Every rung below this one has been about improving what the model says. System prompts shape how it talks. RAG controls what it knows. Chat history lets it remember what you said. But on every one of those rungs, the model is still a text-in, text-out function. It tells you how to boil water. It does not boil water.
This rung — tool use — is where that changes.
It is the hinge of the entire ladder. Everything above it (agent loops, memory, multi-agent platforms) assumes tool use is in place. Everything below it is a fundamentally different kind of product. The moment your AI can reach out and press a real button, it stops being a chatbot and starts being an assistant. The same underlying model, given tools, becomes a qualitatively different thing.
Here’s how it actually works.
The conceptual shift
The core trick is so small it feels like cheating.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-After' data-look='classic'%3e%3crect style='' x='8' y='8' width='1135.046875' height='317.03125'/%3e%3cg class='cluster-label' transform='translate(539.5078125%2c 8)'%3e%3cforeignObject width='72.03125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAfter tools%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M151.75%2c201.031L158%2c201.031C164.25%2c201.031%2c176.75%2c201.031%2c188.583%2c201.031C200.417%2c201.031%2c211.583%2c201.031%2c217.167%2c201.031L222.75%2c201.031' id='mermaid-0-L_B1_B2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B1_B2_0' data-points='W3sieCI6MTUxLjc1LCJ5IjoyMDEuMDMxMjV9LHsieCI6MTg5LjI1LCJ5IjoyMDEuMDMxMjV9LHsieCI6MjI2Ljc1LCJ5IjoyMDEuMDMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M313.077%2c174.031L320.127%2c169.362C327.176%2c164.693%2c341.276%2c155.354%2c353.909%2c150.685C366.542%2c146.016%2c377.708%2c146.016%2c383.292%2c146.016L388.875%2c146.016' id='mermaid-0-L_B2_B3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B2_B3_0' data-points='W3sieCI6MzEzLjA3NzA1NTUyMzk5ODg3LCJ5IjoxNzQuMDMxMjV9LHsieCI6MzU1LjM3NSwieSI6MTQ2LjAxNTYyNX0seyJ4IjozOTIuODc1LCJ5IjoxNDYuMDE1NjI1fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M520.892%2c123.971L532.892%2c118.978C544.892%2c113.986%2c568.891%2c104.001%2c588.55%2c99.008C608.208%2c94.016%2c623.526%2c94.016%2c631.185%2c94.016L638.844%2c94.016' id='mermaid-0-L_B3_B4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B3_B4_0' data-points='W3sieCI6NTIwLjg5MjQ3NDgzODg4MDUsInkiOjEyMy45NzA1OTk4Mzg4ODA1NX0seyJ4Ijo1OTIuODkwNjI1LCJ5Ijo5NC4wMTU2MjV9LHsieCI6NjQyLjg0Mzc1LCJ5Ijo5NC4wMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M861.156%2c94.016L867.406%2c94.016C873.656%2c94.016%2c886.156%2c94.016%2c907.132%2c106.912C928.108%2c119.809%2c957.56%2c145.602%2c972.287%2c158.499L987.013%2c171.396' id='mermaid-0-L_B4_B5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B4_B5_0' data-points='W3sieCI6ODYxLjE1NjI1LCJ5Ijo5NC4wMTU2MjV9LHsieCI6ODk4LjY1NjI1LCJ5Ijo5NC4wMTU2MjV9LHsieCI6OTkwLjAyMTczMzMyNzg1ODEsInkiOjE3NC4wMzEyNX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M981.101%2c228.031L967.36%2c237.365C953.62%2c246.698%2c926.138%2c265.365%2c887.954%2c274.698C849.771%2c284.031%2c800.885%2c284.031%2c749.924%2c284.031C698.964%2c284.031%2c645.927%2c284.031%2c598.578%2c284.031C551.229%2c284.031%2c509.568%2c284.031%2c469.982%2c284.031C430.396%2c284.031%2c392.885%2c284.031%2c365.261%2c275.169C337.637%2c266.307%2c319.9%2c248.583%2c311.031%2c239.721L302.162%2c230.859' id='mermaid-0-L_B5_B2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B5_B2_0' data-points='W3sieCI6OTgxLjEwMTI4MDEyMDQ4MiwieSI6MjI4LjAzMTI1fSx7IngiOjg5OC42NTYyNSwieSI6Mjg0LjAzMTI1fSx7IngiOjc1MiwieSI6Mjg0LjAzMTI1fSx7IngiOjU5Mi44OTA2MjUsInkiOjI4NC4wMzEyNX0seyJ4Ijo0NjcuOTA2MjUsInkiOjI4NC4wMzEyNX0seyJ4IjozNTUuMzc1LCJ5IjoyODQuMDMxMjV9LHsieCI6Mjk5LjMzMjgzMTMyNTMwMTIsInkiOjIyOC4wMzEyNX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M520.892%2c168.061L532.892%2c173.053C544.892%2c178.046%2c568.891%2c188.031%2c597.073%2c193.023C625.255%2c198.016%2c657.62%2c198.016%2c673.802%2c198.016L689.984%2c198.016' id='mermaid-0-L_B3_B6_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B3_B6_0' data-points='W3sieCI6NTIwLjg5MjQ3NDgzODg4MDUsInkiOjE2OC4wNjA2NTAxNjExMTk0NH0seyJ4Ijo1OTIuODkwNjI1LCJ5IjoxOTguMDE1NjI1fSx7IngiOjY5My45ODQzNzUsInkiOjE5OC4wMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B1_B2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B2_B3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(592.890625%2c 94.015625)'%3e%3cg class='label' data-id='L_B3_B4_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B4_B5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B5_B2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(592.890625%2c 198.015625)'%3e%3cg class='label' data-id='L_B3_B6_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-B1-4' data-look='classic' transform='translate(98.625%2c 201.03125)'%3e%3crect class='basic label-container' style='' x='-53.125' y='-27' width='106.25' height='54'/%3e%3cg class='label' style='' transform='translate(-23.125%2c -12)'%3e%3crect/%3e%3cforeignObject width='46.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eText in%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B2-5' data-look='classic' transform='translate(272.3125%2c 201.03125)'%3e%3crect class='basic label-container' style='' x='-45.5625' y='-27' width='91.125' height='54'/%3e%3cg class='label' style='' transform='translate(-15.5625%2c -12)'%3e%3crect/%3e%3cforeignObject width='31.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLLM%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B3-7' data-look='classic' transform='translate(467.90625%2c 146.015625)'%3e%3cpolygon points='75.03125%2c0 150.0625%2c-75.03125 75.03125%2c-150.0625 0%2c-75.03125' class='label-container' transform='translate(-74.53125%2c 75.03125)'/%3e%3cg class='label' style='' transform='translate(-48.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='96.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool request%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B4-9' data-look='classic' transform='translate(752%2c 94.015625)'%3e%3crect class='basic label-container' style='' x='-109.15625' y='-27' width='218.3125' height='54'/%3e%3cg class='label' style='' transform='translate(-79.15625%2c -12)'%3e%3crect/%3e%3cforeignObject width='158.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eHarness executes tool%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B5-11' data-look='classic' transform='translate(1020.8515625%2c 201.03125)'%3e%3crect class='basic label-container' style='' x='-84.6953125' y='-27' width='169.390625' height='54'/%3e%3cg class='label' style='' transform='translate(-54.6953125%2c -12)'%3e%3crect/%3e%3cforeignObject width='109.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eResult returned%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B6-15' data-look='classic' transform='translate(752%2c 198.015625)'%3e%3crect class='basic label-container' style='' x='-58.015625' y='-27' width='116.03125' height='54'/%3e%3cg class='label' style='' transform='translate(-28.015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='56.03125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eText out%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1185.046875%2c 96.515625)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-Before' data-look='classic'%3e%3crect style='' x='8' y='8' width='538.40625' height='124'/%3e%3cg class='cluster-label' transform='translate(234.5078125%2c 8)'%3e%3cforeignObject width='85.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBefore tools%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M151.75%2c70L158%2c70C164.25%2c70%2c176.75%2c70%2c188.583%2c70C200.417%2c70%2c211.583%2c70%2c217.167%2c70L222.75%2c70' id='mermaid-0-L_A1_A2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A1_A2_0' data-points='W3sieCI6MTUxLjc1LCJ5Ijo3MH0seyJ4IjoxODkuMjUsInkiOjcwfSx7IngiOjIyNi43NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M317.875%2c70L324.125%2c70C330.375%2c70%2c342.875%2c70%2c354.708%2c70C366.542%2c70%2c377.708%2c70%2c383.292%2c70L388.875%2c70' id='mermaid-0-L_A2_A3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A2_A3_0' data-points='W3sieCI6MzE3Ljg3NSwieSI6NzB9LHsieCI6MzU1LjM3NSwieSI6NzB9LHsieCI6MzkyLjg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A1_A2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A2_A3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-A1-0' data-look='classic' transform='translate(98.625%2c 70)'%3e%3crect class='basic label-container' style='' x='-53.125' y='-27' width='106.25' height='54'/%3e%3cg class='label' style='' transform='translate(-23.125%2c -12)'%3e%3crect/%3e%3cforeignObject width='46.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eText in%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A2-1' data-look='classic' transform='translate(272.3125%2c 70)'%3e%3crect class='basic label-container' style='' x='-45.5625' y='-27' width='91.125' height='54'/%3e%3cg class='label' style='' transform='translate(-15.5625%2c -12)'%3e%3crect/%3e%3cforeignObject width='31.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLLM%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-A3-3' data-look='classic' transform='translate(450.890625%2c 70)'%3e%3crect class='basic label-container' style='' x='-58.015625' y='-27' width='116.03125' height='54'/%3e%3cg class='label' style='' transform='translate(-28.015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='56.03125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eText out%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
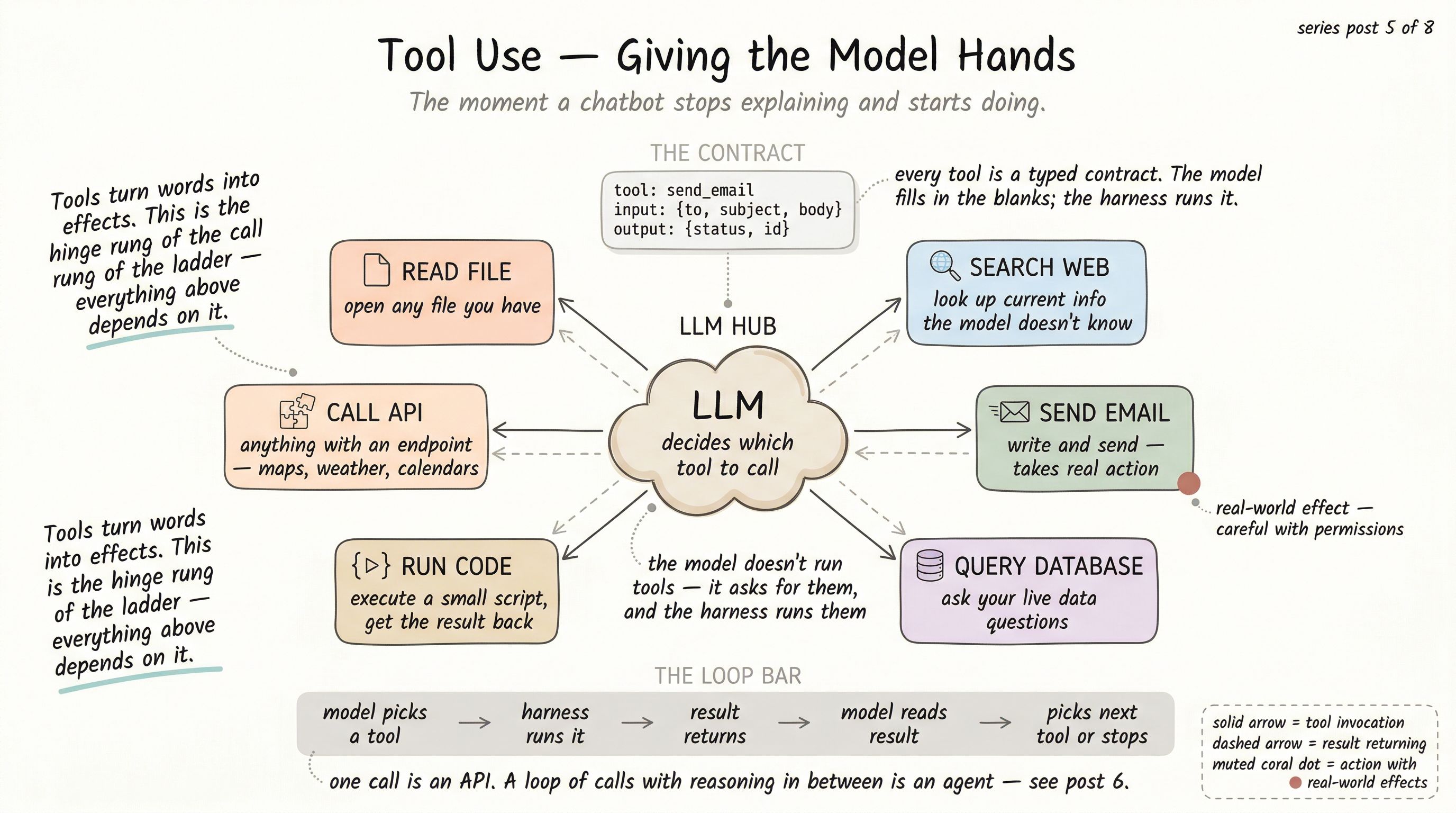
You show the model a menu of tools. For each tool, you describe: what it’s called, what it does, and what inputs it needs. You then tell the model — in the prompt — that when it wants to use a tool, it should emit a specific structured response (a small piece of JSON) naming the tool and filling in the inputs. Your harness watches for that response, runs the tool, and feeds the result back to the model as another message.
The model doesn’t run the tool. The model asks for the tool to be run.
That distinction is easy to gloss over and worth pausing on. The language model is still just producing text. What changed is that the harness around it now knows how to interpret certain pieces of that text as requests, execute them, and return the results. The model gained hands the way a person gains a phone: by being given a new way to affect the world beyond itself.
Anatomy of a tool call
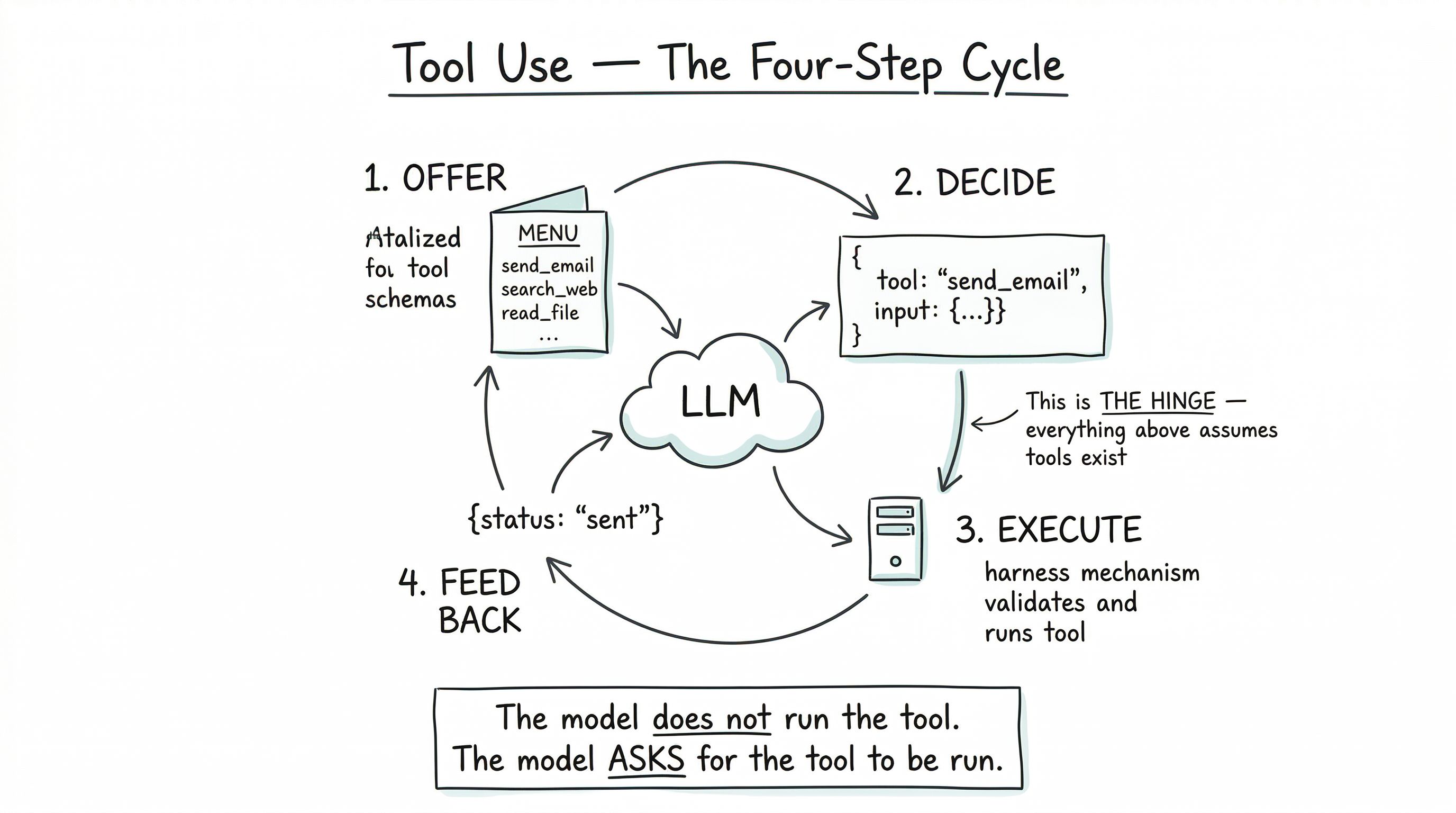
A single tool call involves four steps. Let’s walk through one concretely.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-1 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-1 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-1 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-1 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-1 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-1 .sequenceNumber%7bfill:white%3b%7d%23mermaid-1 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-1 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-1 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-1 .labelText%2c%23mermaid-1 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .loopText%2c%23mermaid-1 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-1 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-1 .noteText%2c%23mermaid-1 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-1 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-1 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-1 .actor-man circle%2c%23mermaid-1 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-1 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-1-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-1-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-1-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='217' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3esystem prompt %2b tool schemas%3c/text%3e%3cline x1='76' y1='109' x2='358' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='H' data-to='M' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='220' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3etool call request with inputs%3c/text%3e%3cline x1='361' y1='153' x2='79' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='M' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='317' y='168' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3evalidate inputs and execute%3c/text%3e%3cline x1='76' y1='197' x2='558' y2='197' class='messageLine0' data-et='message' data-id='i2' data-from='H' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='320' y='212' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eresult%3c/text%3e%3cline x1='561' y1='241' x2='79' y2='241' class='messageLine0' data-et='message' data-id='i3' data-from='T' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='217' y='256' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3etool result as new message%3c/text%3e%3cline x1='76' y1='285' x2='358' y2='285' class='messageLine0' data-et='message' data-id='i4' data-from='H' data-to='M' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='220' y='300' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3efinal text reply%3c/text%3e%3cline x1='361' y1='329' x2='79' y2='329' class='messageLine0' data-et='message' data-id='i5' data-from='M' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
Step 1 — The harness gives the model a tool schema.
{ "name": "send_email", "description": "Send an email on behalf of the user.", "input_schema": { "type": "object", "properties": { "to": {"type": "string", "format": "email"}, "subject": {"type": "string"}, "body": {"type": "string"} }, "required": ["to", "subject", "body"] }}This lives alongside the system prompt. The model sees all available tools every turn.
Step 2 — The model decides to call it. Given a user message like “Email my boss and let her know I’ll be late,” the model’s response is not prose. It’s a structured call:
{ "tool": "send_email", "input": { "to": "jane@company.com", "subject": "Running late this morning", "body": "Hi Jane — quick note, I'll be about 15 minutes late..." }}The model filled in plausible values based on context (it’s seen earlier in the conversation that “my boss” is Jane).
Step 3 — The harness validates and executes. The harness checks the input against the schema (is to really a valid email? is body within a sane length?), asks the user for permission if the tool is flagged as destructive, and — only then — actually calls whatever backend function sends an email. The tool returns a result:
{ "status": "sent", "id": "msg_0184a..." }Step 4 — The harness feeds the result back to the model. The tool result is appended to the conversation as a new message, flagged as a tool response. The model can now see what happened and decide what to say next — usually, “Sent. I told Jane you’ll be 15 minutes late.”
That four-step cycle — offer → decide → execute → feed back — is the entire mechanism. Everything else is scale.
The typed contract
The single most important thing about a tool is its schema. Not the function it calls, not its implementation — the schema the model sees.
%3b%7d%23mermaid-2 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-2-gradient)%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M414.918%2c45.15L363.438%2c52.125C311.958%2c59.1%2c208.999%2c73.05%2c157.519%2c83.525C106.039%2c94%2c106.039%2c101%2c106.039%2c104.5L106.039%2c108' id='mermaid-2-L_S_N_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_N_0' data-points='W3sieCI6NDE0LjkxNzk2ODc1LCJ5Ijo0NS4xNTAwODQ5ODY0MTIzNX0seyJ4IjoxMDYuMDM5MDYyNSwieSI6ODd9LHsieCI6MTA2LjAzOTA2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M420.403%2c62L409.689%2c66.167C398.975%2c70.333%2c377.546%2c78.667%2c366.832%2c86.333C356.117%2c94%2c356.117%2c101%2c356.117%2c104.5L356.117%2c108' id='mermaid-2-L_S_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_D_0' data-points='W3sieCI6NDIwLjQwMzE3MDA3MjExNTM2LCJ5Ijo2Mn0seyJ4IjozNTYuMTE3MTg3NSwieSI6ODd9LHsieCI6MzU2LjExNzE4NzUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M559.261%2c62L569.975%2c66.167C580.69%2c70.333%2c602.118%2c78.667%2c612.833%2c86.333C623.547%2c94%2c623.547%2c101%2c623.547%2c104.5L623.547%2c108' id='mermaid-2-L_S_I_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_I_0' data-points='W3sieCI6NTU5LjI2MDg5MjQyNzg4NDYsInkiOjYyfSx7IngiOjYyMy41NDY4NzUsInkiOjg3fSx7IngiOjYyMy41NDY4NzUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M564.746%2c44.92L617.71%2c51.933C670.674%2c58.947%2c776.603%2c72.973%2c829.567%2c83.487C882.531%2c94%2c882.531%2c101%2c882.531%2c104.5L882.531%2c108' id='mermaid-2-L_S_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S_E_0' data-points='W3sieCI6NTY0Ljc0NjA5Mzc1LCJ5Ijo0NC45MTk4ODU0MDg0ODA5NjV9LHsieCI6ODgyLjUzMTI1LCJ5Ijo4N30seyJ4Ijo4ODIuNTMxMjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M106.039%2c190L106.039%2c194.167C106.039%2c198.333%2c106.039%2c206.667%2c115.443%2c214.744C124.846%2c222.821%2c143.653%2c230.643%2c153.057%2c234.553L162.461%2c238.464' id='mermaid-2-L_N_Q_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_N_Q_0' data-points='W3sieCI6MTA2LjAzOTA2MjUsInkiOjE5MH0seyJ4IjoxMDYuMDM5MDYyNSwieSI6MjE1fSx7IngiOjE2Ni4xNTM5OTYzOTQyMzA3NywieSI6MjQwfV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M356.117%2c190L356.117%2c194.167C356.117%2c198.333%2c356.117%2c206.667%2c346.714%2c214.744C337.31%2c222.821%2c318.503%2c230.643%2c309.099%2c234.553L299.696%2c238.464' id='mermaid-2-L_D_Q_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_Q_0' data-points='W3sieCI6MzU2LjExNzE4NzUsInkiOjE5MH0seyJ4IjozNTYuMTE3MTg3NSwieSI6MjE1fSx7IngiOjI5Ni4wMDIyNTM2MDU3NjkyLCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M623.547%2c190L623.547%2c194.167C623.547%2c198.333%2c623.547%2c206.667%2c633.304%2c214.752C643.062%2c222.836%2c662.576%2c230.673%2c672.334%2c234.591L682.091%2c238.509' id='mermaid-2-L_I_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_R_0' data-points='W3sieCI6NjIzLjU0Njg3NSwieSI6MTkwfSx7IngiOjYyMy41NDY4NzUsInkiOjIxNX0seyJ4Ijo2ODUuODAyNzM0Mzc1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M882.531%2c190L882.531%2c194.167C882.531%2c198.333%2c882.531%2c206.667%2c872.774%2c214.752C863.017%2c222.836%2c843.502%2c230.673%2c833.745%2c234.591L823.987%2c238.509' id='mermaid-2-L_E_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_R_0' data-points='W3sieCI6ODgyLjUzMTI1LCJ5IjoxOTB9LHsieCI6ODgyLjUzMTI1LCJ5IjoyMTV9LHsieCI6ODIwLjI3NTM5MDYyNSwieSI6MjQwfV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_N_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_I_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_N_Q_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_Q_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_R_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_R_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-S-0' data-look='classic' transform='translate(489.83203125%2c 35)'%3e%3crect class='basic label-container' style='' x='-74.9140625' y='-27' width='149.828125' height='54'/%3e%3cg class='label' style='' transform='translate(-44.9140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='89.828125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool schema%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-N-1' data-look='classic' transform='translate(106.0390625%2c 151)'%3e%3crect class='basic label-container' style='' x='-98.0390625' y='-39' width='196.078125' height='78'/%3e%3cg class='label' style='' transform='translate(-68.0390625%2c -24)'%3e%3crect/%3e%3cforeignObject width='136.078125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eName%3cbr /%3ewhen to reach for it%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-D-3' data-look='classic' transform='translate(356.1171875%2c 151)'%3e%3crect class='basic label-container' style='' x='-102.0390625' y='-39' width='204.078125' height='78'/%3e%3cg class='label' style='' transform='translate(-72.0390625%2c -24)'%3e%3crect/%3e%3cforeignObject width='144.078125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDescription%3cbr /%3ewhat it actually does%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-I-5' data-look='classic' transform='translate(623.546875%2c 151)'%3e%3crect class='basic label-container' style='' x='-115.390625' y='-39' width='230.78125' height='78'/%3e%3cg class='label' style='' transform='translate(-85.390625%2c -24)'%3e%3crect/%3e%3cforeignObject width='170.78125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eInput fields%3cbr /%3etypes and required flags%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-E-7' data-look='classic' transform='translate(882.53125%2c 151)'%3e%3crect class='basic label-container' style='' x='-93.59375' y='-39' width='187.1875' height='78'/%3e%3cg class='label' style='' transform='translate(-63.59375%2c -24)'%3e%3crect/%3e%3cforeignObject width='127.1875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eExamples%3cbr /%3eshows a good call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-Q-9' data-look='classic' transform='translate(231.078125%2c 267)'%3e%3crect class='basic label-container' style='' x='-114.03125' y='-27' width='228.0625' height='54'/%3e%3cg class='label' style='' transform='translate(-84.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='168.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModel picks correct tool%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-R-13' data-look='classic' transform='translate(753.0390625%2c 267)'%3e%3crect class='basic label-container' style='' x='-106.921875' y='-27' width='213.84375' height='54'/%3e%3cg class='label' style='' transform='translate(-76.921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='153.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModel fills inputs right%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-2-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
A good schema includes:
- A name that tells the model when to reach for this tool.
- A description that is genuinely a description, not a one-word label.
- Input fields with clear types, required/optional flags, and explanations.
- Optional examples of good calls.
A schema that nails these produces dramatically better tool use than a schema that’s been copy-pasted from an OpenAPI spec with no thought. The model is not reading your code; it is reading your description. Write it for a reader.
Behind the schema, the actual tool function can be anything: a database query, an HTTP call, a file read, a shell command, a call to another language model. The harness treats them uniformly; the model doesn’t know or care.
When to give the model tools — and when not to
The temptation, once tools are wired up, is to wire up every tool. Don’t.
%3b%7d%23mermaid-3 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-3 .cluster text%7bfill:%23333%3b%7d%23mermaid-3 .cluster span%7bcolor:%23333%3b%7d%23mermaid-3 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-3 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-3 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-3 .icon-shape%2c%23mermaid-3 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-3 .icon-shape p%2c%23mermaid-3 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-3 .icon-shape .label rect%2c%23mermaid-3 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-3 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-3 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-3-gradient)%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M111.695%2c212L127.855%2c184.5C144.015%2c157%2c176.336%2c102%2c198.071%2c74.5C219.807%2c47%2c230.958%2c47%2c236.534%2c47L242.109%2c47' id='mermaid-3-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MTExLjY5NDU4MDA3ODEyNSwieSI6MjEyfSx7IngiOjIwOC42NTYyNSwieSI6NDd9LHsieCI6MjQ2LjEwOTM3NSwieSI6NDd9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M143.427%2c212L154.299%2c205.833C165.17%2c199.667%2c186.913%2c187.333%2c201.285%2c181.167C215.656%2c175%2c222.656%2c175%2c226.156%2c175L229.656%2c175' id='mermaid-3-L_A_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_C_0' data-points='W3sieCI6MTQzLjQyNzQ5MDIzNDM3NSwieSI6MjEyfSx7IngiOjIwOC42NTYyNSwieSI6MTc1fSx7IngiOjIzMy42NTYyNSwieSI6MTc1fV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M143.427%2c266L154.299%2c272.167C165.17%2c278.333%2c186.913%2c290.667%2c204.397%2c296.833C221.88%2c303%2c235.104%2c303%2c241.716%2c303L248.328%2c303' id='mermaid-3-L_A_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_D_0' data-points='W3sieCI6MTQzLjQyNzQ5MDIzNDM3NSwieSI6MjY2fSx7IngiOjIwOC42NTYyNSwieSI6MzAzfSx7IngiOjI1Mi4zMjgxMjUsInkiOjMwM31d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M111.695%2c266L127.855%2c293.5C144.015%2c321%2c176.336%2c376%2c196.812%2c403.5C217.289%2c431%2c225.922%2c431%2c230.238%2c431L234.555%2c431' id='mermaid-3-L_A_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_E_0' data-points='W3sieCI6MTExLjY5NDU4MDA3ODEyNSwieSI6MjY2fSx7IngiOjIwOC42NTYyNSwieSI6NDMxfSx7IngiOjIzOC41NTQ2ODc1LCJ5Ijo0MzF9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-3-flowchart-A-0' data-look='classic' transform='translate(95.828125%2c 239)'%3e%3crect class='basic label-container' style='' x='-87.828125' y='-27' width='175.65625' height='54'/%3e%3cg class='label' style='' transform='translate(-57.828125%2c -12)'%3e%3crect/%3e%3cforeignObject width='115.65625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEach tool added%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-B-1' data-look='classic' transform='translate(351.2578125%2c 47)'%3e%3crect class='basic label-container' style='' x='-105.1484375' y='-39' width='210.296875' height='78'/%3e%3cg class='label' style='' transform='translate(-75.1484375%2c -24)'%3e%3crect/%3e%3cforeignObject width='150.296875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContext window cost%3cbr /%3eschemas take tokens%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-C-3' data-look='classic' transform='translate(351.2578125%2c 175)'%3e%3crect class='basic label-container' style='' x='-117.6015625' y='-39' width='235.203125' height='78'/%3e%3cg class='label' style='' transform='translate(-87.6015625%2c -24)'%3e%3crect/%3e%3cforeignObject width='175.203125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLatency cost%3cbr /%3emore options to consider%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-D-5' data-look='classic' transform='translate(351.2578125%2c 303)'%3e%3crect class='basic label-container' style='' x='-98.9296875' y='-39' width='197.859375' height='78'/%3e%3cg class='label' style='' transform='translate(-68.9296875%2c -24)'%3e%3crect/%3e%3cforeignObject width='137.859375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eClarity cost%3cbr /%3ewrong tool selected%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-E-7' data-look='classic' transform='translate(351.2578125%2c 431)'%3e%3crect class='basic label-container' style='' x='-112.703125' y='-39' width='225.40625' height='78'/%3e%3cg class='label' style='' transform='translate(-82.703125%2c -24)'%3e%3crect/%3e%3cforeignObject width='165.40625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSafety cost%3cbr /%3emore ways to go wrong%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-3-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Each tool you expose:
- Costs context window (the schemas take tokens).
- Costs latency (the model has to consider more options each turn).
- Costs clarity (the model may pick the wrong tool from a crowded menu).
- Costs safety (more tools, more ways things can go wrong).
A product with three well-chosen tools almost always beats a product with thirty sloppy ones. A useful rule of thumb: expose a tool only if you’ve watched a real user ask for exactly that action more than once. Everything else stays a possibility for later.
When the tool count does grow past what fits comfortably in context, the standard move is deferred loading: the model sees tool names and one-line descriptions, and must call a meta-tool (search_tools) to fetch the full schema of the few it wants to use. This scales to hundreds of tools without drowning the context window.
Tool choice: letting the model decide
Most APIs now let you control how the model chooses a tool. There are three common modes:
%3b%7d%23mermaid-4 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-4 .cluster text%7bfill:%23333%3b%7d%23mermaid-4 .cluster span%7bcolor:%23333%3b%7d%23mermaid-4 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-4 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-4 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-4 .icon-shape%2c%23mermaid-4 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-4 .icon-shape p%2c%23mermaid-4 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-4 .icon-shape .label rect%2c%23mermaid-4 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-4 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-4 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-4 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node rect%2c%23mermaid-4 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-4 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-4-gradient)%3bstroke-width:1px%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-4_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M265.586%2c54.891L239.807%2c60.243C214.029%2c65.594%2c162.471%2c76.297%2c136.693%2c85.149C110.914%2c94%2c110.914%2c101%2c110.914%2c104.5L110.914%2c108' id='mermaid-4-L_TC_AU_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TC_AU_0' data-points='W3sieCI6MjY1LjU4NTkzNzUsInkiOjU0Ljg5MTQ2MzY4MDg3ODI3NX0seyJ4IjoxMTAuOTE0MDYyNSwieSI6ODd9LHsieCI6MTEwLjkxNDA2MjUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M361.406%2c62L361.406%2c66.167C361.406%2c70.333%2c361.406%2c78.667%2c361.406%2c86.333C361.406%2c94%2c361.406%2c101%2c361.406%2c104.5L361.406%2c108' id='mermaid-4-L_TC_RQ_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TC_RQ_0' data-points='W3sieCI6MzYxLjQwNjI1LCJ5Ijo2Mn0seyJ4IjozNjEuNDA2MjUsInkiOjg3fSx7IngiOjM2MS40MDYyNSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M457.227%2c54.11L484.714%2c59.591C512.201%2c65.073%2c567.174%2c76.037%2c594.661%2c85.018C622.148%2c94%2c622.148%2c101%2c622.148%2c104.5L622.148%2c108' id='mermaid-4-L_TC_SP_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_TC_SP_0' data-points='W3sieCI6NDU3LjIyNjU2MjUsInkiOjU0LjEwOTUxMzEwODYxNDI0fSx7IngiOjYyMi4xNDg0Mzc1LCJ5Ijo4N30seyJ4Ijo2MjIuMTQ4NDM3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M110.914%2c190L110.914%2c194.167C110.914%2c198.333%2c110.914%2c206.667%2c110.914%2c214.333C110.914%2c222%2c110.914%2c229%2c110.914%2c232.5L110.914%2c236' id='mermaid-4-L_AU_AU1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_AU_AU1_0' data-points='W3sieCI6MTEwLjkxNDA2MjUsInkiOjE5MH0seyJ4IjoxMTAuOTE0MDYyNSwieSI6MjE1fSx7IngiOjExMC45MTQwNjI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M361.406%2c190L361.406%2c194.167C361.406%2c198.333%2c361.406%2c206.667%2c361.406%2c214.333C361.406%2c222%2c361.406%2c229%2c361.406%2c232.5L361.406%2c236' id='mermaid-4-L_RQ_RQ1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RQ_RQ1_0' data-points='W3sieCI6MzYxLjQwNjI1LCJ5IjoxOTB9LHsieCI6MzYxLjQwNjI1LCJ5IjoyMTV9LHsieCI6MzYxLjQwNjI1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3cpath d='M622.148%2c190L622.148%2c194.167C622.148%2c198.333%2c622.148%2c206.667%2c622.148%2c214.333C622.148%2c222%2c622.148%2c229%2c622.148%2c232.5L622.148%2c236' id='mermaid-4-L_SP_SP1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_SP_SP1_0' data-points='W3sieCI6NjIyLjE0ODQzNzUsInkiOjE5MH0seyJ4Ijo2MjIuMTQ4NDM3NSwieSI6MjE1fSx7IngiOjYyMi4xNDg0Mzc1LCJ5IjoyNDB9XQ==' data-look='classic' marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TC_AU_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TC_RQ_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_TC_SP_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_AU_AU1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_RQ_RQ1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_SP_SP1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-4-flowchart-TC-0' data-look='classic' transform='translate(361.40625%2c 35)'%3e%3crect class='basic label-container' style='' x='-95.8203125' y='-27' width='191.640625' height='54'/%3e%3cg class='label' style='' transform='translate(-65.8203125%2c -12)'%3e%3crect/%3e%3cforeignObject width='131.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool choice setting%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-AU-1' data-look='classic' transform='translate(110.9140625%2c 151)'%3e%3crect class='basic label-container' style='' x='-102.0234375' y='-39' width='204.046875' height='78'/%3e%3cg class='label' style='' transform='translate(-72.0234375%2c -24)'%3e%3crect/%3e%3cforeignObject width='144.046875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAuto%3cbr /%3emodel picks or skips%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-RQ-3' data-look='classic' transform='translate(361.40625%2c 151)'%3e%3crect class='basic label-container' style='' x='-98.46875' y='-39' width='196.9375' height='78'/%3e%3cg class='label' style='' transform='translate(-68.46875%2c -24)'%3e%3crect/%3e%3cforeignObject width='136.9375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRequired%3cbr /%3emust call some tool%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-SP-5' data-look='classic' transform='translate(622.1484375%2c 151)'%3e%3crect class='basic label-container' style='' x='-91.8203125' y='-39' width='183.640625' height='78'/%3e%3cg class='label' style='' transform='translate(-61.8203125%2c -24)'%3e%3crect/%3e%3cforeignObject width='123.640625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSpecific%3cbr /%3eforced to one tool%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-AU1-7' data-look='classic' transform='translate(110.9140625%2c 267)'%3e%3crect class='basic label-container' style='' x='-102.9140625' y='-27' width='205.828125' height='54'/%3e%3cg class='label' style='' transform='translate(-72.9140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='145.828125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUse for most convos%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-RQ1-9' data-look='classic' transform='translate(361.40625%2c 267)'%3e%3crect class='basic label-container' style='' x='-92.6953125' y='-27' width='185.390625' height='54'/%3e%3cg class='label' style='' transform='translate(-62.6953125%2c -12)'%3e%3crect/%3e%3cforeignObject width='125.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUse for extraction%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-4-flowchart-SP1-11' data-look='classic' transform='translate(622.1484375%2c 267)'%3e%3crect class='basic label-container' style='' x='-118.046875' y='-27' width='236.09375' height='54'/%3e%3cg class='label' style='' transform='translate(-88.046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='176.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUse for structured output%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-4-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-4-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
- Auto — the model picks any tool (or none) based on the user’s message. This is the default and what you usually want.
- Required — the model must call some tool. Use this when you’re running a workflow where text-only replies are wrong (e.g., an extraction pipeline).
- Specific — you force the model to call exactly one named tool, passing all the choice back to your code. Useful for structured outputs in disguise.
The common mistake is using “required” when “auto” would do, and getting tool calls on turns where a plain reply would have been fine. Give the model the option to just answer.
Handling errors, gracefully
Tools fail. APIs time out. Inputs are invalid. Permissions get denied. The question is not whether your tools will fail — they will — but how gracefully the model recovers.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-5 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-5 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-5 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-5 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-5 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-5 .sequenceNumber%7bfill:white%3b%7d%23mermaid-5 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-5 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-5 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-5 .labelText%2c%23mermaid-5 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .loopText%2c%23mermaid-5 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-5 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-5 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-5 .noteText%2c%23mermaid-5 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-5 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-5 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-5 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-5 .actor-man circle%2c%23mermaid-5 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-5 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-5 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node rect%2c%23mermaid-5 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-5 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-5-gradient)%3bstroke-width:1px%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-5-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-5-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-5-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-5-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='216' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3etool call with inputs%3c/text%3e%3cline x1='76' y1='109' x2='356' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='M' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='485' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eexecute%3c/text%3e%3cline x1='361' y1='153' x2='609' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='H' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='488' y='168' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eerror response%3c/text%3e%3cline x1='612' y1='197' x2='364' y2='197' class='messageLine1' data-et='message' data-id='i2' data-from='T' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='219' y='212' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eerror as tool result%3c/text%3e%3cline x1='359' y1='241' x2='79' y2='241' class='messageLine0' data-et='message' data-id='i3' data-from='H' data-to='M' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='76' y='256' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ereads error message%3c/text%3e%3cpath d='M 76%2c285 C 136%2c275 136%2c315 76%2c305' class='messageLine0' data-et='message' data-id='i4' data-from='M' data-to='M' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='216' y='330' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3erevised tool call or explanation%3c/text%3e%3cline x1='76' y1='359' x2='356' y2='359' class='messageLine0' data-et='message' data-id='i5' data-from='M' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='485' y='374' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eretry with corrected inputs%3c/text%3e%3cline x1='361' y1='403' x2='609' y2='403' class='messageLine0' data-et='message' data-id='i6' data-from='H' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='488' y='418' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3esuccess%3c/text%3e%3cline x1='612' y1='447' x2='364' y2='447' class='messageLine0' data-et='message' data-id='i7' data-from='T' data-to='H' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3ctext x='219' y='462' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3esuccess result%3c/text%3e%3cline x1='359' y1='491' x2='79' y2='491' class='messageLine0' data-et='message' data-id='i8' data-from='H' data-to='M' stroke-width='2' stroke='none' marker-end='url(%23mermaid-5-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
The trick is to return the error to the model as a tool result, not to crash or swallow it silently. If send_email returns {"error": "recipient not found"}, the model sees that and can respond naturally: “I couldn’t find that recipient — which email address should I use?” It will not do this if the harness swallows the error and returns null.
The same rule applies to validation failures. If the model calls a tool with a missing required field, the cleanest move is to return a structured error describing what’s missing, and let the model try again. Models are remarkably good at fixing their own calls when they can see what went wrong.
One call vs a loop
A single tool call is just a function call with a nicer API. It doesn’t yet make a product “agentic” — it makes it scripted.
%3b%7d%23mermaid-6 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-6 .cluster text%7bfill:%23333%3b%7d%23mermaid-6 .cluster span%7bcolor:%23333%3b%7d%23mermaid-6 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-6 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-6 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-6 .icon-shape%2c%23mermaid-6 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-6 .icon-shape p%2c%23mermaid-6 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-6 .icon-shape .label rect%2c%23mermaid-6 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-6 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-6 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-6 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node rect%2c%23mermaid-6 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-6 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-6-gradient)%3bstroke-width:1px%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-6-Loop' data-look='classic'%3e%3crect style='' x='8' y='8' width='1530.421875' height='219.90625'/%3e%3cg class='cluster-label' transform='translate(686.9375%2c 8)'%3e%3cforeignObject width='172.546875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eChained calls %e2%80%94 agentic%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M173.984%2c125.453L180.234%2c125.453C186.484%2c125.453%2c198.984%2c125.453%2c210.818%2c125.453C222.651%2c125.453%2c233.818%2c125.453%2c239.401%2c125.453L244.984%2c125.453' id='mermaid-6-L_L1_L2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L1_L2_0' data-points='W3sieCI6MTczLjk4NDM3NSwieSI6MTI1LjQ1MzEyNX0seyJ4IjoyMTEuNDg0Mzc1LCJ5IjoxMjUuNDUzMTI1fSx7IngiOjI0OC45ODQzNzUsInkiOjEyNS40NTMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M380.141%2c125.453L386.391%2c125.453C392.641%2c125.453%2c405.141%2c125.453%2c416.974%2c125.453C428.807%2c125.453%2c439.974%2c125.453%2c445.557%2c125.453L451.141%2c125.453' id='mermaid-6-L_L2_L3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L2_L3_0' data-points='W3sieCI6MzgwLjE0MDYyNSwieSI6MTI1LjQ1MzEyNX0seyJ4Ijo0MTcuNjQwNjI1LCJ5IjoxMjUuNDUzMTI1fSx7IngiOjQ1NS4xNDA2MjUsInkiOjEyNS40NTMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M619.188%2c125.453L625.438%2c125.453C631.688%2c125.453%2c644.188%2c125.453%2c656.021%2c125.453C667.854%2c125.453%2c679.021%2c125.453%2c684.604%2c125.453L690.188%2c125.453' id='mermaid-6-L_L3_L4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L3_L4_0' data-points='W3sieCI6NjE5LjE4NzUsInkiOjEyNS40NTMxMjV9LHsieCI6NjU2LjY4NzUsInkiOjEyNS40NTMxMjV9LHsieCI6Njk0LjE4NzUsInkiOjEyNS40NTMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M825.344%2c101.914L831.594%2c99.67C837.844%2c97.427%2c850.344%2c92.94%2c862.177%2c90.697C874.01%2c88.453%2c885.177%2c88.453%2c890.76%2c88.453L896.344%2c88.453' id='mermaid-6-L_L4_L5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L4_L5_0' data-points='W3sieCI6ODI1LjM0Mzc1LCJ5IjoxMDEuOTEzNzg4OTM4MTUzNzF9LHsieCI6ODYyLjg0Mzc1LCJ5Ijo4OC40NTMxMjV9LHsieCI6OTAwLjM0Mzc1LCJ5Ijo4OC40NTMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M1064.391%2c88.453L1070.641%2c88.453C1076.891%2c88.453%2c1089.391%2c88.453%2c1104.112%2c91.544C1118.833%2c94.635%2c1135.775%2c100.816%2c1144.246%2c103.907L1152.717%2c106.998' id='mermaid-6-L_L5_L6_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L5_L6_0' data-points='W3sieCI6MTA2NC4zOTA2MjUsInkiOjg4LjQ1MzEyNX0seyJ4IjoxMTAxLjg5MDYyNSwieSI6ODguNDUzMTI1fSx7IngiOjExNTYuNDc0NjE2ODcxNzU0MywieSI6MTA4LjM2OTEzMzEyODI0NTY1fV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M1156.475%2c142.537L1147.377%2c145.856C1138.28%2c149.176%2c1120.085%2c155.814%2c1091.067%2c159.134C1062.049%2c162.453%2c1022.208%2c162.453%2c982.367%2c162.453C942.526%2c162.453%2c902.685%2c162.453%2c877.142%2c160.435C851.599%2c158.417%2c840.354%2c154.38%2c834.731%2c152.362L829.109%2c150.344' id='mermaid-6-L_L6_L4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L6_L4_0' data-points='W3sieCI6MTE1Ni40NzQ2MTY4NzE3NTQzLCJ5IjoxNDIuNTM3MTE2ODcxNzU0MzR9LHsieCI6MTEwMS44OTA2MjUsInkiOjE2Mi40NTMxMjV9LHsieCI6OTgyLjM2NzE4NzUsInkiOjE2Mi40NTMxMjV9LHsieCI6ODYyLjg0Mzc1LCJ5IjoxNjIuNDUzMTI1fSx7IngiOjgyNS4zNDM3NSwieSI6MTQ4Ljk5MjQ2MTA2MTg0NjI5fV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M1267.203%2c125.453L1275.529%2c125.453C1283.854%2c125.453%2c1300.505%2c125.453%2c1316.49%2c125.453C1332.474%2c125.453%2c1347.792%2c125.453%2c1355.451%2c125.453L1363.109%2c125.453' id='mermaid-6-L_L6_L7_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_L6_L7_0' data-points='W3sieCI6MTI2Ny4yMDMxMjUsInkiOjEyNS40NTMxMjV9LHsieCI6MTMxNy4xNTYyNSwieSI6MTI1LjQ1MzEyNX0seyJ4IjoxMzY3LjEwOTM3NSwieSI6MTI1LjQ1MzEyNX1d' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L1_L2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L2_L3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L3_L4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L4_L5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_L5_L6_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(982.3671875%2c 162.453125)'%3e%3cg class='label' data-id='L_L6_L4_0' transform='translate(-8.8984375%2c -12)'%3e%3cforeignObject width='17.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eno%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(1317.15625%2c 125.453125)'%3e%3cg class='label' data-id='L_L6_L7_0' transform='translate(-12.453125%2c -12)'%3e%3cforeignObject width='24.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eyes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-L1-6' data-look='classic' transform='translate(109.7421875%2c 125.453125)'%3e%3crect class='basic label-container' style='' x='-64.2421875' y='-27' width='128.484375' height='54'/%3e%3cg class='label' style='' transform='translate(-34.2421875%2c -12)'%3e%3crect/%3e%3cforeignObject width='68.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser goal%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L2-7' data-look='classic' transform='translate(314.5625%2c 125.453125)'%3e%3crect class='basic label-container' style='' x='-65.578125' y='-27' width='131.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-35.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='71.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool call 1%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L3-9' data-look='classic' transform='translate(537.1640625%2c 125.453125)'%3e%3crect class='basic label-container' style='' x='-82.0234375' y='-27' width='164.046875' height='54'/%3e%3cg class='label' style='' transform='translate(-52.0234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='104.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eObserve result%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L4-11' data-look='classic' transform='translate(759.765625%2c 125.453125)'%3e%3crect class='basic label-container' style='' x='-65.578125' y='-27' width='131.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-35.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='71.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTool call 2%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L5-13' data-look='classic' transform='translate(982.3671875%2c 88.453125)'%3e%3crect class='basic label-container' style='' x='-82.0234375' y='-27' width='164.046875' height='54'/%3e%3cg class='label' style='' transform='translate(-52.0234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='104.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eObserve result%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L6-15' data-look='classic' transform='translate(1203.296875%2c 125.453125)'%3e%3cpolygon points='63.90625%2c0 127.8125%2c-63.90625 63.90625%2c-127.8125 0%2c-63.90625' class='label-container' transform='translate(-63.40625%2c 63.90625)'/%3e%3cg class='label' style='' transform='translate(-36.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='73.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGoal met%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-L7-19' data-look='classic' transform='translate(1434.015625%2c 125.453125)'%3e%3crect class='basic label-container' style='' x='-66.90625' y='-27' width='133.8125' height='54'/%3e%3cg class='label' style='' transform='translate(-36.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='73.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFinal reply%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1580.421875%2c 47.953125)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-6-Single' data-look='classic'%3e%3crect style='' x='8' y='8' width='806.796875' height='124'/%3e%3cg class='cluster-label' transform='translate(334.4765625%2c 8)'%3e%3cforeignObject width='153.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSingle call %e2%80%94 scripted%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M197.094%2c70L203.344%2c70C209.594%2c70%2c222.094%2c70%2c233.927%2c70C245.76%2c70%2c256.927%2c70%2c262.51%2c70L268.094%2c70' id='mermaid-6-L_S1_S2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S1_S2_0' data-points='W3sieCI6MTk3LjA5Mzc1LCJ5Ijo3MH0seyJ4IjoyMzQuNTkzNzUsInkiOjcwfSx7IngiOjI3Mi4wOTM3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M421.031%2c70L427.281%2c70C433.531%2c70%2c446.031%2c70%2c457.865%2c70C469.698%2c70%2c480.865%2c70%2c486.448%2c70L492.031%2c70' id='mermaid-6-L_S2_S3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_S3_0' data-points='W3sieCI6NDIxLjAzMTI1LCJ5Ijo3MH0seyJ4Ijo0NTguNTMxMjUsInkiOjcwfSx7IngiOjQ5Ni4wMzEyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M601.391%2c70L607.641%2c70C613.891%2c70%2c626.391%2c70%2c638.224%2c70C650.057%2c70%2c661.224%2c70%2c666.807%2c70L672.391%2c70' id='mermaid-6-L_S3_S4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S3_S4_0' data-points='W3sieCI6NjAxLjM5MDYyNSwieSI6NzB9LHsieCI6NjM4Ljg5MDYyNSwieSI6NzB9LHsieCI6Njc2LjM5MDYyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S1_S2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S2_S3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S3_S4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-S1-0' data-look='classic' transform='translate(121.296875%2c 70)'%3e%3crect class='basic label-container' style='' x='-75.796875' y='-27' width='151.59375' height='54'/%3e%3cg class='label' style='' transform='translate(-45.796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='91.59375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser request%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-S2-1' data-look='classic' transform='translate(346.5625%2c 70)'%3e%3crect class='basic label-container' style='' x='-74.46875' y='-27' width='148.9375' height='54'/%3e%3cg class='label' style='' transform='translate(-44.46875%2c -12)'%3e%3crect/%3e%3cforeignObject width='88.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eOne tool call%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-S3-3' data-look='classic' transform='translate(548.7109375%2c 70)'%3e%3crect class='basic label-container' style='' x='-52.6796875' y='-27' width='105.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-22.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='45.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eResult%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-S4-5' data-look='classic' transform='translate(726.84375%2c 70)'%3e%3crect class='basic label-container' style='' x='-50.453125' y='-27' width='100.90625' height='54'/%3e%3cg class='label' style='' transform='translate(-20.453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='40.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReply%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-6-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
The real power comes when the model can chain calls: “first look up the flight, then check the calendar for conflicts, then ask the user, then book it.” That chaining is the next rung, the agent loop, and it’s where this series’ story pivots from augmented chat to genuine autonomy. Post 6 is where we go.
One important design note before we leave tools. Everything in this post has been local: a harness, a model, and a set of tools you hand-wrote. But tools can also come from elsewhere — from an external server that advertises what it offers. That’s the Model Context Protocol (MCP), a growing standard that lets a harness discover and call tools published by other services, without the harness author having to write any code. It’s the same four-step cycle dressed in a network protocol. The existence of MCP is why “tool use” is rapidly becoming less about writing tools and more about connecting to them.
The honest limits
Tools are not a fix for every weakness of the model. Two in particular:
1. Hallucinated tool calls. The model will, occasionally, invent a tool that doesn’t exist or pass invalid arguments. Good harnesses validate before execution. Great harnesses feed the error back and let the model retry. A hallucinated call that gets blocked is a minor annoyance; one that gets executed is a disaster.
2. Overconfident tool use. Given tools, a model will sometimes use them when it shouldn’t — calling search_web for a question it could answer from its own training, for instance. The fix is in the system prompt: give the model explicit guidance on when not to use tools. “If the answer is a basic fact you already know, just answer.”
The broader lesson is that tool use multiplies both the model’s power and its failure modes. Every rung above tool use — agent loops especially — is partly a story of how to keep that multiplication controlled.
Where we go next
Tool use gave the model hands. The next rung gives it the capacity to use those hands more than once, in sequence, with checking along the way. That’s the agent loop: think → act → observe → reflect, until the goal is met or the budget is spent.
Read next: The Agent Loop — ReAct, Plan-Act-Observe.