%2c94.031%2c128.5L94.031%2c132' id='mermaid-1-L_TH_AC_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TH_AC_0' data-points='W3sieCI6MTE3LjY3MDE2NjAxNTYyNSwieSI6ODZ9LHsieCI6OTQuMDMxMjUsInkiOjExMX0seyJ4Ijo5NC4wMzEyNSwieSI6MTM2fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M94.031%2c214L94.031%2c218.167C94.031%2c222.333%2c94.031%2c230.667%2c94.031%2c238.333C94.031%2c246%2c94.031%2c253%2c94.031%2c256.5L94.031%2c260' id='mermaid-1-L_AC_OB_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AC_OB_0' data-points='W3sieCI6OTQuMDMxMjUsInkiOjIxNH0seyJ4Ijo5NC4wMzEyNSwieSI6MjM5fSx7IngiOjk0LjAzMTI1LCJ5IjoyNjR9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M94.031%2c342L94.031%2c346.167C94.031%2c350.333%2c94.031%2c358.667%2c97.513%2c366.516C100.995%2c374.365%2c107.958%2c381.729%2c111.44%2c385.411L114.922%2c389.094' id='mermaid-1-L_OB_RF_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_OB_RF_0' data-points='W3sieCI6OTQuMDMxMjUsInkiOjM0Mn0seyJ4Ijo5NC4wMzEyNSwieSI6MzY3fSx7IngiOjExNy42NzAxNjYwMTU2MjUsInkiOjM5Mn1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M191.424%2c392L195.363%2c387.833C199.303%2c383.667%2c207.183%2c375.333%2c211.123%2c360.5C215.063%2c345.667%2c215.063%2c324.333%2c215.063%2c303C215.063%2c281.667%2c215.063%2c260.333%2c215.063%2c239C215.063%2c217.667%2c215.063%2c196.333%2c215.063%2c175C215.063%2c153.667%2c215.063%2c132.333%2c211.581%2c117.984C208.099%2c103.635%2c201.135%2c96.271%2c197.654%2c92.589L194.172%2c88.906' id='mermaid-1-L_RF_TH_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RF_TH_0' data-points='W3sieCI6MTkxLjQyMzU4Mzk4NDM3NSwieSI6MzkyfSx7IngiOjIxNS4wNjI1LCJ5IjozNjd9LHsieCI6MjE1LjA2MjUsInkiOjMwM30seyJ4IjoyMTUuMDYyNSwieSI6MjM5fSx7IngiOjIxNS4wNjI1LCJ5IjoxNzV9LHsieCI6MjE1LjA2MjUsInkiOjExMX0seyJ4IjoxOTEuNDIzNTgzOTg0Mzc1LCJ5Ijo4Nn1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M154.547%2c470L154.547%2c474.167C154.547%2c478.333%2c154.547%2c486.667%2c154.547%2c494.333C154.547%2c502%2c154.547%2c509%2c154.547%2c512.5L154.547%2c516' id='mermaid-1-L_RF_DN_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RF_DN_0' data-points='W3sieCI6MTU0LjU0Njg3NSwieSI6NDcwfSx7IngiOjE1NC41NDY4NzUsInkiOjQ5NX0seyJ4IjoxNTQuNTQ2ODc1LCJ5Ijo1MjB9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TH_AC_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AC_OB_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_OB_RF_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_RF_TH_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_RF_DN_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-TH-0' data-look='classic' transform='translate(154.546875%2c 47)'%3e%3crect class='basic label-container' style='' x='-89.5859375' y='-39' width='179.171875' height='78'/%3e%3cg class='label' style='' transform='translate(-59.5859375%2c -24)'%3e%3crect/%3e%3cforeignObject width='119.171875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eThink%3cbr /%3eWhat do I know%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-AC-1' data-look='classic' transform='translate(94.03125%2c 175)'%3e%3crect class='basic label-container' style='' x='-78.46875' y='-39' width='156.9375' height='78'/%3e%3cg class='label' style='' transform='translate(-48.46875%2c -24)'%3e%3crect/%3e%3cforeignObject width='96.9375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAct%3cbr /%3eIssue tool call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-OB-3' data-look='classic' transform='translate(94.03125%2c 303)'%3e%3crect class='basic label-container' style='' x='-86.03125' y='-39' width='172.0625' height='78'/%3e%3cg class='label' style='' transform='translate(-56.03125%2c -24)'%3e%3crect/%3e%3cforeignObject width='112.0625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eObserve%3cbr /%3eRead tool result%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-RF-5' data-look='classic' transform='translate(154.546875%2c 431)'%3e%3crect class='basic label-container' style='' x='-81.1328125' y='-39' width='162.265625' height='78'/%3e%3cg class='label' style='' transform='translate(-51.1328125%2c -24)'%3e%3crect/%3e%3cforeignObject width='102.265625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReflect%3cbr /%3eDid that work%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-DN-9' data-look='classic' transform='translate(154.546875%2c 559)'%3e%3crect class='basic label-container' style='' x='-66.90625' y='-39' width='133.8125' height='78'/%3e%3cg class='label' style='' transform='translate(-36.90625%2c -24)'%3e%3crect/%3e%3cforeignObject width='73.8125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDone%3cbr /%3eFinal reply%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-1-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- Thoughts — short natural-language reasoning steps: “the user wants a flight; first I should search.”
- Actions — tool calls that turn thoughts into effects.
And then observes the result, and repeats. Four steps per iteration:
- Think. The model writes a short reasoning trace: “What do I know? What do I need? What’s the best next step?”
- Act. It picks a tool and issues the call.
- Observe. The tool result is appended to the context. The model reads it.
- Reflect. The model evaluates: did that work? Am I closer to the goal? What’s next?
Steps 1 and 4 often blur together in modern models — a single generation pass can include both reasoning-about-what’s-next and reasoning-about-what-just-happened. But conceptually, four steps is the right mental model.
Why the loop beats one giant call
It’s tempting to ask: why bother with a loop? Why not just write a bigger prompt that tells the model to do everything in one go — “first search flights, then check my calendar, then book it” — and let it produce the answer?
%3b%7d%23mermaid-2 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-2-gradient)%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-2-Reactive' data-look='classic'%3e%3crect style='' x='8' y='8' width='1038.96875' height='165'/%3e%3cg class='cluster-label' transform='translate(479.0078125%2c 8)'%3e%3cforeignObject width='96.953125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReactive loop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M212.234%2c101L218.484%2c101C224.734%2c101%2c237.234%2c101%2c249.068%2c101C260.901%2c101%2c272.068%2c101%2c277.651%2c101L283.234%2c101' id='mermaid-2-L_R1_R2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R1_R2_0' data-points='W3sieCI6MjEyLjIzNDM3NSwieSI6MTAxfSx7IngiOjI0OS43MzQzNzUsInkiOjEwMX0seyJ4IjoyODcuMjM0Mzc1LCJ5IjoxMDF9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M477.969%2c78.749L484.219%2c77.291C490.469%2c75.833%2c502.969%2c72.916%2c514.802%2c71.458C526.635%2c70%2c537.802%2c70%2c543.385%2c70L548.969%2c70' id='mermaid-2-L_R2_R3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R2_R3_0' data-points='W3sieCI6NDc3Ljk2ODc1LCJ5Ijo3OC43NDkzMzg1MDc2NzMzMX0seyJ4Ijo1MTUuNDY4NzUsInkiOjcwfSx7IngiOjU1Mi45Njg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M719.688%2c70L725.938%2c70C732.188%2c70%2c744.688%2c70%2c756.536%2c71.198C768.384%2c72.395%2c779.58%2c74.791%2c785.178%2c75.989L790.776%2c77.186' id='mermaid-2-L_R3_R4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R3_R4_0' data-points='W3sieCI6NzE5LjY4NzUsInkiOjcwfSx7IngiOjc1Ny4xODc1LCJ5Ijo3MH0seyJ4Ijo3OTQuNjg3NSwieSI6NzguMDIzMjkzNDMyNTQ2MX1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M794.688%2c123.977L788.438%2c125.314C782.188%2c126.651%2c769.688%2c129.326%2c743.294%2c130.663C716.901%2c132%2c676.615%2c132%2c636.328%2c132C596.042%2c132%2c555.755%2c132%2c530.011%2c130.693C504.267%2c129.387%2c493.066%2c126.773%2c487.465%2c125.466L481.864%2c124.16' id='mermaid-2-L_R4_R2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R4_R2_0' data-points='W3sieCI6Nzk0LjY4NzUsInkiOjEyMy45NzY3MDY1Njc0NTM5fSx7IngiOjc1Ny4xODc1LCJ5IjoxMzJ9LHsieCI6NjM2LjMyODEyNSwieSI6MTMyfSx7IngiOjUxNS40Njg3NSwieSI6MTMyfSx7IngiOjQ3Ny45Njg3NSwieSI6MTIzLjI1MDY2MTQ5MjMyNjY5fV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R1_R2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R2_R3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R3_R4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R4_R2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-R1-6' data-look='classic' transform='translate(128.8671875%2c 101)'%3e%3crect class='basic label-container' style='' x='-83.3671875' y='-27' width='166.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-53.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='106.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGoal in context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-R2-7' data-look='classic' transform='translate(382.6015625%2c 101)'%3e%3crect class='basic label-container' style='' x='-95.3671875' y='-27' width='190.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-65.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='130.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOne step at a time%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-R3-9' data-look='classic' transform='translate(636.328125%2c 70)'%3e%3crect class='basic label-container' style='' x='-83.359375' y='-27' width='166.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-53.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='106.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReal tool result%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-R4-11' data-look='classic' transform='translate(902.078125%2c 101)'%3e%3crect class='basic label-container' style='' x='-107.390625' y='-27' width='214.78125' height='54'/%3e%3cg class='label' style='' transform='translate(-77.390625%2c -12)'%3e%3crect/%3e%3cforeignObject width='154.78125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAdapts on actual data%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1088.96875%2c 20.5)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-2-OneShot' data-look='classic'%3e%3crect style='' x='8' y='8' width='1151.875' height='124'/%3e%3cg class='cluster-label' transform='translate(533.6796875%2c 8)'%3e%3cforeignObject width='100.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOne-shot plan%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M237.125%2c70L243.375%2c70C249.625%2c70%2c262.125%2c70%2c273.958%2c70C285.792%2c70%2c296.958%2c70%2c302.542%2c70L308.125%2c70' id='mermaid-2-L_O1_O2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_O1_O2_0' data-points='W3sieCI6MjM3LjEyNSwieSI6NzB9LHsieCI6Mjc0LjYyNSwieSI6NzB9LHsieCI6MzEyLjEyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M522.438%2c70L528.688%2c70C534.938%2c70%2c547.438%2c70%2c559.271%2c70C571.104%2c70%2c582.271%2c70%2c587.854%2c70L593.438%2c70' id='mermaid-2-L_O2_O3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_O2_O3_0' data-points='W3sieCI6NTIyLjQzNzUsInkiOjcwfSx7IngiOjU1OS45Mzc1LCJ5Ijo3MH0seyJ4Ijo1OTcuNDM3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M834.422%2c70L840.672%2c70C846.922%2c70%2c859.422%2c70%2c871.255%2c70C883.089%2c70%2c894.255%2c70%2c899.839%2c70L905.422%2c70' id='mermaid-2-L_O3_O4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_O3_O4_0' data-points='W3sieCI6ODM0LjQyMTg3NSwieSI6NzB9LHsieCI6ODcxLjkyMTg3NSwieSI6NzB9LHsieCI6OTA5LjQyMTg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_O1_O2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_O2_O3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_O3_O4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-O1-0' data-look='classic' transform='translate(141.3125%2c 70)'%3e%3crect class='basic label-container' style='' x='-95.8125' y='-27' width='191.625' height='54'/%3e%3cg class='label' style='' transform='translate(-65.8125%2c -12)'%3e%3crect/%3e%3cforeignObject width='131.625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBig upfront prompt%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-O2-1' data-look='classic' transform='translate(417.28125%2c 70)'%3e%3crect class='basic label-container' style='' x='-105.15625' y='-27' width='210.3125' height='54'/%3e%3cg class='label' style='' transform='translate(-75.15625%2c -12)'%3e%3crect/%3e%3cforeignObject width='150.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGuesses tool outputs%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-O3-3' data-look='classic' transform='translate(715.9296875%2c 70)'%3e%3crect class='basic label-container' style='' x='-118.4921875' y='-27' width='236.984375' height='54'/%3e%3cg class='label' style='' transform='translate(-88.4921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='176.984375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFixed plan with branches%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-O4-5' data-look='classic' transform='translate(1015.8984375%2c 70)'%3e%3crect class='basic label-container' style='' x='-106.4765625' y='-27' width='212.953125' height='54'/%3e%3cg class='label' style='' transform='translate(-76.4765625%2c -12)'%3e%3crect/%3e%3cforeignObject width='152.953125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBrittle if step diverges%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-2-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Two reasons, and both are practical.
First, you can’t predict what the tools will return. The flight search might return zero results, or exorbitant prices, or a schedule conflict the model didn’t know about. In a one-shot prompt, the model has to guess what the world will say and write a plan that handles every branch in advance. In a loop, it handles each branch as it comes, with the actual data in front of it. The loop is just the world’s cheapest form of reactive programming.
Second, errors compound. In a one-shot plan, a small mistake early — wrong date format, misread parameter, a tool that returned an unexpected shape — cascades through everything downstream. In a loop, the model sees the error, reads the context, and adjusts. It’s the same reason humans solve problems step-by-step rather than writing out the whole plan before starting.
The loop is not always better. For very short, linear tasks (one tool call, a single reply), loop overhead is wasted effort. But for anything resembling real work, the loop is dramatically more robust.
Termination: the problem nobody warns you about
The first agent loop you build will, almost without exception, either terminate too early (stopping before the job is done) or too late (spinning in circles at your expense).
%3b%7d%23mermaid-3 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-3 .cluster text%7bfill:%23333%3b%7d%23mermaid-3 .cluster span%7bcolor:%23333%3b%7d%23mermaid-3 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-3 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-3 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-3 .icon-shape%2c%23mermaid-3 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-3 .icon-shape p%2c%23mermaid-3 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-3 .icon-shape .label rect%2c%23mermaid-3 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-3 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-3 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-3-gradient)%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M403.973%2c45.736L354.835%2c52.614C305.698%2c59.491%2c207.423%2c73.245%2c158.286%2c90.295C109.148%2c107.344%2c109.148%2c127.688%2c109.148%2c137.859L109.148%2c148.031' id='mermaid-3-L_L_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L_G_0' data-points='W3sieCI6NDAzLjk3MjY1NjI1LCJ5Ijo0NS43MzY0NTAzMjc1MDUxOH0seyJ4IjoxMDkuMTQ4NDM3NSwieSI6ODd9LHsieCI6MTA5LjE0ODQzNzUsInkiOjE1Mi4wMzEyNX1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M109.148%2c279.844L109.148%2c292.682C109.148%2c305.521%2c109.148%2c331.198%2c109.148%2c349.536C109.148%2c367.875%2c109.148%2c378.875%2c109.148%2c384.375L109.148%2c389.875' id='mermaid-3-L_G_T1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_G_T1_0' data-points='W3sieCI6MTA5LjE0ODQzNzUsInkiOjI3OS44NDM3NX0seyJ4IjoxMDkuMTQ4NDM3NSwieSI6MzU2Ljg3NX0seyJ4IjoxMDkuMTQ4NDM3NSwieSI6MzkzLjg3NX1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M418.536%2c62L408.945%2c66.167C399.355%2c70.333%2c380.174%2c78.667%2c370.583%2c89.444C360.992%2c100.221%2c360.992%2c113.443%2c360.992%2c120.053L360.992%2c126.664' id='mermaid-3-L_L_S_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L_S_0' data-points='W3sieCI6NDE4LjUzNjEzMjgxMjUsInkiOjYyfSx7IngiOjM2MC45OTIxODc1LCJ5Ijo4N30seyJ4IjozNjAuOTkyMTg3NSwieSI6MTMwLjY2NDA2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M360.992%2c301.211L360.992%2c310.488C360.992%2c319.766%2c360.992%2c338.32%2c360.992%2c353.098C360.992%2c367.875%2c360.992%2c378.875%2c360.992%2c384.375L360.992%2c389.875' id='mermaid-3-L_S_T2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_T2_0' data-points='W3sieCI6MzYwLjk5MjE4NzUsInkiOjMwMS4yMTA5Mzc1fSx7IngiOjM2MC45OTIxODc1LCJ5IjozNTYuODc1fSx7IngiOjM2MC45OTIxODc1LCJ5IjozOTMuODc1fV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M542.831%2c62L552.422%2c66.167C562.012%2c70.333%2c581.194%2c78.667%2c590.784%2c86.333C600.375%2c94%2c600.375%2c101%2c600.375%2c104.5L600.375%2c108' id='mermaid-3-L_L_P_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L_P_0' data-points='W3sieCI6NTQyLjgzMTA1NDY4NzUsInkiOjYyfSx7IngiOjYwMC4zNzUsInkiOjg3fSx7IngiOjYwMC4zNzUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M600.375%2c319.875L600.375%2c326.042C600.375%2c332.208%2c600.375%2c344.542%2c600.375%2c356.208C600.375%2c367.875%2c600.375%2c378.875%2c600.375%2c384.375L600.375%2c389.875' id='mermaid-3-L_P_T3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P_T3_0' data-points='W3sieCI6NjAwLjM3NSwieSI6MzE5Ljg3NX0seyJ4Ijo2MDAuMzc1LCJ5IjozNTYuODc1fSx7IngiOjYwMC4zNzUsInkiOjM5My44NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M557.395%2c45.906L605.568%2c52.755C653.742%2c59.604%2c750.09%2c73.302%2c798.264%2c88.299C846.438%2c103.297%2c846.438%2c119.594%2c846.438%2c127.742L846.438%2c135.891' id='mermaid-3-L_L_W_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L_W_0' data-points='W3sieCI6NTU3LjM5NDUzMTI1LCJ5Ijo0NS45MDYxNTQ4ODEyOTE4NTV9LHsieCI6ODQ2LjQzNzUsInkiOjg3fSx7IngiOjg0Ni40Mzc1LCJ5IjoxMzkuODkwNjI1fV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M846.438%2c291.984L846.438%2c302.799C846.438%2c313.615%2c846.438%2c335.245%2c846.438%2c351.56C846.438%2c367.875%2c846.438%2c378.875%2c846.438%2c384.375L846.438%2c389.875' id='mermaid-3-L_W_T4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_W_T4_0' data-points='W3sieCI6ODQ2LjQzNzUsInkiOjI5MS45ODQzNzV9LHsieCI6ODQ2LjQzNzUsInkiOjM1Ni44NzV9LHsieCI6ODQ2LjQzNzUsInkiOjM5My44NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(109.1484375%2c 356.875)'%3e%3cg class='label' data-id='L_G_T1_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L_S_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(360.9921875%2c 356.875)'%3e%3cg class='label' data-id='L_S_T2_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L_P_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(600.375%2c 356.875)'%3e%3cg class='label' data-id='L_P_T3_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L_W_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(846.4375%2c 356.875)'%3e%3cg class='label' data-id='L_W_T4_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-3-flowchart-L-0' data-look='classic' transform='translate(480.68359375%2c 35)'%3e%3crect class='basic label-container' style='' x='-76.7109375' y='-27' width='153.421875' height='54'/%3e%3cg class='label' style='' transform='translate(-46.7109375%2c -12)'%3e%3crect/%3e%3cforeignObject width='93.421875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLoop running%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-G-1' data-look='classic' transform='translate(109.1484375%2c 215.9375)'%3e%3cpolygon points='63.90625%2c0 127.8125%2c-63.90625 63.90625%2c-127.8125 0%2c-63.90625' class='label-container' transform='translate(-63.40625%2c 63.90625)'/%3e%3cg class='label' style='' transform='translate(-36.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='73.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGoal met%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-T1-3' data-look='classic' transform='translate(109.1484375%2c 432.875)'%3e%3crect class='basic label-container' style='' x='-101.1484375' y='-39' width='202.296875' height='78'/%3e%3cg class='label' style='' transform='translate(-71.1484375%2c -24)'%3e%3crect/%3e%3cforeignObject width='142.296875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGoal-based exit%3cbr /%3emodel replies in text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-S-5' data-look='classic' transform='translate(360.9921875%2c 215.9375)'%3e%3cpolygon points='85.2734375%2c0 170.546875%2c-85.2734375 85.2734375%2c-170.546875 0%2c-85.2734375' class='label-container' transform='translate(-84.7734375%2c 85.2734375)'/%3e%3cg class='label' style='' transform='translate(-58.2734375%2c -12)'%3e%3crect/%3e%3cforeignObject width='116.546875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStep budget hit%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-T2-7' data-look='classic' transform='translate(360.9921875%2c 432.875)'%3e%3crect class='basic label-container' style='' x='-100.6953125' y='-39' width='201.390625' height='78'/%3e%3cg class='label' style='' transform='translate(-70.6953125%2c -24)'%3e%3crect/%3e%3cforeignObject width='141.390625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStep budget exit%3cbr /%3ereturn partial results%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-P-9' data-look='classic' transform='translate(600.375%2c 215.9375)'%3e%3cpolygon points='103.9375%2c0 207.875%2c-103.9375 103.9375%2c-207.875 0%2c-103.9375' class='label-container' transform='translate(-103.4375%2c 103.9375)'/%3e%3cg class='label' style='' transform='translate(-76.9375%2c -12)'%3e%3crect/%3e%3cforeignObject width='153.875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRepeating same call%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-T3-11' data-look='classic' transform='translate(600.375%2c 432.875)'%3e%3crect class='basic label-container' style='' x='-88.6875' y='-39' width='177.375' height='78'/%3e%3cg class='label' style='' transform='translate(-58.6875%2c -24)'%3e%3crect/%3e%3cforeignObject width='117.375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo-progress exit%3cbr /%3ebreak the loop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-W-13' data-look='classic' transform='translate(846.4375%2c 215.9375)'%3e%3cpolygon points='76.046875%2c0 152.09375%2c-76.046875 76.046875%2c-152.09375 0%2c-76.046875' class='label-container' transform='translate(-75.546875%2c 76.046875)'/%3e%3cg class='label' style='' transform='translate(-49.046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='98.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTime limit hit%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-T4-15' data-look='classic' transform='translate(846.4375%2c 432.875)'%3e%3crect class='basic label-container' style='' x='-107.375' y='-39' width='214.75' height='78'/%3e%3cg class='label' style='' transform='translate(-77.375%2c -24)'%3e%3crect/%3e%3cforeignObject width='154.75' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTime budget exit%3cbr /%3esurface what we have%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-3-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Termination is surprisingly hard. A few strategies that work:
1. Goal-based termination. The model is told, in the system prompt, what “done” looks like: “You are finished when the user has a confirmed booking or an explicit failure explanation.” The loop ends when the model produces a plain-text reply instead of a tool call — a natural signal that it thinks it’s done.
2. Step budget. A hard cap — say, 20 iterations — on how many loop passes are allowed per user turn. If the cap is hit, the harness stops and returns whatever the model has gathered, with a note that the budget was exhausted. This is your insurance against infinite loops.
3. No-progress detection. If three consecutive iterations produce the same tool call with the same arguments, something’s wrong. Break the loop. This catches the most common failure mode: the model repeating itself when it’s genuinely stuck.
4. Time budget. For user-facing agents, a wall-clock timeout (say, 60 seconds) that ends the loop and surfaces partial progress to the user. Better to say “I couldn’t finish in time — here’s what I have so far” than to silently hang.
Production agents use all four, combined. The loop is the easy part. Stopping it gracefully is where most “autonomous agent” products quietly ship their worst code.
The cost of a loop
Every iteration of the loop is a full model call, with all the accumulated context sent again. For a 15-iteration loop, the user paid for 15 model calls and the context got longer each time. Costs add up faster than people expect.
%3b%7d%23mermaid-4 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-4 .cluster text%7bfill:%23333%3b%7d%23mermaid-4 .cluster span%7bcolor:%23333%3b%7d%23mermaid-4 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-4 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-4 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-4 .icon-shape%2c%23mermaid-4 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-4 .icon-shape p%2c%23mermaid-4 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-4 .icon-shape .label rect%2c%23mermaid-4 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-4 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-4 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-4 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node rect%2c%23mermaid-4 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-4 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-4-gradient)%3bstroke-width:1px%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M261.113%2c62L261.113%2c66.167C261.113%2c70.333%2c261.113%2c78.667%2c261.113%2c86.333C261.113%2c94%2c261.113%2c101%2c261.113%2c104.5L261.113%2c108' id='mermaid-4-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MjYxLjExMzI4MTI1LCJ5Ijo2Mn0seyJ4IjoyNjEuMTEzMjgxMjUsInkiOjg3fSx7IngiOjI2MS4xMTMyODEyNSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M261.113%2c166L261.113%2c170.167C261.113%2c174.333%2c261.113%2c182.667%2c261.113%2c190.333C261.113%2c198%2c261.113%2c205%2c261.113%2c208.5L261.113%2c212' id='mermaid-4-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MjYxLjExMzI4MTI1LCJ5IjoxNjZ9LHsieCI6MjYxLjExMzI4MTI1LCJ5IjoxOTF9LHsieCI6MjYxLjExMzI4MTI1LCJ5IjoyMTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M261.113%2c270L261.113%2c274.167C261.113%2c278.333%2c261.113%2c286.667%2c261.113%2c294.333C261.113%2c302%2c261.113%2c309%2c261.113%2c312.5L261.113%2c316' id='mermaid-4-L_C_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_D_0' data-points='W3sieCI6MjYxLjExMzI4MTI1LCJ5IjoyNzB9LHsieCI6MjYxLjExMzI4MTI1LCJ5IjoyOTV9LHsieCI6MjYxLjExMzI4MTI1LCJ5IjozMjB9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M261.113%2c374L261.113%2c378.167C261.113%2c382.333%2c261.113%2c390.667%2c261.113%2c398.333C261.113%2c406%2c261.113%2c413%2c261.113%2c416.5L261.113%2c420' id='mermaid-4-L_D_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_E_0' data-points='W3sieCI6MjYxLjExMzI4MTI1LCJ5IjozNzR9LHsieCI6MjYxLjExMzI4MTI1LCJ5IjozOTl9LHsieCI6MjYxLjExMzI4MTI1LCJ5Ijo0MjR9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M223.408%2c508.779L206.665%2c519.23C189.923%2c529.681%2c156.438%2c550.583%2c139.696%2c564.533C122.953%2c578.484%2c122.953%2c585.484%2c122.953%2c588.984L122.953%2c592.484' id='mermaid-4-L_E_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_F_0' data-points='W3sieCI6MjIzLjQwNzY1ODE1OTM2ODYyLCJ5Ijo1MDguNzc4NzUxOTA5MzY4Nn0seyJ4IjoxMjIuOTUzMTI1LCJ5Ijo1NzEuNDg0Mzc1fSx7IngiOjEyMi45NTMxMjUsInkiOjU5Ni40ODQzNzV9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M298.819%2c508.779L315.561%2c519.23C332.304%2c529.681%2c365.789%2c550.583%2c382.531%2c564.533C399.273%2c578.484%2c399.273%2c585.484%2c399.273%2c588.984L399.273%2c592.484' id='mermaid-4-L_E_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_G_0' data-points='W3sieCI6Mjk4LjgxODkwNDM0MDYzMTQsInkiOjUwOC43Nzg3NTE5MDkzNjg2fSx7IngiOjM5OS4yNzM0Mzc1LCJ5Ijo1NzEuNDg0Mzc1fSx7IngiOjM5OS4yNzM0Mzc1LCJ5Ijo1OTYuNDg0Mzc1fV0=' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-4-flowchart-A-0' data-look='classic' transform='translate(261.11328125%2c 35)'%3e%3crect class='basic label-container' style='' x='-78.921875' y='-27' width='157.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-48.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='97.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEach iteration%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-B-1' data-look='classic' transform='translate(261.11328125%2c 139)'%3e%3crect class='basic label-container' style='' x='-81.1328125' y='-27' width='162.265625' height='54'/%3e%3cg class='label' style='' transform='translate(-51.1328125%2c -12)'%3e%3crect/%3e%3cforeignObject width='102.265625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFull model call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-C-3' data-look='classic' transform='translate(261.11328125%2c 243)'%3e%3crect class='basic label-container' style='' x='-123.3828125' y='-27' width='246.765625' height='54'/%3e%3cg class='label' style='' transform='translate(-93.3828125%2c -12)'%3e%3crect/%3e%3cforeignObject width='186.765625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContext grows by one turn%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-D-5' data-look='classic' transform='translate(261.11328125%2c 347)'%3e%3crect class='basic label-container' style='' x='-105.796875' y='-27' width='211.59375' height='54'/%3e%3cg class='label' style='' transform='translate(-75.796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='151.59375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCost = iters x ctx size%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-E-7' data-look='classic' transform='translate(261.11328125%2c 485.2421875)'%3e%3cpolygon points='61.2421875%2c0 122.484375%2c-61.2421875 61.2421875%2c-122.484375 0%2c-61.2421875' class='label-container' transform='translate(-60.7421875%2c 61.2421875)'/%3e%3cg class='label' style='' transform='translate(-34.2421875%2c -12)'%3e%3crect/%3e%3cforeignObject width='68.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMitigation%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-F-9' data-look='classic' transform='translate(122.953125%2c 635.484375)'%3e%3crect class='basic label-container' style='' x='-114.953125' y='-39' width='229.90625' height='78'/%3e%3cg class='label' style='' transform='translate(-84.953125%2c -24)'%3e%3crect/%3e%3cforeignObject width='169.90625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSmall model inner%3cbr /%3ebig model when needed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-G-11' data-look='classic' transform='translate(399.2734375%2c 635.484375)'%3e%3crect class='basic label-container' style='' x='-111.3671875' y='-39' width='222.734375' height='78'/%3e%3cg class='label' style='' transform='translate(-81.3671875%2c -24)'%3e%3crect/%3e%3cforeignObject width='162.734375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSummarize old context%3cbr /%3eswap details for gist%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-4-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Back-of-the-envelope math: a single call on a frontier model costs maybe $0.02 for a simple turn. A 15-iteration loop on the same model might cost $0.50 — or several dollars, if the context has grown large. Multiply that by a few thousand user turns a day and the economics change.
Two practical mitigations:
- Use smaller models for the inner loop. A cheap, fast model for routine steps; a strong model only when genuinely needed. Many production systems have a “router” pattern where the main loop runs on a small model and delegates tricky reasoning to a larger one.
- Summarize instead of re-sending. When the loop gets long, replace old tool calls and results with a compact summary. The model can still see the gist of what happened without paying for every detail again.
This is the same context-management game we’ll see again at the memory rung. Agents and memory share a budget: the context window.
Planner-executor: one more pattern
ReAct is the simplest agent loop. A common elaboration is planner-executor: split the agent into two models (or two calls of the same model), one that plans and one that executes.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-5 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-5 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-5 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-5 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-5 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-5 .sequenceNumber%7bfill:white%3b%7d%23mermaid-5 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-5 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-5 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-5 .labelText%2c%23mermaid-5 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .loopText%2c%23mermaid-5 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-5 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-5 .noteText%2c%23mermaid-5 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-5 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-5 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-5 .actor-man circle%2c%23mermaid-5 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-5 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-5 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node rect%2c%23mermaid-5 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-5 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-5-gradient)%3bstroke-width:1px%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-5-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-5-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-5-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='181' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ehigh-level goal%3c/text%3e%3cline x1='76' y1='109' x2='285' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='U' data-to='P' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='184' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eproposed plan steps%3c/text%3e%3cline x1='288' y1='153' x2='79' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='P' data-to='U' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='281' y='168' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eapprove plan%3c/text%3e%3cline x1='76' y1='197' x2='485' y2='197' class='messageLine0' data-et='message' data-id='i2' data-from='U' data-to='E' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='588' y='212' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eexecute step 1%3c/text%3e%3cline x1='490' y1='241' x2='685' y2='241' class='messageLine0' data-et='message' data-id='i3' data-from='E' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='591' y='256' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eresult%3c/text%3e%3cline x1='688' y1='285' x2='493' y2='285' class='messageLine0' data-et='message' data-id='i4' data-from='T' data-to='E' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='588' y='300' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eexecute step 2%3c/text%3e%3cline x1='490' y1='329' x2='685' y2='329' class='messageLine0' data-et='message' data-id='i5' data-from='E' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='591' y='344' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eresult%3c/text%3e%3cline x1='688' y1='373' x2='493' y2='373' class='messageLine0' data-et='message' data-id='i6' data-from='T' data-to='E' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='490' y='388' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eadjust if result diverges from plan%3c/text%3e%3cpath d='M 490%2c417 C 550%2c407 550%2c447 490%2c437' class='messageLine0' data-et='message' data-id='i7' data-from='E' data-to='E' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='284' y='462' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3efinal answer%3c/text%3e%3cline x1='488' y1='491' x2='79' y2='491' class='messageLine0' data-et='message' data-id='i8' data-from='E' data-to='U' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
- The planner reads the user goal and produces a plan — a list of steps in natural language, without running anything yet.
- The executor then runs through the plan step by step, calling tools for each, adjusting as results come in.
The advantage: the plan is legible. You can show it to the user (“here’s what I’m going to do — okay?”), cache it, reuse it, or hand it to a different agent to execute. You also get clearer debugging when something goes wrong: you can inspect the plan and see where it diverged.
The cost is latency — you now have two model calls for the initial plan instead of one. For short tasks, overkill. For long or consequential ones, often worth it.
What makes a loop feel “intelligent”
After you’ve built a few agent loops, you’ll notice that the ones that feel most intelligent to users share a few properties:
%3b%7d%23mermaid-6 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-6 .cluster text%7bfill:%23333%3b%7d%23mermaid-6 .cluster span%7bcolor:%23333%3b%7d%23mermaid-6 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-6 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-6 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-6 .icon-shape%2c%23mermaid-6 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-6 .icon-shape p%2c%23mermaid-6 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-6 .icon-shape .label rect%2c%23mermaid-6 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-6 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-6 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-6 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node rect%2c%23mermaid-6 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-6 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-6-gradient)%3bstroke-width:1px%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M428.457%2c46.151L376.202%2c52.959C323.948%2c59.767%2c219.439%2c73.384%2c167.184%2c85.692C114.93%2c98%2c114.93%2c109%2c114.93%2c114.5L114.93%2c120' id='mermaid-6-L_I_N_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_N_0' data-points='W3sieCI6NDI4LjQ1NzAzMTI1LCJ5Ijo0Ni4xNTA4OTExMzU2MjI5MX0seyJ4IjoxMTQuOTI5Njg3NSwieSI6ODd9LHsieCI6MTE0LjkyOTY4NzUsInkiOjEyNH1d' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M445.888%2c62L435.37%2c66.167C424.852%2c70.333%2c403.817%2c78.667%2c393.299%2c88.333C382.781%2c98%2c382.781%2c109%2c382.781%2c114.5L382.781%2c120' id='mermaid-6-L_I_P_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_P_0' data-points='W3sieCI6NDQ1Ljg4Nzg0NTU1Mjg4NDY0LCJ5Ijo2Mn0seyJ4IjozODIuNzgxMjUsInkiOjg3fSx7IngiOjM4Mi43ODEyNSwieSI6MTI0fV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M582.198%2c62L592.716%2c66.167C603.234%2c70.333%2c624.269%2c78.667%2c634.787%2c88.333C645.305%2c98%2c645.305%2c109%2c645.305%2c114.5L645.305%2c120' id='mermaid-6-L_I_S_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_S_0' data-points='W3sieCI6NTgyLjE5ODA5MTk0NzExNTQsInkiOjYyfSx7IngiOjY0NS4zMDQ2ODc1LCJ5Ijo4N30seyJ4Ijo2NDUuMzA0Njg3NSwieSI6MTI0fV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M599.629%2c46.015L652.701%2c52.846C705.773%2c59.677%2c811.918%2c73.338%2c864.99%2c83.669C918.063%2c94%2c918.063%2c101%2c918.063%2c104.5L918.063%2c108' id='mermaid-6-L_I_M_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_M_0' data-points='W3sieCI6NTk5LjYyODkwNjI1LCJ5Ijo0Ni4wMTU0NzkyMTc2Mjc1NX0seyJ4Ijo5MTguMDYyNSwieSI6ODd9LHsieCI6OTE4LjA2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_N_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_P_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_S_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_M_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-I-0' data-look='classic' transform='translate(514.04296875%2c 35)'%3e%3crect class='basic label-container' style='' x='-85.5859375' y='-27' width='171.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-55.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='111.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFeels intelligent%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-N-1' data-look='classic' transform='translate(114.9296875%2c 163)'%3e%3crect class='basic label-container' style='' x='-106.9296875' y='-39' width='213.859375' height='78'/%3e%3cg class='label' style='' transform='translate(-76.9296875%2c -24)'%3e%3crect/%3e%3cforeignObject width='153.859375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNarrates clearly%3cbr /%3etells user what it does%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-P-3' data-look='classic' transform='translate(382.78125%2c 163)'%3e%3crect class='basic label-container' style='' x='-110.921875' y='-39' width='221.84375' height='78'/%3e%3cg class='label' style='' transform='translate(-80.921875%2c -24)'%3e%3crect/%3e%3cforeignObject width='161.84375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAsks permission%3cbr /%3ebefore irreversible acts%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-S-5' data-look='classic' transform='translate(645.3046875%2c 163)'%3e%3crect class='basic label-container' style='' x='-101.6015625' y='-39' width='203.203125' height='78'/%3e%3cg class='label' style='' transform='translate(-71.6015625%2c -24)'%3e%3crect/%3e%3cforeignObject width='143.203125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eKnows when to stop%3cbr /%3eclean finish or stuck%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-M-7' data-look='classic' transform='translate(918.0625%2c 163)'%3e%3crect class='basic label-container' style='' x='-121.15625' y='-51' width='242.3125' height='102'/%3e%3cg class='label' style='' transform='translate(-91.15625%2c -36)'%3e%3crect/%3e%3cforeignObject width='182.3125' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMatches response to task%3cbr /%3eone step small tasks%3cbr /%3efull plan big tasks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-6-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- They narrate. A good loop tells the user what it’s doing, at the right granularity. Not “I just called tool_17” — “Checking your calendar for Wednesday.”
- They ask before acting on anything irreversible. Permission prompts for destructive actions are not a nuisance; they’re a trust-building feature.
- They know how to stop. They finish cleanly when done. They say they’re stuck when they’re stuck.
- They don’t over-plan small things. A one-step request gets a one-step answer. A ten-step request gets a plan. Matching the response shape to the task is itself a design choice.
Building agents is mostly engineering these behaviors. The model is the engine; the loop, the budget, the narration, the termination — these are the car around it.
What loops still cannot do
The loop only runs during a single user turn. Once the turn ends, everything in the context is gone — unless something else preserves it. The model has no notion that you came back. It does not know that last Tuesday it helped you debug the same issue.
That’s the next rung. Memory. Not the fake memory the chat baseline provides by re-sending the transcript — real, persistent, retrievable memory that survives across sessions and builds over time.
Read next: Memory — How Agents Build Continuity.