An agent that forgets everything at the end of each session is not an assistant. It is a very clever stranger that you meet, brief, and never see again. The chat baseline pretends to remember within a single conversation by re-sending the transcript — we covered that in post 2 — but the moment you close the tab, the costume comes off. Nothing persists.
A real agent, in the sense we mean on this rung, persists. It remembers your name, your preferences, what you were working on last week, which of its past attempts succeeded, which failed, and what it learned in the process. It uses that memory the next time you show up.
This post is about how that actually works. Not the marketing version (“our AI has memory!”) — the architectural version. What gets stored where, what gets retrieved when, and — the part nobody mentions but matters most — what gets deliberately forgotten so the whole system doesn’t collapse under its own weight.
Memory is architecture, not magic
The model itself has no memory. This is worth repeating until it’s muscle memory: every rung above this one is the harness pretending to have a memory, by storing information externally and handing relevant pieces back to the model through the context window each turn.
So when we talk about “an agent’s memory,” we are really talking about four things in combination:
- A store where memory is kept across time.
- A writer that decides what to put in the store.
- A retriever that decides what to pull out at the right moment.
- A budget — because everything retrieved costs context window space.
Get any one of these wrong and the whole scheme falls apart. A store with no retriever is a drawer of notes nobody reads. A retriever with no writer has nothing to find. A writer and retriever with no budget discipline blow up the context window and push out the user’s actual message.
Real agent memory is an engineered composition of all four.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M88.524%2c62L81.968%2c66.167C75.412%2c70.333%2c62.3%2c78.667%2c56.419%2c86.345C50.538%2c94.024%2c51.889%2c101.048%2c52.564%2c104.56L53.24%2c108.072' id='mermaid-0-L_S_W_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_W_0' data-points='W3sieCI6ODguNTI0MTg4NzAxOTIzMDgsInkiOjYyfSx7IngiOjQ5LjE4NzUsInkiOjg3fSx7IngiOjUzLjk5NTE5MjMwNzY5MjMxLCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M96.479%2c112L102.234%2c107.833C107.988%2c103.667%2c119.498%2c95.333%2c125.253%2c87.667C131.008%2c80%2c131.008%2c73%2c131.008%2c69.5L131.008%2c66' id='mermaid-0-L_W_S_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_W_S_0' data-points='W3sieCI6OTYuNDc4ODE2MTA1NzY5MjMsInkiOjExMn0seyJ4IjoxMzEuMDA3ODEyNSwieSI6ODd9LHsieCI6MTMxLjAwNzgxMjUsInkiOjYyfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M178.684%2c62L186.041%2c66.167C193.399%2c70.333%2c208.113%2c78.667%2c215.471%2c86.333C222.828%2c94%2c222.828%2c101%2c222.828%2c104.5L222.828%2c108' id='mermaid-0-L_S_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_R_0' data-points='W3sieCI6MTc4LjY4Mzc0Mzk5MDM4NDYsInkiOjYyfSx7IngiOjIyMi44MjgxMjUsInkiOjg3fSx7IngiOjIyMi44MjgxMjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M199.369%2c166L195.749%2c170.167C192.129%2c174.333%2c184.889%2c182.667%2c181.269%2c190.333C177.648%2c198%2c177.648%2c205%2c177.648%2c208.5L177.648%2c212' id='mermaid-0-L_R_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R_B_0' data-points='W3sieCI6MTk5LjM2OTQ0MTEwNTc2OTIzLCJ5IjoxNjZ9LHsieCI6MTc3LjY0ODQzNzUsInkiOjE5MX0seyJ4IjoxNzcuNjQ4NDM3NSwieSI6MjE2fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M177.648%2c270L177.648%2c274.167C177.648%2c278.333%2c177.648%2c286.667%2c180.831%2c294.497C184.014%2c302.327%2c190.38%2c309.654%2c193.563%2c313.317L196.746%2c316.98' id='mermaid-0-L_B_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_CTX_0' data-points='W3sieCI6MTc3LjY0ODQzNzUsInkiOjI3MH0seyJ4IjoxNzcuNjQ4NDM3NSwieSI6Mjk1fSx7IngiOjE5OS4zNjk0NDExMDU3NjkyMywieSI6MzIwfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M246.287%2c166L249.907%2c170.167C253.527%2c174.333%2c260.767%2c182.667%2c264.388%2c195.5C268.008%2c208.333%2c268.008%2c225.667%2c268.008%2c243C268.008%2c260.333%2c268.008%2c277.667%2c264.825%2c289.997C261.642%2c302.327%2c255.276%2c309.654%2c252.093%2c313.317L248.91%2c316.98' id='mermaid-0-L_R_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R_CTX_0' data-points='W3sieCI6MjQ2LjI4NjgwODg5NDIzMDc3LCJ5IjoxNjZ9LHsieCI6MjY4LjAwNzgxMjUsInkiOjE5MX0seyJ4IjoyNjguMDA3ODEyNSwieSI6MjQzfSx7IngiOjI2OC4wMDc4MTI1LCJ5IjoyOTV9LHsieCI6MjQ2LjI4NjgwODg5NDIzMDc3LCJ5IjozMjB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_W_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_W_S_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_R_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-S-0' data-look='classic' transform='translate(131.0078125%2c 35)'%3e%3crect class='basic label-container' style='' x='-49.125' y='-27' width='98.25' height='54'/%3e%3cg class='label' style='' transform='translate(-19.125%2c -12)'%3e%3crect/%3e%3cforeignObject width='38.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStore%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-W-1' data-look='classic' transform='translate(59.1875%2c 139)'%3e%3crect class='basic label-container' style='' x='-51.1875' y='-27' width='102.375' height='54'/%3e%3cg class='label' style='' transform='translate(-21.1875%2c -12)'%3e%3crect/%3e%3cforeignObject width='42.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWriter%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-R-5' data-look='classic' transform='translate(222.828125%2c 139)'%3e%3crect class='basic label-container' style='' x='-62.453125' y='-27' width='124.90625' height='54'/%3e%3cg class='label' style='' transform='translate(-32.453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='64.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRetriever%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B-7' data-look='classic' transform='translate(177.6484375%2c 243)'%3e%3crect class='basic label-container' style='' x='-55.359375' y='-27' width='110.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-25.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='50.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBudget%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-CTX-9' data-look='classic' transform='translate(222.828125%2c 347)'%3e%3crect class='basic label-container' style='' x='-88.25' y='-27' width='176.5' height='54'/%3e%3cg class='label' style='' transform='translate(-58.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='116.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContext Window%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
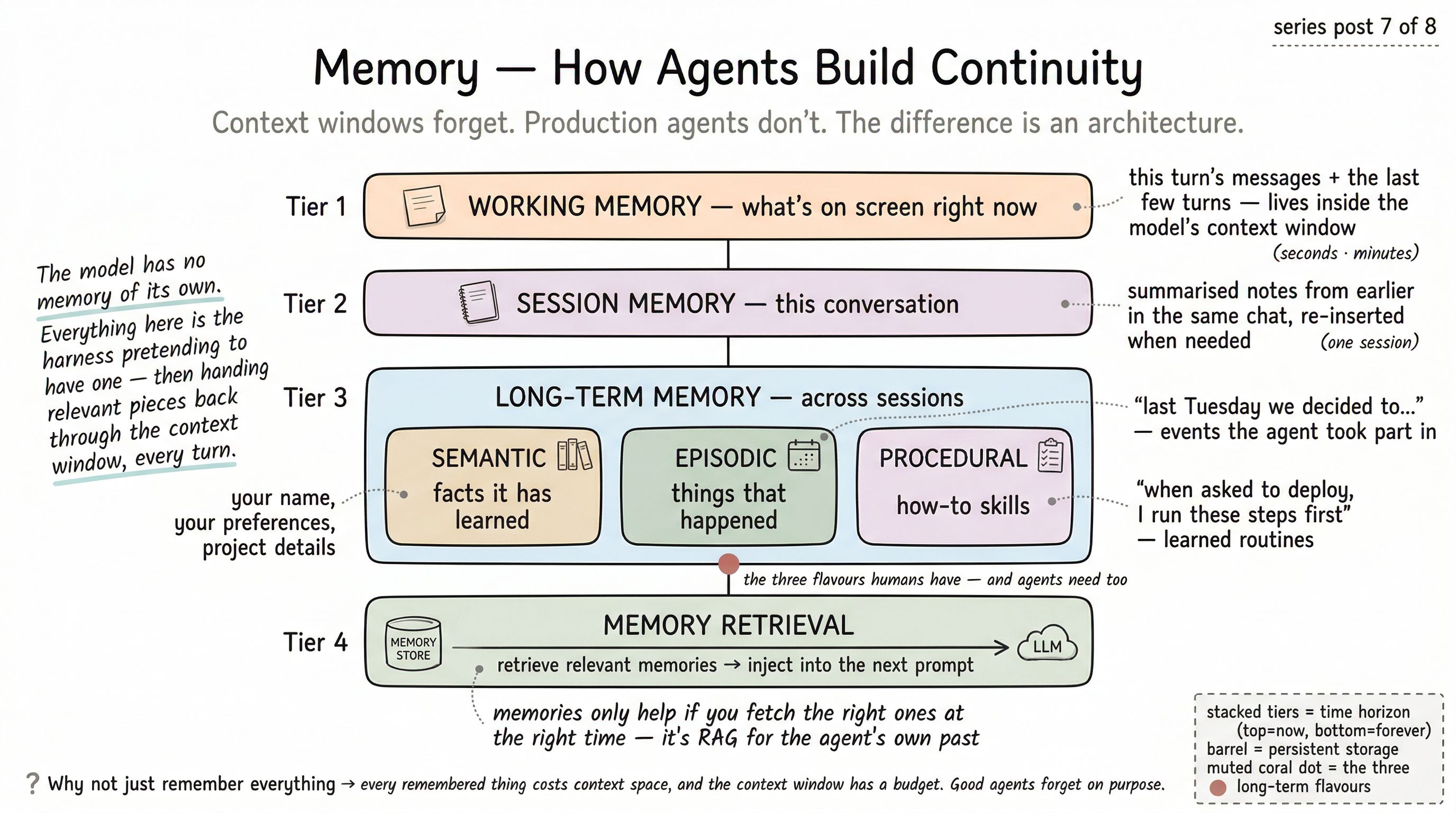
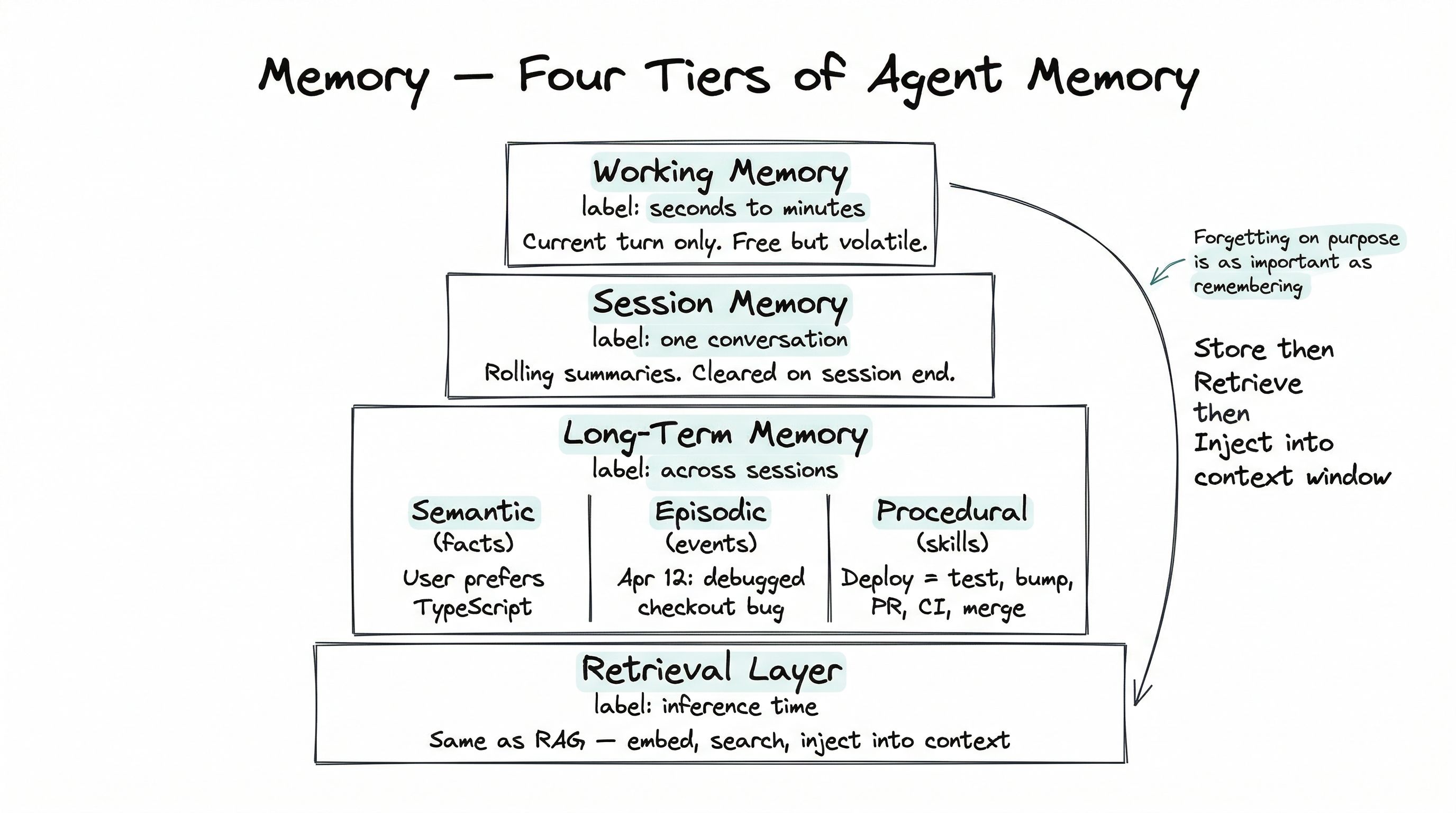
The four tiers of memory
Think of memory in an agent as four stacked time horizons, each with a different purpose and cost.
Tier 1 — Working memory (seconds to minutes)
This is just the current context window. The model’s “short-term” memory is whatever happens to be inside the text it’s reading right now. The most recent user message, the last few tool calls, the result of the last retrieval — all of it lives here, and all of it disappears the moment the request ends.
Working memory is free (it’s what the model already has) but limited and volatile. Nothing survives without being explicitly saved somewhere else.
%3b%7d%23mermaid-1 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M184.93%2c35L191.392%2c35C197.854%2c35%2c210.779%2c35%2c232.457%2c55.961C254.136%2c76.921%2c284.569%2c118.842%2c299.786%2c139.803L315.002%2c160.763' id='mermaid-1-L_MSG_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_MSG_CTX_0' data-points='W3sieCI6MTg0LjkyOTY4NzUsInkiOjM1fSx7IngiOjIyMy43MDMxMjUsInkiOjM1fSx7IngiOjMxNy4zNTIxNjM0NjE1Mzg0NSwieSI6MTY0fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M168.031%2c139L177.31%2c139C186.589%2c139%2c205.146%2c139%2c222.893%2c142.888C240.64%2c146.777%2c257.578%2c154.554%2c266.046%2c158.442L274.515%2c162.331' id='mermaid-1-L_TC_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TC_CTX_0' data-points='W3sieCI6MTY4LjAzMTI1LCJ5IjoxMzl9LHsieCI6MjIzLjcwMzEyNSwieSI6MTM5fSx7IngiOjI3OC4xNTAyNDAzODQ2MTUzNiwieSI6MTY0fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M176.93%2c243L184.725%2c243C192.521%2c243%2c208.112%2c243%2c224.376%2c239.112C240.64%2c235.223%2c257.578%2c227.446%2c266.046%2c223.558L274.515%2c219.669' id='mermaid-1-L_TR_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TR_CTX_0' data-points='W3sieCI6MTc2LjkyOTY4NzUsInkiOjI0M30seyJ4IjoyMjMuNzAzMTI1LCJ5IjoyNDN9LHsieCI6Mjc4LjE1MDI0MDM4NDYxNTM2LCJ5IjoyMTh9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M198.703%2c347L202.87%2c347C207.036%2c347%2c215.37%2c347%2c234.753%2c326.039C254.136%2c305.079%2c284.569%2c263.158%2c299.786%2c242.197L315.002%2c221.237' id='mermaid-1-L_RET_CTX_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RET_CTX_0' data-points='W3sieCI6MTk4LjcwMzEyNSwieSI6MzQ3fSx7IngiOjIyMy43MDMxMjUsInkiOjM0N30seyJ4IjozMTcuMzUyMTYzNDYxNTM4NDUsInkiOjIxOH1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M425.203%2c191L429.37%2c191C433.536%2c191%2c441.87%2c191%2c449.536%2c191C457.203%2c191%2c464.203%2c191%2c467.703%2c191L471.203%2c191' id='mermaid-1-L_CTX_GONE_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_CTX_GONE_0' data-points='W3sieCI6NDI1LjIwMzEyNSwieSI6MTkxfSx7IngiOjQ1MC4yMDMxMjUsInkiOjE5MX0seyJ4Ijo0NzUuMjAzMTI1LCJ5IjoxOTF9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_MSG_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TC_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TR_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_RET_CTX_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_CTX_GONE_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-MSG-0' data-look='classic' transform='translate(103.3515625%2c 35)'%3e%3crect class='basic label-container' style='' x='-81.578125' y='-27' width='163.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-51.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='103.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser Message%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-CTX-1' data-look='classic' transform='translate(336.953125%2c 191)'%3e%3crect class='basic label-container' style='' x='-88.25' y='-27' width='176.5' height='54'/%3e%3cg class='label' style='' transform='translate(-58.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='116.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContext Window%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-TC-2' data-look='classic' transform='translate(103.3515625%2c 139)'%3e%3crect class='basic label-container' style='' x='-64.6796875' y='-27' width='129.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-34.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='69.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool Calls%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-TR-4' data-look='classic' transform='translate(103.3515625%2c 243)'%3e%3crect class='basic label-container' style='' x='-73.578125' y='-27' width='147.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-43.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='87.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool Results%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-RET-6' data-look='classic' transform='translate(103.3515625%2c 347)'%3e%3crect class='basic label-container' style='' x='-95.3515625' y='-27' width='190.703125' height='54'/%3e%3cg class='label' style='' transform='translate(-65.3515625%2c -12)'%3e%3crect/%3e%3cforeignObject width='130.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRetrieved Memory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-GONE-9' data-look='classic' transform='translate(596.8203125%2c 191)'%3e%3crect class='basic label-container' style='' x='-121.6171875' y='-27' width='243.234375' height='54'/%3e%3cg class='label' style='' transform='translate(-91.6171875%2c -12)'%3e%3crect/%3e%3cforeignObject width='183.234375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDiscarded on request end%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-1-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Tier 2 — Session memory (one conversation)
This is the state kept alive across turns within a single conversation, but not beyond it. In practice it includes:
- The running transcript.
- A rolling summary of earlier turns once the transcript gets too long — the harness periodically asks the model to summarize the first half of the conversation so it can be compacted before it falls off the context window.
- Session-scoped variables the agent has accumulated: “the user is looking for a flight to Tokyo.”
Session memory is the cheap, stateful layer that makes a conversation feel coherent. It lives in memory (literally — in a cache or a database row keyed by conversation ID) and is cleared or expired when the session ends.
%3b%7d%23mermaid-2 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-2-gradient)%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M154.492%2c82.866L154.492%2c87.032C154.492%2c91.199%2c154.492%2c99.532%2c154.492%2c107.199C154.492%2c114.866%2c154.492%2c121.866%2c154.492%2c125.366L154.492%2c128.866' id='mermaid-2-L_DB_T_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_DB_T_0' data-points='W3sieCI6MTU0LjQ5MjE4NzUsInkiOjgyLjg2NTU2MjQzODk2NDg0fSx7IngiOjE1NC40OTIxODc1LCJ5IjoxMDcuODY1NTYyNDM4OTY0ODR9LHsieCI6MTU0LjQ5MjE4NzUsInkiOjEzMi44NjU1NjI0Mzg5NjQ4NH1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M97.188%2c65.656L88.21%2c72.691C79.232%2c79.726%2c61.276%2c93.796%2c52.298%2c109.497C43.32%2c125.199%2c43.32%2c142.532%2c43.32%2c161.866C43.32%2c181.199%2c43.32%2c202.532%2c48.239%2c218.862C53.158%2c235.192%2c62.995%2c246.519%2c67.914%2c252.182L72.833%2c257.846' id='mermaid-2-L_DB_RS_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_DB_RS_0' data-points='W3sieCI6OTcuMTg3NSwieSI6NjUuNjU2NDYxNjk5NTYyMn0seyJ4Ijo0My4zMjAzMTI1LCJ5IjoxMDcuODY1NTYyNDM4OTY0ODR9LHsieCI6NDMuMzIwMzEyNSwieSI6MTU5Ljg2NTU2MjQzODk2NDg0fSx7IngiOjQzLjMyMDMxMjUsInkiOjIyMy44NjU1NjI0Mzg5NjQ4NH0seyJ4Ijo3NS40NTU5MzI2MTcxODc1LCJ5IjoyNjAuODY1NTYyNDM4OTY0ODR9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M211.797%2c62.575L237.031%2c70.123C262.266%2c77.672%2c312.734%2c92.769%2c337.969%2c103.817C363.203%2c114.866%2c363.203%2c121.866%2c363.203%2c125.366L363.203%2c128.866' id='mermaid-2-L_DB_SV_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_DB_SV_0' data-points='W3sieCI6MjExLjc5Njg3NSwieSI6NjIuNTc0NjI4NTA1NDYwNDd9LHsieCI6MzYzLjIwMzEyNSwieSI6MTA3Ljg2NTU2MjQzODk2NDg0fSx7IngiOjM2My4yMDMxMjUsInkiOjEzMi44NjU1NjI0Mzg5NjQ4NH1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M154.492%2c186.866L154.492%2c193.032C154.492%2c199.199%2c154.492%2c211.532%2c149.573%2c223.362C144.655%2c235.192%2c134.817%2c246.519%2c129.898%2c252.182L124.98%2c257.846' id='mermaid-2-L_T_RS_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T_RS_0' data-points='W3sieCI6MTU0LjQ5MjE4NzUsInkiOjE4Ni44NjU1NjI0Mzg5NjQ4NH0seyJ4IjoxNTQuNDkyMTg3NSwieSI6MjIzLjg2NTU2MjQzODk2NDg0fSx7IngiOjEyMi4zNTY1NjczODI4MTI1LCJ5IjoyNjAuODY1NTYyNDM4OTY0ODR9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M363.203%2c186.866L363.203%2c193.032C363.203%2c199.199%2c363.203%2c211.532%2c363.203%2c223.199C363.203%2c234.866%2c363.203%2c245.866%2c363.203%2c251.366L363.203%2c256.866' id='mermaid-2-L_SV_GONE_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_SV_GONE_0' data-points='W3sieCI6MzYzLjIwMzEyNSwieSI6MTg2Ljg2NTU2MjQzODk2NDg0fSx7IngiOjM2My4yMDMxMjUsInkiOjIyMy44NjU1NjI0Mzg5NjQ4NH0seyJ4IjozNjMuMjAzMTI1LCJ5IjoyNjAuODY1NTYyNDM4OTY0ODR9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_DB_T_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_DB_RS_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_DB_SV_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(154.4921875%2c 223.86556243896484)'%3e%3cg class='label' data-id='L_T_RS_0' transform='translate(-91.171875%2c -12)'%3e%3cforeignObject width='182.34375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3ecompacted when too long%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(363.203125%2c 223.86556243896484)'%3e%3cg class='label' data-id='L_SV_GONE_0' transform='translate(-82.28125%2c -12)'%3e%3cforeignObject width='164.5625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3ecleared on session end%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-DB-0' data-look='classic' transform='translate(154.4921875%2c 45.43278121948242)'%3e%3cpath d='M0%2c11.957939354417999 a57.3046875%2c11.957939354417999 0%2c0%2c0 114.609375%2c0 a57.3046875%2c11.957939354417999 0%2c0%2c0 -114.609375%2c0 l0%2c50.957939354418 a57.3046875%2c11.957939354417999 0%2c0%2c0 114.609375%2c0 l0%2c-50.957939354418' class='basic label-container outer-path' style='' transform='translate(-57.3046875%2c -37.436909031626996)'/%3e%3cg class='label' style='' transform='translate(-49.8046875%2c -2)'%3e%3crect/%3e%3cforeignObject width='99.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSession Store%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-T-1' data-look='classic' transform='translate(154.4921875%2c 159.86556243896484)'%3e%3crect class='basic label-container' style='' x='-65.265625' y='-27' width='130.53125' height='54'/%3e%3cg class='label' style='' transform='translate(-35.265625%2c -12)'%3e%3crect/%3e%3cforeignObject width='70.53125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTranscript%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-RS-3' data-look='classic' transform='translate(98.90625%2c 287.86556243896484)'%3e%3crect class='basic label-container' style='' x='-90.90625' y='-27' width='181.8125' height='54'/%3e%3cg class='label' style='' transform='translate(-60.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='121.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRolling Summary%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-SV-5' data-look='classic' transform='translate(363.203125%2c 159.86556243896484)'%3e%3crect class='basic label-container' style='' x='-93.4453125' y='-27' width='186.890625' height='54'/%3e%3cg class='label' style='' transform='translate(-63.4453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='126.890625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSession Variables%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-GONE-9' data-look='classic' transform='translate(363.203125%2c 287.86556243896484)'%3e%3crect class='basic label-container' style='' x='-57.125' y='-27' width='114.25' height='54'/%3e%3cg class='label' style='' transform='translate(-27.125%2c -12)'%3e%3crect/%3e%3cforeignObject width='54.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eExpired%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-2-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Tier 3 — Long-term memory (across sessions)
This is where the real work is. Long-term memory survives across sessions, conversations, weeks, months. It is what makes an agent feel like a continuing presence rather than a series of disconnected strangers.
Crucially, long-term memory is not one thing. Psychologists split human long-term memory into three categories, and the same taxonomy turns out to be a useful design guide for agents.
Semantic memory — facts the agent has learned. Your name. Your role. Your project’s architecture. Your code style. Your preferred response length. These are static-ish facts that don’t belong to any one conversation but apply across many. They’re usually stored as short natural-language statements (“the user prefers TypeScript over JavaScript”) with metadata (when learned, confidence, source).
Episodic memory — events that happened. “On April 12, the agent and the user debugged the checkout bug together. The root cause was a stale cache.” These are narrative records of what happened, often including the agent’s own actions and observations. Episodic memory is what lets an agent say, correctly, “we looked at this last week — do you want to pick up where we left off?”
Procedural memory — how-to skills. “When the user asks to deploy, run these three tools in this order, wait for CI, then report back.” Procedural memory is the agent’s accumulated repertoire of routines — patterns that worked well and should be repeated. It is the slowest-growing, longest-lived kind of memory, and often the most valuable.
Production systems often store these three kinds separately, with different writers, different retrievers, and different retention policies. Mixing them is possible but usually makes retrieval worse.
%3b%7d%23mermaid-3 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-3 .cluster text%7bfill:%23333%3b%7d%23mermaid-3 .cluster span%7bcolor:%23333%3b%7d%23mermaid-3 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-3 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-3 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-3 .icon-shape%2c%23mermaid-3 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-3 .icon-shape p%2c%23mermaid-3 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-3 .icon-shape .label rect%2c%23mermaid-3 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-3 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-3 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-3-gradient)%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M295.883%2c56.683L268.169%2c61.735C240.456%2c66.788%2c185.029%2c76.894%2c157.315%2c85.447C129.602%2c94%2c129.602%2c101%2c129.602%2c104.5L129.602%2c108' id='mermaid-3-L_LTM_SEM_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_LTM_SEM_0' data-points='W3sieCI6Mjk1Ljg4MjgxMjUsInkiOjU2LjY4MjU3MjcyNzc3MDc3Nn0seyJ4IjoxMjkuNjAxNTYyNSwieSI6ODd9LHsieCI6MTI5LjYwMTU2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M414.805%2c62L414.805%2c66.167C414.805%2c70.333%2c414.805%2c78.667%2c414.805%2c86.333C414.805%2c94%2c414.805%2c101%2c414.805%2c104.5L414.805%2c108' id='mermaid-3-L_LTM_EPI_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_LTM_EPI_0' data-points='W3sieCI6NDE0LjgwNDY4NzUsInkiOjYyfSx7IngiOjQxNC44MDQ2ODc1LCJ5Ijo4N30seyJ4Ijo0MTQuODA0Njg3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M533.727%2c58.596L557.585%2c63.33C581.443%2c68.064%2c629.159%2c77.532%2c653.017%2c85.766C676.875%2c94%2c676.875%2c101%2c676.875%2c104.5L676.875%2c108' id='mermaid-3-L_LTM_PRO_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_LTM_PRO_0' data-points='W3sieCI6NTMzLjcyNjU2MjUsInkiOjU4LjU5NjQ4MjMzNzE1OTA0fSx7IngiOjY3Ni44NzUsInkiOjg3fSx7IngiOjY3Ni44NzUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_LTM_SEM_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_LTM_EPI_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_LTM_PRO_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-3-flowchart-LTM-0' data-look='classic' transform='translate(414.8046875%2c 35)'%3e%3crect class='basic label-container' style='' x='-118.921875' y='-27' width='237.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-88.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='177.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLong-term Memory Store%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-SEM-2' data-look='classic' transform='translate(129.6015625%2c 139)'%3e%3crect class='basic label-container' style='' x='-121.6015625' y='-27' width='243.203125' height='54'/%3e%3cg class='label' style='' transform='translate(-91.6015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='183.203125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSemantic %e2%80%94 facts learned%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-EPI-4' data-look='classic' transform='translate(414.8046875%2c 139)'%3e%3crect class='basic label-container' style='' x='-113.6015625' y='-27' width='227.203125' height='54'/%3e%3cg class='label' style='' transform='translate(-83.6015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='167.203125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEpisodic %e2%80%94 past events%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-PRO-6' data-look='classic' transform='translate(676.875%2c 139)'%3e%3crect class='basic label-container' style='' x='-98.46875' y='-27' width='196.9375' height='54'/%3e%3cg class='label' style='' transform='translate(-68.46875%2c -12)'%3e%3crect/%3e%3cforeignObject width='136.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eProcedural %e2%80%94 skills%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-3-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Tier 4 — Memory retrieval at inference
All the memory in the world is useless if it can’t be pulled into the context window at the right moment. This tier is the retriever — and mechanically, it is exactly the same idea as RAG from post 4.
When a new user message arrives, the harness:
- Embeds the message (and maybe the recent conversation) into a vector.
- Searches the long-term memory store for the most relevant facts, events, and skills.
- Injects the top matches into the system prompt or an early message, as a compact block of “things the agent remembers.”
This is RAG for the agent’s own past. Everything you know about retrieval — chunking, hybrid search, re-ranking, failure modes — applies here too.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-4 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-4 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-4 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-4 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-4 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-4 .sequenceNumber%7bfill:white%3b%7d%23mermaid-4 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-4 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-4 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-4 .labelText%2c%23mermaid-4 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .loopText%2c%23mermaid-4 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-4 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-4 .noteText%2c%23mermaid-4 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-4 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-4 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-4 .actor-man circle%2c%23mermaid-4 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-4 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-4 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node rect%2c%23mermaid-4 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-4 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-4-gradient)%3bstroke-width:1px%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-4-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-4-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-4-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='186' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eNew message arrives%3c/text%3e%3cline x1='76' y1='109' x2='295' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='U' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='300' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eEmbed message to vector%3c/text%3e%3cpath d='M 300%2c153 C 360%2c143 360%2c183 300%2c173' class='messageLine0' data-et='message' data-id='i1' data-from='H' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='418' y='198' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSearch memory store%3c/text%3e%3cline x1='300' y1='227' x2='535' y2='227' class='messageLine0' data-et='message' data-id='i2' data-from='H' data-to='V' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='421' y='242' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eTop matching memories%3c/text%3e%3cline x1='538' y1='271' x2='303' y2='271' class='messageLine1' data-et='message' data-id='i3' data-from='V' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='518' y='286' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eInject memories into prompt%3c/text%3e%3cline x1='300' y1='315' x2='735' y2='315' class='messageLine0' data-et='message' data-id='i4' data-from='H' data-to='P' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='521' y='330' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eModel receives augmented context%3c/text%3e%3cline x1='738' y1='359' x2='303' y2='359' class='messageLine1' data-et='message' data-id='i5' data-from='P' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3c/svg%3e)
What to remember — and what to forget
This is the part of the design that’s easy to underweight. You cannot simply save everything. You have a budget (context window and storage), and you have a cost (irrelevant memories distract the model). Every production memory system is, fundamentally, a deliberate forgetting system.
A few common policies, in rough order of sophistication:
1. Write-everything, retrieve-on-relevance. Save every turn’s raw content to the store, and rely on the retriever to pull only what’s relevant. Works for small scales, breaks at larger ones because retrieval noise grows.
2. Summarize-then-save. After each session, have a model distill what happened into a compact note (a few sentences per fact, per event, per learned routine) and save those rather than the raw transcript. Storage stays small, retrieval stays sharp.
3. Explicit memory tools. Give the model a tool it can call to save something: remember(statement). The model decides what’s memorable. This sounds fragile and in practice works surprisingly well — models are reasonable judges of what’s worth saving when asked directly.
4. Time decay. Older memories gradually weigh less in retrieval, and eventually get pruned. “Active last month” beats “active two years ago” for most purposes.
5. Consolidation jobs. Periodically, an offline process re-reads the memory store and collapses duplicates, resolves contradictions, and abstracts patterns from episodic memories into procedural ones. This is the closest thing to a “sleep cycle” in agent design, and it’s where the most durable long-term memory comes from.
Small agent products can skip most of this. Large ones that stay useful for years have all of it.
%3b%7d%23mermaid-5 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-5 .cluster text%7bfill:%23333%3b%7d%23mermaid-5 .cluster span%7bcolor:%23333%3b%7d%23mermaid-5 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-5 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-5 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-5 .icon-shape%2c%23mermaid-5 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-5 .icon-shape p%2c%23mermaid-5 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-5 .icon-shape .label rect%2c%23mermaid-5 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-5 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-5 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-5 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node rect%2c%23mermaid-5 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-5 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-5-gradient)%3bstroke-width:1px%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M115.367%2c86L115.367%2c92.167C115.367%2c98.333%2c115.367%2c110.667%2c115.367%2c122.333C115.367%2c134%2c115.367%2c145%2c115.367%2c150.5L115.367%2c156' id='mermaid-5-L_P1_P2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P1_P2_0' data-points='W3sieCI6MTE1LjM2NzE4NzUsInkiOjg2fSx7IngiOjExNS4zNjcxODc1LCJ5IjoxMjN9LHsieCI6MTE1LjM2NzE4NzUsInkiOjE2MH1d' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M115.367%2c214L115.367%2c218.167C115.367%2c222.333%2c115.367%2c230.667%2c115.367%2c238.333C115.367%2c246%2c115.367%2c253%2c115.367%2c256.5L115.367%2c260' id='mermaid-5-L_P2_P3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P2_P3_0' data-points='W3sieCI6MTE1LjM2NzE4NzUsInkiOjIxNH0seyJ4IjoxMTUuMzY3MTg3NSwieSI6MjM5fSx7IngiOjExNS4zNjcxODc1LCJ5IjoyNjR9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M115.367%2c318L115.367%2c322.167C115.367%2c326.333%2c115.367%2c334.667%2c115.367%2c342.333C115.367%2c350%2c115.367%2c357%2c115.367%2c360.5L115.367%2c364' id='mermaid-5-L_P3_P4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P3_P4_0' data-points='W3sieCI6MTE1LjM2NzE4NzUsInkiOjMxOH0seyJ4IjoxMTUuMzY3MTg3NSwieSI6MzQzfSx7IngiOjExNS4zNjcxODc1LCJ5IjozNjh9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M115.367%2c422L115.367%2c426.167C115.367%2c430.333%2c115.367%2c438.667%2c115.367%2c446.333C115.367%2c454%2c115.367%2c461%2c115.367%2c464.5L115.367%2c468' id='mermaid-5-L_P4_P5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P4_P5_0' data-points='W3sieCI6MTE1LjM2NzE4NzUsInkiOjQyMn0seyJ4IjoxMTUuMzY3MTg3NSwieSI6NDQ3fSx7IngiOjExNS4zNjcxODc1LCJ5Ijo0NzJ9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(115.3671875%2c 123)'%3e%3cg class='label' data-id='L_P1_P2_0' transform='translate(-72.484375%2c -12)'%3e%3cforeignObject width='144.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3enoise grows at scale%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_P2_P3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_P3_P4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_P4_P5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-5-flowchart-P1-0' data-look='classic' transform='translate(115.3671875%2c 47)'%3e%3crect class='basic label-container' style='' x='-87.359375' y='-39' width='174.71875' height='78'/%3e%3cg class='label' style='' transform='translate(-57.359375%2c -24)'%3e%3crect/%3e%3cforeignObject width='114.71875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWrite all%3cbr /%3eretrieve relevant%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-P2-1' data-look='classic' transform='translate(115.3671875%2c 187)'%3e%3crect class='basic label-container' style='' x='-107.3671875' y='-27' width='214.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-77.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='154.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSummarize then save%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-P3-3' data-look='classic' transform='translate(115.3671875%2c 291)'%3e%3crect class='basic label-container' style='' x='-105.578125' y='-27' width='211.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-75.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='151.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eExplicit memory tools%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-P4-5' data-look='classic' transform='translate(115.3671875%2c 395)'%3e%3crect class='basic label-container' style='' x='-71.0546875' y='-27' width='142.109375' height='54'/%3e%3cg class='label' style='' transform='translate(-41.0546875%2c -12)'%3e%3crect/%3e%3cforeignObject width='82.109375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTime decay%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-P5-7' data-look='classic' transform='translate(115.3671875%2c 499)'%3e%3crect class='basic label-container' style='' x='-95.375' y='-27' width='190.75' height='54'/%3e%3cg class='label' style='' transform='translate(-65.375%2c -12)'%3e%3crect/%3e%3cforeignObject width='130.75' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eConsolidation jobs%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-5-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
The subtle danger of remembering too much
Every item stored in long-term memory is an item that might be retrieved and injected into a future prompt. Sometimes that’s what you want. Often it isn’t.
Three real failure modes:
%3b%7d%23mermaid-6 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-6 .cluster text%7bfill:%23333%3b%7d%23mermaid-6 .cluster span%7bcolor:%23333%3b%7d%23mermaid-6 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-6 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-6 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-6 .icon-shape%2c%23mermaid-6 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-6 .icon-shape p%2c%23mermaid-6 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-6 .icon-shape .label rect%2c%23mermaid-6 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-6 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-6 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-6 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node rect%2c%23mermaid-6 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-6 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-6-gradient)%3bstroke-width:1px%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M333.203%2c49.516L298.478%2c55.764C263.753%2c62.011%2c194.302%2c74.505%2c159.577%2c84.253C124.852%2c94%2c124.852%2c101%2c124.852%2c104.5L124.852%2c108' id='mermaid-6-L_FM_S_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_FM_S_0' data-points='W3sieCI6MzMzLjIwMzEyNSwieSI6NDkuNTE2MjA0MDE2NTQxODg0fSx7IngiOjEyNC44NTE1NjI1LCJ5Ijo4N30seyJ4IjoxMjQuODUxNTYyNSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M413.891%2c62L413.891%2c66.167C413.891%2c70.333%2c413.891%2c78.667%2c413.891%2c86.333C413.891%2c94%2c413.891%2c101%2c413.891%2c104.5L413.891%2c108' id='mermaid-6-L_FM_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_FM_C_0' data-points='W3sieCI6NDEzLjg5MDYyNSwieSI6NjJ9LHsieCI6NDEzLjg5MDYyNSwieSI6ODd9LHsieCI6NDEzLjg5MDYyNSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M494.578%2c49.39L529.725%2c55.658C564.872%2c61.927%2c635.167%2c74.463%2c670.314%2c84.232C705.461%2c94%2c705.461%2c101%2c705.461%2c104.5L705.461%2c108' id='mermaid-6-L_FM_PR_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_FM_PR_0' data-points='W3sieCI6NDk0LjU3ODEyNSwieSI6NDkuMzkwMTgyNDcwOTk0ODh9LHsieCI6NzA1LjQ2MDkzNzUsInkiOjg3fSx7IngiOjcwNS40NjA5Mzc1LCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M124.852%2c166L124.852%2c172.167C124.852%2c178.333%2c124.852%2c190.667%2c124.852%2c202.333C124.852%2c214%2c124.852%2c225%2c124.852%2c230.5L124.852%2c236' id='mermaid-6-L_S_TD_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_TD_0' data-points='W3sieCI6MTI0Ljg1MTU2MjUsInkiOjE2Nn0seyJ4IjoxMjQuODUxNTYyNSwieSI6MjAzfSx7IngiOjEyNC44NTE1NjI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M413.891%2c166L413.891%2c172.167C413.891%2c178.333%2c413.891%2c190.667%2c413.891%2c202.333C413.891%2c214%2c413.891%2c225%2c413.891%2c230.5L413.891%2c236' id='mermaid-6-L_C_TS_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_TS_0' data-points='W3sieCI6NDEzLjg5MDYyNSwieSI6MTY2fSx7IngiOjQxMy44OTA2MjUsInkiOjIwM30seyJ4Ijo0MTMuODkwNjI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M705.461%2c166L705.461%2c172.167C705.461%2c178.333%2c705.461%2c190.667%2c705.461%2c202.333C705.461%2c214%2c705.461%2c225%2c705.461%2c230.5L705.461%2c236' id='mermaid-6-L_PR_PII_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PR_PII_0' data-points='W3sieCI6NzA1LjQ2MDkzNzUsInkiOjE2Nn0seyJ4Ijo3MDUuNDYwOTM3NSwieSI6MjAzfSx7IngiOjcwNS40NjA5Mzc1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_FM_S_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_FM_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_FM_PR_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(124.8515625%2c 203)'%3e%3cg class='label' data-id='L_S_TD_0' transform='translate(-8%2c -12)'%3e%3cforeignObject width='16' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3efix%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(413.890625%2c 203)'%3e%3cg class='label' data-id='L_C_TS_0' transform='translate(-8%2c -12)'%3e%3cforeignObject width='16' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3efix%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(705.4609375%2c 203)'%3e%3cg class='label' data-id='L_PR_PII_0' transform='translate(-8%2c -12)'%3e%3cforeignObject width='16' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3efix%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-FM-0' data-look='classic' transform='translate(413.890625%2c 35)'%3e%3crect class='basic label-container' style='' x='-80.6875' y='-27' width='161.375' height='54'/%3e%3cg class='label' style='' transform='translate(-50.6875%2c -12)'%3e%3crect/%3e%3cforeignObject width='101.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFailure Modes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-S-2' data-look='classic' transform='translate(124.8515625%2c 139)'%3e%3crect class='basic label-container' style='' x='-79.3515625' y='-27' width='158.703125' height='54'/%3e%3cg class='label' style='' transform='translate(-49.3515625%2c -12)'%3e%3crect/%3e%3cforeignObject width='98.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStale Memory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-C-4' data-look='classic' transform='translate(413.890625%2c 139)'%3e%3crect class='basic label-container' style='' x='-81.140625' y='-27' width='162.28125' height='54'/%3e%3cg class='label' style='' transform='translate(-51.140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='102.28125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContradictions%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-PR-6' data-look='classic' transform='translate(705.4609375%2c 139)'%3e%3crect class='basic label-container' style='' x='-86.0234375' y='-27' width='172.046875' height='54'/%3e%3cg class='label' style='' transform='translate(-56.0234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='112.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePrivacy Surface%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-TD-8' data-look='classic' transform='translate(124.8515625%2c 267)'%3e%3crect class='basic label-container' style='' x='-116.8515625' y='-27' width='233.703125' height='54'/%3e%3cg class='label' style='' transform='translate(-86.8515625%2c -12)'%3e%3crect/%3e%3cforeignObject width='173.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTime decay re-validation%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-TS-10' data-look='classic' transform='translate(413.890625%2c 267)'%3e%3crect class='basic label-container' style='' x='-122.1875' y='-27' width='244.375' height='54'/%3e%3cg class='label' style='' transform='translate(-92.1875%2c -12)'%3e%3crect/%3e%3cforeignObject width='184.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTimestamps consolidation%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-PII-12' data-look='classic' transform='translate(705.4609375%2c 267)'%3e%3crect class='basic label-container' style='' x='-119.3828125' y='-27' width='238.765625' height='54'/%3e%3cg class='label' style='' transform='translate(-89.3828125%2c -12)'%3e%3crect/%3e%3cforeignObject width='178.765625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNever save PII by default%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-6-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
1. Stale memory. The agent learned last year that you were a Python developer. You’ve been writing Rust for six months. The stale fact is still being retrieved and is subtly shaping every reply. Fix: time decay, explicit overwriting, or periodic re-validation (“is this still true?”).
2. Contradictory memory. The agent remembers that your preferred deploy command is ./scripts/deploy.sh. It also remembers, from a later session, that you now use make deploy. Which gets retrieved? Both, sometimes. The model gets confused. Fix: store timestamps, prefer newer, consolidate.
3. Privacy surface. Everything saved to long-term memory is something that can, in principle, leak back out in a future response. “Write me a cover letter” is a safe thing to remember. Medical details, financial credentials, or personal content from another conversation are not. Fix: explicit categories for what’s memorable (never save PII by default), and a clear path for the user to inspect and delete.
Memory for tools and skills, not just chat
It’s easy to think about memory as being about chat history. The more interesting kind, for agents, is memory about the agent’s own actions.
%3b%7d%23mermaid-7 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-7 .cluster text%7bfill:%23333%3b%7d%23mermaid-7 .cluster span%7bcolor:%23333%3b%7d%23mermaid-7 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-7 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-7 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-7 .icon-shape%2c%23mermaid-7 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-7 .icon-shape p%2c%23mermaid-7 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-7 .icon-shape .label rect%2c%23mermaid-7 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-7 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-7 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-7 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node rect%2c%23mermaid-7 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-7 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-7-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-7-gradient)%3bstroke-width:1px%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-7-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-7-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-7 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-7-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-7 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-7_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-7_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M310.57%2c50.762L278.633%2c56.802C246.695%2c62.842%2c182.82%2c74.921%2c150.883%2c84.46C118.945%2c94%2c118.945%2c101%2c118.945%2c104.5L118.945%2c108' id='mermaid-7-L_AM_DE_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AM_DE_0' data-points='W3sieCI6MzEwLjU3MDMxMjUsInkiOjUwLjc2MjM2NjExMDc0ODA3Nn0seyJ4IjoxMTguOTQ1MzEyNSwieSI6ODd9LHsieCI6MTE4Ljk0NTMxMjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3cpath d='M393.922%2c62L393.922%2c66.167C393.922%2c70.333%2c393.922%2c78.667%2c393.922%2c86.333C393.922%2c94%2c393.922%2c101%2c393.922%2c104.5L393.922%2c108' id='mermaid-7-L_AM_OK_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AM_OK_0' data-points='W3sieCI6MzkzLjkyMTg3NSwieSI6NjJ9LHsieCI6MzkzLjkyMTg3NSwieSI6ODd9LHsieCI6MzkzLjkyMTg3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3cpath d='M477.273%2c51.594L506.915%2c57.495C536.557%2c63.396%2c595.841%2c75.198%2c625.483%2c84.599C655.125%2c94%2c655.125%2c101%2c655.125%2c104.5L655.125%2c108' id='mermaid-7-L_AM_PC_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AM_PC_0' data-points='W3sieCI6NDc3LjI3MzQzNzUsInkiOjUxLjU5MzUyNzU0NjgwODY0fSx7IngiOjY1NS4xMjUsInkiOjg3fSx7IngiOjY1NS4xMjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3cpath d='M118.945%2c166L118.945%2c172.167C118.945%2c178.333%2c118.945%2c190.667%2c118.945%2c202.333C118.945%2c214%2c118.945%2c225%2c118.945%2c230.5L118.945%2c236' id='mermaid-7-L_DE_DE1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_DE_DE1_0' data-points='W3sieCI6MTE4Ljk0NTMxMjUsInkiOjE2Nn0seyJ4IjoxMTguOTQ1MzEyNSwieSI6MjAzfSx7IngiOjExOC45NDUzMTI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3cpath d='M393.922%2c166L393.922%2c172.167C393.922%2c178.333%2c393.922%2c190.667%2c393.922%2c202.333C393.922%2c214%2c393.922%2c225%2c393.922%2c230.5L393.922%2c236' id='mermaid-7-L_OK_OK1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_OK_OK1_0' data-points='W3sieCI6MzkzLjkyMTg3NSwieSI6MTY2fSx7IngiOjM5My45MjE4NzUsInkiOjIwM30seyJ4IjozOTMuOTIxODc1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3cpath d='M655.125%2c166L655.125%2c172.167C655.125%2c178.333%2c655.125%2c190.667%2c655.125%2c202.333C655.125%2c214%2c655.125%2c225%2c655.125%2c230.5L655.125%2c236' id='mermaid-7-L_PC_PC1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PC_PC1_0' data-points='W3sieCI6NjU1LjEyNSwieSI6MTY2fSx7IngiOjY1NS4xMjUsInkiOjIwM30seyJ4Ijo2NTUuMTI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-7_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AM_DE_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AM_OK_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AM_PC_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(118.9453125%2c 203)'%3e%3cg class='label' data-id='L_DE_DE1_0' transform='translate(-30.2421875%2c -12)'%3e%3cforeignObject width='60.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eexample%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(393.921875%2c 203)'%3e%3cg class='label' data-id='L_OK_OK1_0' transform='translate(-30.2421875%2c -12)'%3e%3cforeignObject width='60.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eexample%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(655.125%2c 203)'%3e%3cg class='label' data-id='L_PC_PC1_0' transform='translate(-30.2421875%2c -12)'%3e%3cforeignObject width='60.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eexample%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-7-flowchart-AM-0' data-look='classic' transform='translate(393.921875%2c 35)'%3e%3crect class='basic label-container' style='' x='-83.3515625' y='-27' width='166.703125' height='54'/%3e%3cg class='label' style='' transform='translate(-53.3515625%2c -12)'%3e%3crect/%3e%3cforeignObject width='106.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAction Memory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-DE-2' data-look='classic' transform='translate(118.9453125%2c 139)'%3e%3crect class='basic label-container' style='' x='-104.71875' y='-27' width='209.4375' height='54'/%3e%3cg class='label' style='' transform='translate(-74.71875%2c -12)'%3e%3crect/%3e%3cforeignObject width='149.4375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDead-end prevention%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-OK-4' data-look='classic' transform='translate(393.921875%2c 139)'%3e%3crect class='basic label-container' style='' x='-111.8359375' y='-27' width='223.671875' height='54'/%3e%3cg class='label' style='' transform='translate(-81.8359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='163.671875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOperational knowledge%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-PC-6' data-look='classic' transform='translate(655.125%2c 139)'%3e%3crect class='basic label-container' style='' x='-99.3671875' y='-27' width='198.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-69.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='138.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePermission caching%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-DE1-8' data-look='classic' transform='translate(118.9453125%2c 267)'%3e%3crect class='basic label-container' style='' x='-110.9453125' y='-27' width='221.890625' height='54'/%3e%3cg class='label' style='' transform='translate(-80.9453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='161.890625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSkip failed approaches%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-OK1-10' data-look='classic' transform='translate(393.921875%2c 267)'%3e%3crect class='basic label-container' style='' x='-114.03125' y='-27' width='228.0625' height='54'/%3e%3cg class='label' style='' transform='translate(-84.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='168.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRetry spurious timeouts%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-7-flowchart-PC1-12' data-look='classic' transform='translate(655.125%2c 267)'%3e%3crect class='basic label-container' style='' x='-94.921875' y='-27' width='189.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-64.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='129.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePrior edit approval%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-7-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-7-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-7-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- “Last time I tried this approach, the tool returned X.” (Prevents re-doing dead ends.)
- “The
deploytool often returns a spurious timeout; retry once before reporting failure.” (Learned operational knowledge.) - “The user has approved edits in this file before without re-asking.” (Reduces friction.)
This kind of memory is what turns an agent from “a chatty worker with a journal” into something that actually gets better at its job over time. It’s also the least-common kind in shipping products, because it requires clear write paths and a principled retrieval story — exactly the parts that are easy to skip in the first version of a product.
Where this rung ends
With working, session, and long-term memory in place, a single agent can carry out a multi-step job, remember across sessions, and improve over time. That’s already a remarkable thing. It is also, roughly, where most well-engineered products in 2026 live.
But there is a ceiling. A single agent can only hold so many skills at once before it becomes a jack of all trades and master of none. For big, differentiated work, the next move is to split the problem — give it to a team of agents with different specialties, supervised and monitored by a platform around them.
That’s the finale.
Read next: Multi-Agent Systems & Production Platforms.