Your language model has read a large portion of the public internet, most of the books ever written, and an enormous amount of code. It has not read your company’s wiki. It has not read this morning’s support tickets. It has not read the deploy note your teammate wrote at 2 AM explaining why production is on fire.
And it cannot read any of those things without help. Its knowledge is frozen at training time; it has no eyes, no access, no way to open a document you point at. Unless you build the rung we’re climbing in this post.
RAG — retrieval-augmented generation — is the rung where AI products stop making things up about your data and start actually using it. The name is terrible. The idea is simple. It’s one of the few parts of the stack that, once you see the diagram, you cannot unsee.
The one-sentence version
RAG is library lookup: right before the model answers, hand it the most relevant passages from your documents, and ask it to use them.
That’s it. That’s the whole thing.
Everything else in this post is engineering detail about how to build the library, how to find the right passages, and where the whole thing goes wrong in practice.
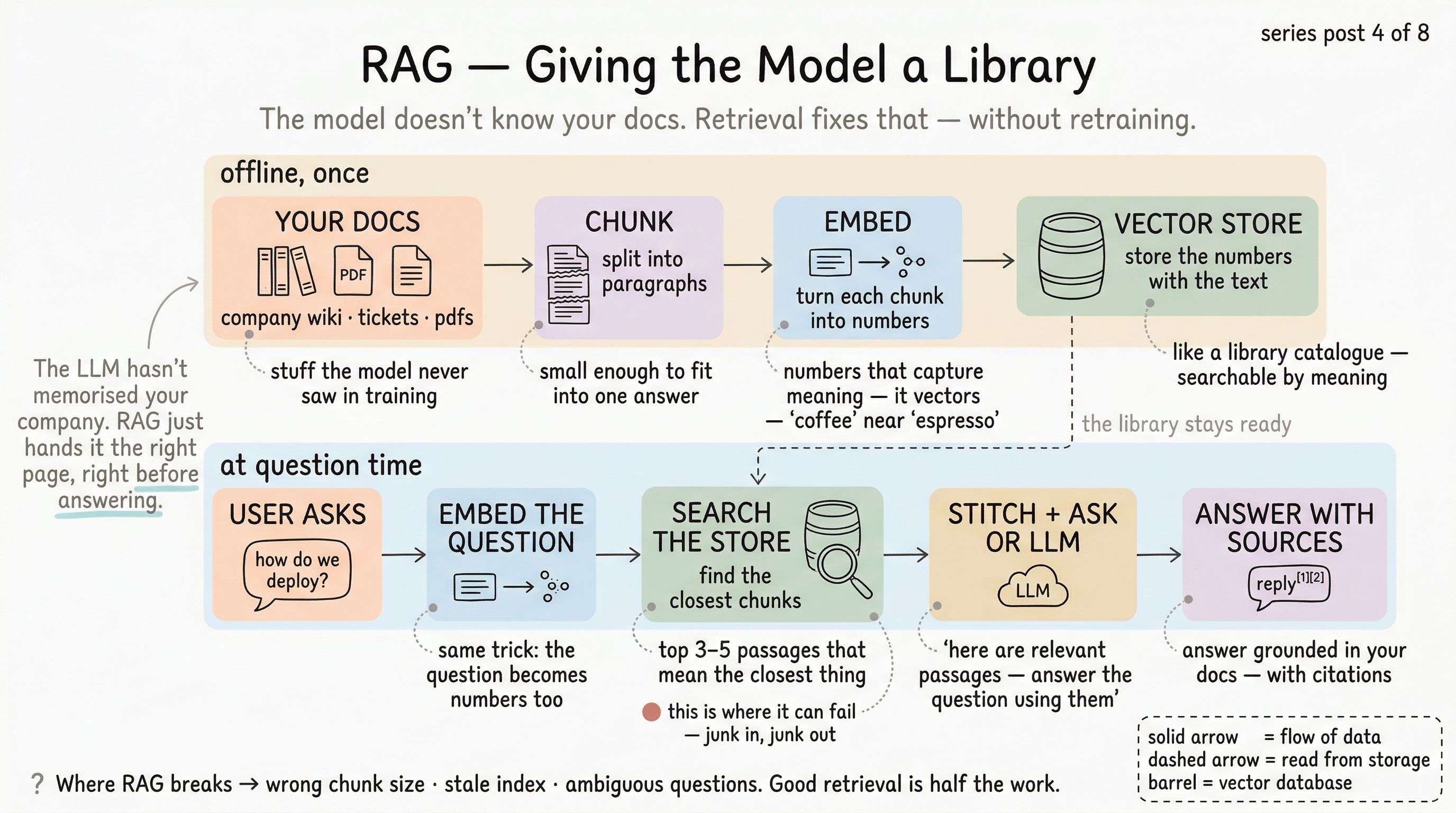
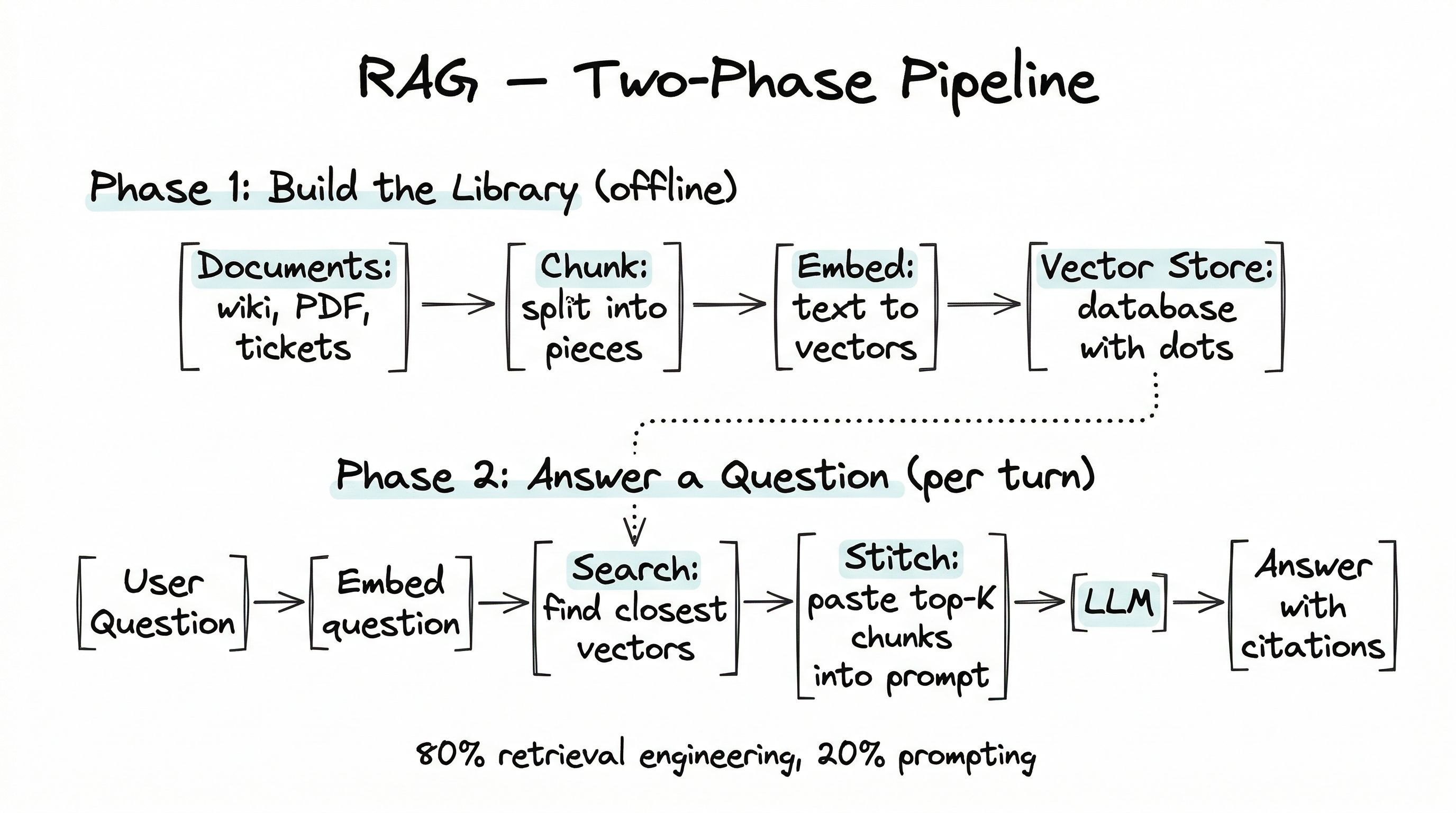
Two phases, one pipeline
RAG is a pipeline with two phases. The first phase runs rarely (when documents change). The second phase runs every time a user asks a question.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-Phase2' data-look='classic'%3e%3crect style='' x='8' y='241' width='282.28125' height='753'/%3e%3cg class='cluster-label' transform='translate(51.3125%2c 241)'%3e%3cforeignObject width='195.65625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePhase 2 %e2%80%94 Answer per turn%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='cluster' id='mermaid-0-Phase1' data-look='classic'%3e%3crect style='' x='310.28125' y='8' width='258.96875' height='441'/%3e%3cg class='cluster-label' transform='translate(356.171875%2c 8)'%3e%3cforeignObject width='167.1875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePhase 1 %e2%80%94 Build library%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M439.766%2c87L439.766%2c91.167C439.766%2c95.333%2c439.766%2c103.667%2c439.766%2c111.333C439.766%2c119%2c439.766%2c126%2c439.766%2c129.5L439.766%2c133' id='mermaid-0-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6NDM5Ljc2NTYyNSwieSI6ODd9LHsieCI6NDM5Ljc2NTYyNSwieSI6MTEyfSx7IngiOjQzOS43NjU2MjUsInkiOjEzN31d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M439.766%2c191L439.766%2c195.167C439.766%2c199.333%2c439.766%2c207.667%2c439.766%2c216C439.766%2c224.333%2c439.766%2c232.667%2c439.766%2c240.333C439.766%2c248%2c439.766%2c255%2c439.766%2c258.5L439.766%2c262' id='mermaid-0-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6NDM5Ljc2NTYyNSwieSI6MTkxfSx7IngiOjQzOS43NjU2MjUsInkiOjIxNn0seyJ4Ijo0MzkuNzY1NjI1LCJ5IjoyNDF9LHsieCI6NDM5Ljc2NTYyNSwieSI6MjY2fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M439.766%2c320L439.766%2c324.167C439.766%2c328.333%2c439.766%2c336.667%2c439.766%2c344.333C439.766%2c352%2c439.766%2c359%2c439.766%2c362.5L439.766%2c366' id='mermaid-0-L_C_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_D_0' data-points='W3sieCI6NDM5Ljc2NTYyNSwieSI6MzIwfSx7IngiOjQzOS43NjU2MjUsInkiOjM0NX0seyJ4Ijo0MzkuNzY1NjI1LCJ5IjozNzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M141.922%2c320L141.922%2c324.167C141.922%2c328.333%2c141.922%2c336.667%2c141.922%2c344.333C141.922%2c352%2c141.922%2c359%2c141.922%2c362.5L141.922%2c366' id='mermaid-0-L_E_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_F_0' data-points='W3sieCI6MTQxLjkyMTg3NSwieSI6MzIwfSx7IngiOjE0MS45MjE4NzUsInkiOjM0NX0seyJ4IjoxNDEuOTIxODc1LCJ5IjozNzB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M141.922%2c424L141.922%2c428.167C141.922%2c432.333%2c141.922%2c440.667%2c141.922%2c449C141.922%2c457.333%2c141.922%2c465.667%2c142.597%2c473.345C143.273%2c481.024%2c144.623%2c488.048%2c145.299%2c491.56L145.974%2c495.072' id='mermaid-0-L_F_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_G_0' data-points='W3sieCI6MTQxLjkyMTg3NSwieSI6NDI0fSx7IngiOjE0MS45MjE4NzUsInkiOjQ0OX0seyJ4IjoxNDEuOTIxODc1LCJ5Ijo0NzR9LHsieCI6MTQ2LjcyOTU2NzMwNzY5MjMyLCJ5Ijo0OTl9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M151.922%2c553L151.922%2c557.167C151.922%2c561.333%2c151.922%2c569.667%2c151.922%2c577.333C151.922%2c585%2c151.922%2c592%2c151.922%2c595.5L151.922%2c599' id='mermaid-0-L_G_H_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_G_H_0' data-points='W3sieCI6MTUxLjkyMTg3NSwieSI6NTUzfSx7IngiOjE1MS45MjE4NzUsInkiOjU3OH0seyJ4IjoxNTEuOTIxODc1LCJ5Ijo2MDN9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M151.922%2c657L151.922%2c661.167C151.922%2c665.333%2c151.922%2c673.667%2c151.922%2c681.333C151.922%2c689%2c151.922%2c696%2c151.922%2c699.5L151.922%2c703' id='mermaid-0-L_H_I_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_H_I_0' data-points='W3sieCI6MTUxLjkyMTg3NSwieSI6NjU3fSx7IngiOjE1MS45MjE4NzUsInkiOjY4Mn0seyJ4IjoxNTEuOTIxODc1LCJ5Ijo3MDd9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M151.922%2c761L151.922%2c765.167C151.922%2c769.333%2c151.922%2c777.667%2c151.922%2c785.333C151.922%2c793%2c151.922%2c800%2c151.922%2c803.5L151.922%2c807' id='mermaid-0-L_I_J_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_J_0' data-points='W3sieCI6MTUxLjkyMTg3NSwieSI6NzYxfSx7IngiOjE1MS45MjE4NzUsInkiOjc4Nn0seyJ4IjoxNTEuOTIxODc1LCJ5Ijo4MTF9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M151.922%2c865L151.922%2c869.167C151.922%2c873.333%2c151.922%2c881.667%2c151.922%2c889.333C151.922%2c897%2c151.922%2c904%2c151.922%2c907.5L151.922%2c911' id='mermaid-0-L_J_K_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_J_K_0' data-points='W3sieCI6MTUxLjkyMTg3NSwieSI6ODY1fSx7IngiOjE1MS45MjE4NzUsInkiOjg5MH0seyJ4IjoxNTEuOTIxODc1LCJ5Ijo5MTV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M439.766%2c424L439.766%2c428.167C439.766%2c432.333%2c439.766%2c440.667%2c401.655%2c449C363.544%2c457.333%2c287.323%2c465.667%2c244.971%2c473.56C202.619%2c481.453%2c194.137%2c488.906%2c189.896%2c492.633L185.655%2c496.36' id='mermaid-0-L_D_G_0' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_G_0' data-points='W3sieCI6NDM5Ljc2NTYyNSwieSI6NDI0fSx7IngiOjQzOS43NjU2MjUsInkiOjQ0OX0seyJ4IjoyMTEuMTAxNTYyNSwieSI6NDc0fSx7IngiOjE4Mi42NDk3ODk2NjM0NjE1NSwieSI6NDk5fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_G_H_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_H_I_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_J_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_J_K_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-A-0' data-look='classic' transform='translate(439.765625%2c 60)'%3e%3crect class='basic label-container' style='' x='-87.359375' y='-27' width='174.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-57.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='114.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRaw documents%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B-1' data-look='classic' transform='translate(439.765625%2c 164)'%3e%3crect class='basic label-container' style='' x='-88.2578125' y='-27' width='176.515625' height='54'/%3e%3cg class='label' style='' transform='translate(-58.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='116.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSplit into chunks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-C-3' data-look='classic' transform='translate(439.765625%2c 293)'%3e%3crect class='basic label-container' style='' x='-94.484375' y='-27' width='188.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-64.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEmbedding model%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-D-5' data-look='classic' transform='translate(439.765625%2c 397)'%3e%3crect class='basic label-container' style='' x='-72.6875' y='-27' width='145.375' height='54'/%3e%3cg class='label' style='' transform='translate(-42.6875%2c -12)'%3e%3crect/%3e%3cforeignObject width='85.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector store%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-E-6' data-look='classic' transform='translate(141.921875%2c 293)'%3e%3crect class='basic label-container' style='' x='-79.359375' y='-27' width='158.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-49.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='98.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUser question%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-F-7' data-look='classic' transform='translate(141.921875%2c 397)'%3e%3crect class='basic label-container' style='' x='-94.484375' y='-27' width='188.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-64.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEmbedding model%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-G-9' data-look='classic' transform='translate(151.921875%2c 526)'%3e%3crect class='basic label-container' style='' x='-99.3671875' y='-27' width='198.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-69.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='138.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSearch vector store%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-H-11' data-look='classic' transform='translate(151.921875%2c 630)'%3e%3crect class='basic label-container' style='' x='-78.46875' y='-27' width='156.9375' height='54'/%3e%3cg class='label' style='' transform='translate(-48.46875%2c -12)'%3e%3crect/%3e%3cforeignObject width='96.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTop-K chunks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-I-13' data-look='classic' transform='translate(151.921875%2c 734)'%3e%3crect class='basic label-container' style='' x='-92.25' y='-27' width='184.5' height='54'/%3e%3cg class='label' style='' transform='translate(-62.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='124.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStitch into prompt%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-J-15' data-look='classic' transform='translate(151.921875%2c 838)'%3e%3crect class='basic label-container' style='' x='-45.5625' y='-27' width='91.125' height='54'/%3e%3cg class='label' style='' transform='translate(-15.5625%2c -12)'%3e%3crect/%3e%3cforeignObject width='31.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLLM%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-K-17' data-look='classic' transform='translate(151.921875%2c 942)'%3e%3crect class='basic label-container' style='' x='-103.359375' y='-27' width='206.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-73.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='146.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAnswer with sources%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Phase 1 — Build the library (runs offline).
docs → chunk → embed → storeYou take your documents — wiki pages, PDFs, tickets, whatever. You split them into chunks small enough to fit comfortably inside a prompt. You convert each chunk into a vector (a list of numbers) using an embedding model. You store the vectors alongside the original text in a database designed for fast similarity search.
Phase 2 — Answer a question (runs per user turn).
question → embed → search → stitch → LLM → answer with sourcesWhen a user asks something, you embed their question the same way you embedded the chunks. You search the store for the top few chunks whose vectors are closest to the question’s vector. You stitch those chunks into a prompt that says, roughly, “Here are some relevant passages. Using them, answer the user’s question.” The model produces the answer, ideally citing the chunks it used.
The whole pipeline has maybe seven moving parts. Each is boring on its own. The magic is the composition.
What an embedding actually is
The most jargon-heavy word in this whole stack is “embedding.” It sounds mathematical and forbidding. It is, in plain English, this:
An embedding is a way of turning a piece of text into a list of numbers, such that texts with similar meanings get similar lists of numbers.
%3b%7d%23mermaid-1 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M152.047%2c35L158.807%2c35C165.568%2c35%2c179.089%2c35%2c200.09%2c47.396C221.092%2c59.791%2c249.574%2c84.583%2c263.815%2c96.978L278.057%2c109.374' id='mermaid-1-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MTUyLjA0Njg3NSwieSI6MzV9LHsieCI6MTkyLjYwOTM3NSwieSI6MzV9LHsieCI6MjgxLjA3Mzc2ODAyODg0NjEzLCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M343.114%2c112L357.858%2c99.167C372.602%2c86.333%2c402.09%2c60.667%2c420.334%2c47.833C438.578%2c35%2c445.578%2c35%2c449.078%2c35L452.578%2c35' id='mermaid-1-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MzQzLjExMzczMTk3MTE1Mzg3LCJ5IjoxMTJ9LHsieCI6NDMxLjU3ODEyNSwieSI6MzV9LHsieCI6NDU2LjU3ODEyNSwieSI6MzV9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M157.367%2c139L163.241%2c139C169.115%2c139%2c180.862%2c139%2c190.236%2c139C199.609%2c139%2c206.609%2c139%2c210.109%2c139L213.609%2c139' id='mermaid-1-L_D_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_B_0' data-points='W3sieCI6MTU3LjM2NzE4NzUsInkiOjEzOX0seyJ4IjoxOTIuNjA5Mzc1LCJ5IjoxMzl9LHsieCI6MjE3LjYwOTM3NSwieSI6MTM5fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M406.578%2c139L410.745%2c139C414.911%2c139%2c423.245%2c139%2c436.466%2c139C449.688%2c139%2c467.797%2c139%2c476.852%2c139L485.906%2c139' id='mermaid-1-L_B_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_E_0' data-points='W3sieCI6NDA2LjU3ODEyNSwieSI6MTM5fSx7IngiOjQzMS41NzgxMjUsInkiOjEzOX0seyJ4Ijo0ODkuOTA2MjUsInkiOjEzOX1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M167.609%2c243L171.776%2c243C175.943%2c243%2c184.276%2c243%2c202.684%2c230.604C221.092%2c218.209%2c249.574%2c193.417%2c263.815%2c181.022L278.057%2c168.626' id='mermaid-1-L_F_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_B_0' data-points='W3sieCI6MTY3LjYwOTM3NSwieSI6MjQzfSx7IngiOjE5Mi42MDkzNzUsInkiOjI0M30seyJ4IjoyODEuMDczNzY4MDI4ODQ2MTMsInkiOjE2Nn1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M343.114%2c166L357.858%2c178.833C372.602%2c191.667%2c402.09%2c217.333%2c422.705%2c230.167C443.32%2c243%2c455.063%2c243%2c460.934%2c243L466.805%2c243' id='mermaid-1-L_B_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_G_0' data-points='W3sieCI6MzQzLjExMzczMTk3MTE1Mzg3LCJ5IjoxNjZ9LHsieCI6NDMxLjU3ODEyNSwieSI6MjQzfSx7IngiOjQ3MC44MDQ2ODc1LCJ5IjoyNDN9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-A-0' data-look='classic' transform='translate(87.8046875%2c 35)'%3e%3crect class='basic label-container' style='' x='-64.2421875' y='-27' width='128.484375' height='54'/%3e%3cg class='label' style='' transform='translate(-34.2421875%2c -12)'%3e%3crect/%3e%3cforeignObject width='68.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eText input%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-B-1' data-look='classic' transform='translate(312.09375%2c 139)'%3e%3crect class='basic label-container' style='' x='-94.484375' y='-27' width='188.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-64.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEmbedding model%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-C-3' data-look='classic' transform='translate(570.1640625%2c 35)'%3e%3crect class='basic label-container' style='' x='-113.5859375' y='-27' width='227.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-83.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='167.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector: near similar text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-D-4' data-look='classic' transform='translate(87.8046875%2c 139)'%3e%3crect class='basic label-container' style='' x='-69.5625' y='-27' width='139.125' height='54'/%3e%3cg class='label' style='' transform='translate(-39.5625%2c -12)'%3e%3crect/%3e%3cforeignObject width='79.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSimilar text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-E-7' data-look='classic' transform='translate(570.1640625%2c 139)'%3e%3crect class='basic label-container' style='' x='-80.2578125' y='-27' width='160.515625' height='54'/%3e%3cg class='label' style='' transform='translate(-50.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='100.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector: near A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-F-8' data-look='classic' transform='translate(87.8046875%2c 243)'%3e%3crect class='basic label-container' style='' x='-79.8046875' y='-27' width='159.609375' height='54'/%3e%3cg class='label' style='' transform='translate(-49.8046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='99.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUnrelated text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-G-11' data-look='classic' transform='translate(570.1640625%2c 243)'%3e%3crect class='basic label-container' style='' x='-99.359375' y='-27' width='198.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-69.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='138.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector: far from A D%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-1-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
“I love dogs” and “I adore puppies” might become two nearly identical vectors. “I love dogs” and “the GDP of France” will be far apart. The embedding model is trained to produce these vectors; you don’t write the math, you call an API.
The vector might have 768 numbers, or 1,536, or a few thousand. It doesn’t matter for your intuition. What matters is that two texts with similar vectors are, almost always, about similar things. And “close in vector space” is something a database can search for very quickly.
Once you internalize this, the rest of RAG becomes mechanical. You’re just building a search engine where the query language is “things that mean the same as this.”
Chunking: the quiet killer
The cleanest way for RAG to fail is bad chunking.
%3b%7d%23mermaid-2 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-2-gradient)%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-2-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M392.148%2c62L392.148%2c66.167C392.148%2c70.333%2c392.148%2c78.667%2c392.148%2c86.333C392.148%2c94%2c392.148%2c101%2c392.148%2c104.5L392.148%2c108' id='mermaid-2-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MzkyLjE0ODQzNzUsInkiOjYyfSx7IngiOjM5Mi4xNDg0Mzc1LCJ5Ijo4N30seyJ4IjozOTIuMTQ4NDM3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M339.958%2c201.856L304.306%2c214.722C268.654%2c227.587%2c197.351%2c253.317%2c161.699%2c269.682C126.047%2c286.047%2c126.047%2c293.047%2c126.047%2c296.547L126.047%2c300.047' id='mermaid-2-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MzM5Ljk1ODA0MDAwNTAxNTk2LCJ5IjoyMDEuODU2NDc3NTA1MDE1OTZ9LHsieCI6MTI2LjA0Njg3NSwieSI6Mjc5LjA0Njg3NX0seyJ4IjoxMjYuMDQ2ODc1LCJ5IjozMDQuMDQ2ODc1fV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M392.148%2c254.047L392.148%2c258.214C392.148%2c262.38%2c392.148%2c270.714%2c392.148%2c278.38C392.148%2c286.047%2c392.148%2c293.047%2c392.148%2c296.547L392.148%2c300.047' id='mermaid-2-L_B_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_D_0' data-points='W3sieCI6MzkyLjE0ODQzNzUsInkiOjI1NC4wNDY4NzV9LHsieCI6MzkyLjE0ODQzNzUsInkiOjI3OS4wNDY4NzV9LHsieCI6MzkyLjE0ODQzNzUsInkiOjMwNC4wNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M444.247%2c201.949L479.62%2c214.798C514.992%2c227.648%2c585.738%2c253.348%2c621.111%2c269.697C656.484%2c286.047%2c656.484%2c293.047%2c656.484%2c296.547L656.484%2c300.047' id='mermaid-2-L_B_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_E_0' data-points='W3sieCI6NDQ0LjI0NjU2MDIwMzMwMTg0LCJ5IjoyMDEuOTQ4NzUyMjk2Njk4Mn0seyJ4Ijo2NTYuNDg0Mzc1LCJ5IjoyNzkuMDQ2ODc1fSx7IngiOjY1Ni40ODQzNzUsInkiOjMwNC4wNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M126.047%2c358.047L126.047%2c362.214C126.047%2c366.38%2c126.047%2c374.714%2c126.047%2c382.38C126.047%2c390.047%2c126.047%2c397.047%2c126.047%2c400.547L126.047%2c404.047' id='mermaid-2-L_C_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_F_0' data-points='W3sieCI6MTI2LjA0Njg3NSwieSI6MzU4LjA0Njg3NX0seyJ4IjoxMjYuMDQ2ODc1LCJ5IjozODMuMDQ2ODc1fSx7IngiOjEyNi4wNDY4NzUsInkiOjQwOC4wNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M392.148%2c358.047L392.148%2c362.214C392.148%2c366.38%2c392.148%2c374.714%2c392.148%2c382.38C392.148%2c390.047%2c392.148%2c397.047%2c392.148%2c400.547L392.148%2c404.047' id='mermaid-2-L_D_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_G_0' data-points='W3sieCI6MzkyLjE0ODQzNzUsInkiOjM1OC4wNDY4NzV9LHsieCI6MzkyLjE0ODQzNzUsInkiOjM4My4wNDY4NzV9LHsieCI6MzkyLjE0ODQzNzUsInkiOjQwOC4wNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M656.484%2c358.047L656.484%2c362.214C656.484%2c366.38%2c656.484%2c374.714%2c656.484%2c382.38C656.484%2c390.047%2c656.484%2c397.047%2c656.484%2c400.547L656.484%2c404.047' id='mermaid-2-L_E_H_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_H_0' data-points='W3sieCI6NjU2LjQ4NDM3NSwieSI6MzU4LjA0Njg3NX0seyJ4Ijo2NTYuNDg0Mzc1LCJ5IjozODMuMDQ2ODc1fSx7IngiOjY1Ni40ODQzNzUsInkiOjQwOC4wNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_H_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-A-0' data-look='classic' transform='translate(392.1484375%2c 35)'%3e%3crect class='basic label-container' style='' x='-66.4609375' y='-27' width='132.921875' height='54'/%3e%3cg class='label' style='' transform='translate(-36.4609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='72.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDocument%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-B-1' data-look='classic' transform='translate(392.1484375%2c 183.0234375)'%3e%3cpolygon points='71.0234375%2c0 142.046875%2c-71.0234375 71.0234375%2c-142.046875 0%2c-71.0234375' class='label-container' transform='translate(-70.5234375%2c 71.0234375)'/%3e%3cg class='label' style='' transform='translate(-44.0234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='88.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eChunk size%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-C-3' data-look='classic' transform='translate(126.046875%2c 331.046875)'%3e%3crect class='basic label-container' style='' x='-55.796875' y='-27' width='111.59375' height='54'/%3e%3cg class='label' style='' transform='translate(-25.796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='51.59375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eToo big%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-D-5' data-look='classic' transform='translate(392.1484375%2c 331.046875)'%3e%3crect class='basic label-container' style='' x='-62.4609375' y='-27' width='124.921875' height='54'/%3e%3cg class='label' style='' transform='translate(-32.4609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='64.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eJust right%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-E-7' data-look='classic' transform='translate(656.484375%2c 331.046875)'%3e%3crect class='basic label-container' style='' x='-63.7890625' y='-27' width='127.578125' height='54'/%3e%3cg class='label' style='' transform='translate(-33.7890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='67.578125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eToo small%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-F-9' data-look='classic' transform='translate(126.046875%2c 447.046875)'%3e%3crect class='basic label-container' style='' x='-118.046875' y='-39' width='236.09375' height='78'/%3e%3cg class='label' style='' transform='translate(-88.046875%2c -24)'%3e%3crect/%3e%3cforeignObject width='176.09375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eImprecise retrieval%3cbr /%3emultiple topics per chunk%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-G-11' data-look='classic' transform='translate(392.1484375%2c 447.046875)'%3e%3crect class='basic label-container' style='' x='-98.0546875' y='-39' width='196.109375' height='78'/%3e%3cg class='label' style='' transform='translate(-68.0546875%2c -24)'%3e%3crect/%3e%3cforeignObject width='136.109375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGood retrieval%3cbr /%3eone idea per chunk%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-H-13' data-look='classic' transform='translate(656.484375%2c 447.046875)'%3e%3crect class='basic label-container' style='' x='-116.28125' y='-39' width='232.5625' height='78'/%3e%3cg class='label' style='' transform='translate(-86.28125%2c -24)'%3e%3crect/%3e%3cforeignObject width='172.5625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNo context%3cbr /%3esentences lose meaning%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-2-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
If your chunks are too big, each one covers multiple topics and the retrieval is imprecise. If your chunks are too small, they lose context — a sentence ripped from its paragraph is often meaningless. If they’re split in the middle of a sentence, or across a page break in a PDF, they become nonsense.
A decent default is chunks of 500–1,000 tokens with a small overlap (say, 50 tokens) between neighbors so that ideas that cross a boundary still have a chance of ending up intact in one chunk. But “decent” is doing heavy lifting there. Good chunking is domain-specific:
- Code should chunk by function, not by line count.
- Legal documents should chunk by clause, not by paragraph.
- Conversational data (tickets, chat logs) should chunk by message or by thread, not by token count.
If your RAG system is giving vaguely-right-but-not-quite-right answers, start here before you blame the model. More products than you’d think are one chunking fix away from working.
Retrieval: top-K and its discontents
When the user asks a question, you embed it and search for the closest vectors in the store. The top K — typically 3 to 10 — are passed to the model. Choosing K is a small decision with real consequences.
%3b%7d%23mermaid-3 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-3 .cluster text%7bfill:%23333%3b%7d%23mermaid-3 .cluster span%7bcolor:%23333%3b%7d%23mermaid-3 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-3 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-3 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-3 .icon-shape%2c%23mermaid-3 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-3 .icon-shape p%2c%23mermaid-3 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-3 .icon-shape .label rect%2c%23mermaid-3 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-3 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-3 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-3-gradient)%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-3-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-3_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M292.523%2c62L292.523%2c66.167C292.523%2c70.333%2c292.523%2c78.667%2c292.523%2c86.333C292.523%2c94%2c292.523%2c101%2c292.523%2c104.5L292.523%2c108' id='mermaid-3-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjYyfSx7IngiOjI5Mi41MjM0Mzc1LCJ5Ijo4N30seyJ4IjoyOTIuNTIzNDM3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M292.523%2c166L292.523%2c170.167C292.523%2c174.333%2c292.523%2c182.667%2c292.523%2c190.333C292.523%2c198%2c292.523%2c205%2c292.523%2c208.5L292.523%2c212' id='mermaid-3-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjE2Nn0seyJ4IjoyOTIuNTIzNDM3NSwieSI6MTkxfSx7IngiOjI5Mi41MjM0Mzc1LCJ5IjoyMTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M292.523%2c270L292.523%2c274.167C292.523%2c278.333%2c292.523%2c286.667%2c292.523%2c294.333C292.523%2c302%2c292.523%2c309%2c292.523%2c312.5L292.523%2c316' id='mermaid-3-L_C_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_D_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjI3MH0seyJ4IjoyOTIuNTIzNDM3NSwieSI6Mjk1fSx7IngiOjI5Mi41MjM0Mzc1LCJ5IjozMjB9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M292.523%2c429.156L292.523%2c433.323C292.523%2c437.49%2c292.523%2c445.823%2c292.523%2c453.49C292.523%2c461.156%2c292.523%2c468.156%2c292.523%2c471.656L292.523%2c475.156' id='mermaid-3-L_D_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_E_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjQyOS4xNTYyNX0seyJ4IjoyOTIuNTIzNDM3NSwieSI6NDU0LjE1NjI1fSx7IngiOjI5Mi41MjM0Mzc1LCJ5Ijo0NzkuMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M334.221%2c387.458L370.209%2c398.575C406.197%2c409.691%2c478.173%2c431.924%2c514.161%2c446.54C550.148%2c461.156%2c550.148%2c468.156%2c550.148%2c471.656L550.148%2c475.156' id='mermaid-3-L_D_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_F_0' data-points='W3sieCI6MzM0LjIyMTQxODM2Mjc5NiwieSI6Mzg3LjQ1ODI2OTEzNzIwNH0seyJ4Ijo1NTAuMTQ4NDM3NSwieSI6NDU0LjE1NjI1fSx7IngiOjU1MC4xNDg0Mzc1LCJ5Ijo0NzkuMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M252.782%2c389.414L223.878%2c400.205C194.974%2c410.995%2c137.167%2c432.576%2c108.263%2c454.033C79.359%2c475.49%2c79.359%2c496.823%2c79.359%2c518.156C79.359%2c539.49%2c79.359%2c560.823%2c79.359%2c574.99C79.359%2c589.156%2c79.359%2c596.156%2c79.359%2c599.656L79.359%2c603.156' id='mermaid-3-L_D_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_G_0' data-points='W3sieCI6MjUyLjc4MTY2MDEwODgxNzQ4LCJ5IjozODkuNDE0NDcyNjA4ODE3NX0seyJ4Ijo3OS4zNTkzNzUsInkiOjQ1NC4xNTYyNX0seyJ4Ijo3OS4zNTkzNzUsInkiOjUxOC4xNTYyNX0seyJ4Ijo3OS4zNTkzNzUsInkiOjU4Mi4xNTYyNX0seyJ4Ijo3OS4zNTkzNzUsInkiOjYwNy4xNTYyNX1d' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M292.523%2c557.156L292.523%2c561.323C292.523%2c565.49%2c292.523%2c573.823%2c292.523%2c583.49C292.523%2c593.156%2c292.523%2c604.156%2c292.523%2c609.656L292.523%2c615.156' id='mermaid-3-L_E_H_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_H_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjU1Ny4xNTYyNX0seyJ4IjoyOTIuNTIzNDM3NSwieSI6NTgyLjE1NjI1fSx7IngiOjI5Mi41MjM0Mzc1LCJ5Ijo2MTkuMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M550.148%2c557.156L550.148%2c561.323C550.148%2c565.49%2c550.148%2c573.823%2c550.148%2c583.49C550.148%2c593.156%2c550.148%2c604.156%2c550.148%2c609.656L550.148%2c615.156' id='mermaid-3-L_F_I_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_I_0' data-points='W3sieCI6NTUwLjE0ODQzNzUsInkiOjU1Ny4xNTYyNX0seyJ4Ijo1NTAuMTQ4NDM3NSwieSI6NTgyLjE1NjI1fSx7IngiOjU1MC4xNDg0Mzc1LCJ5Ijo2MTkuMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M79.359%2c685.156L79.359%2c689.323C79.359%2c693.49%2c79.359%2c701.823%2c101.828%2c711.471C124.296%2c721.118%2c169.232%2c732.08%2c191.7%2c737.561L214.169%2c743.042' id='mermaid-3-L_G_J_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_G_J_0' data-points='W3sieCI6NzkuMzU5Mzc1LCJ5Ijo2ODUuMTU2MjV9LHsieCI6NzkuMzU5Mzc1LCJ5Ijo3MTAuMTU2MjV9LHsieCI6MjE4LjA1NDY4NzUsInkiOjc0My45OTAwNzgxMTA2ODM1fV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M292.523%2c673.156L292.523%2c679.323C292.523%2c685.49%2c292.523%2c697.823%2c292.523%2c707.49C292.523%2c717.156%2c292.523%2c724.156%2c292.523%2c727.656L292.523%2c731.156' id='mermaid-3-L_H_J_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_H_J_0' data-points='W3sieCI6MjkyLjUyMzQzNzUsInkiOjY3My4xNTYyNX0seyJ4IjoyOTIuNTIzNDM3NSwieSI6NzEwLjE1NjI1fSx7IngiOjI5Mi41MjM0Mzc1LCJ5Ijo3MzUuMTU2MjV9XQ==' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3cpath d='M550.148%2c673.156L550.148%2c679.323C550.148%2c685.49%2c550.148%2c697.823%2c520.276%2c710.019C490.403%2c722.215%2c430.658%2c734.275%2c400.786%2c740.304L370.913%2c746.334' id='mermaid-3-L_I_J_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_I_J_0' data-points='W3sieCI6NTUwLjE0ODQzNzUsInkiOjY3My4xNTYyNX0seyJ4Ijo1NTAuMTQ4NDM3NSwieSI6NzEwLjE1NjI1fSx7IngiOjM2Ni45OTIxODc1LCJ5Ijo3NDcuMTI1MTk3MTEzMDUyfV0=' data-look='classic' marker-end='url(%23mermaid-3_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_H_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_I_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_G_J_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_H_J_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_I_J_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-3-flowchart-A-0' data-look='classic' transform='translate(292.5234375%2c 35)'%3e%3crect class='basic label-container' style='' x='-90.9296875' y='-27' width='181.859375' height='54'/%3e%3cg class='label' style='' transform='translate(-60.9296875%2c -12)'%3e%3crect/%3e%3cforeignObject width='121.859375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEmbedded query%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-B-1' data-look='classic' transform='translate(292.5234375%2c 139)'%3e%3crect class='basic label-container' style='' x='-78.9140625' y='-27' width='157.828125' height='54'/%3e%3cg class='label' style='' transform='translate(-48.9140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='97.828125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector search%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-C-3' data-look='classic' transform='translate(292.5234375%2c 243)'%3e%3crect class='basic label-container' style='' x='-76.6875' y='-27' width='153.375' height='54'/%3e%3cg class='label' style='' transform='translate(-46.6875%2c -12)'%3e%3crect/%3e%3cforeignObject width='93.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTop-K results%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-D-5' data-look='classic' transform='translate(292.5234375%2c 374.578125)'%3e%3cpolygon points='54.578125%2c0 109.15625%2c-54.578125 54.578125%2c-109.15625 0%2c-54.578125' class='label-container' transform='translate(-54.078125%2c 54.578125)'/%3e%3cg class='label' style='' transform='translate(-27.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='55.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRefine%3f%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-E-7' data-look='classic' transform='translate(292.5234375%2c 518.15625)'%3e%3crect class='basic label-container' style='' x='-90.6953125' y='-39' width='181.390625' height='78'/%3e%3cg class='label' style='' transform='translate(-60.6953125%2c -24)'%3e%3crect/%3e%3cforeignObject width='121.390625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eHybrid search%3cbr /%3evector %2b keyword%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-F-9' data-look='classic' transform='translate(550.1484375%2c 518.15625)'%3e%3crect class='basic label-container' style='' x='-105.59375' y='-39' width='211.1875' height='78'/%3e%3cg class='label' style='' transform='translate(-75.59375%2c -24)'%3e%3crect/%3e%3cforeignObject width='151.1875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRe-ranking%3cbr /%3esecond model scores%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-G-11' data-look='classic' transform='translate(79.359375%2c 646.15625)'%3e%3crect class='basic label-container' style='' x='-71.359375' y='-39' width='142.71875' height='78'/%3e%3cg class='label' style='' transform='translate(-41.359375%2c -24)'%3e%3crect/%3e%3cforeignObject width='82.71875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBasic top-K%3cbr /%3efastest path%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-H-13' data-look='classic' transform='translate(292.5234375%2c 646.15625)'%3e%3crect class='basic label-container' style='' x='-91.8046875' y='-27' width='183.609375' height='54'/%3e%3cg class='label' style='' transform='translate(-61.8046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='123.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMerged result set%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-I-15' data-look='classic' transform='translate(550.1484375%2c 646.15625)'%3e%3crect class='basic label-container' style='' x='-115.8203125' y='-27' width='231.640625' height='54'/%3e%3cg class='label' style='' transform='translate(-85.8203125%2c -12)'%3e%3crect/%3e%3cforeignObject width='171.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePrecision-ranked subset%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-3-flowchart-J-17' data-look='classic' transform='translate(292.5234375%2c 762.15625)'%3e%3crect class='basic label-container' style='' x='-74.46875' y='-27' width='148.9375' height='54'/%3e%3cg class='label' style='' transform='translate(-44.46875%2c -12)'%3e%3crect/%3e%3cforeignObject width='88.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePass to LLM%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-3-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-3-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Too low (K=1), and one bad match wrecks the answer. Too high (K=20), and you burn context window on irrelevant passages that dilute the model’s attention. Five is a good starting point. Measure.
Two refinements are worth knowing:
Hybrid search. Pure vector search is great at semantic matches (“dogs” matches “puppies”) but bad at exact matches (“SKU-12345” matches “SKU-12345”). Real systems often combine vector search with plain keyword search (the boring old kind) and merge the results. The gains are substantial.
Re-ranking. Pull a larger initial set (say, 20 candidates), then use a second, more expensive model to score each candidate’s relevance to the question, and keep the top 3–5. Slower, much more precise. Worth it when answer quality matters.
Neither of these is mysterious. They’re engineering knobs. The model is not involved in any of this — retrieval is a classical search problem, dressed in new clothes.
The prompt, stitched
Once you have your top chunks, you assemble a prompt.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-4 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-4 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-4 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-4 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-4 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-4 .sequenceNumber%7bfill:white%3b%7d%23mermaid-4 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-4 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-4 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-4 .labelText%2c%23mermaid-4 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .loopText%2c%23mermaid-4 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-4 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-4 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-4 .noteText%2c%23mermaid-4 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-4 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-4 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-4 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-4 .actor-man circle%2c%23mermaid-4 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-4 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-4 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node rect%2c%23mermaid-4 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-4 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-4-gradient)%3bstroke-width:1px%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-4-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-4-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-4-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-4-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-4-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='191' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3echunk 1 with source ref%3c/text%3e%3cline x1='76' y1='109' x2='306' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='R' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='191' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3echunk 2 with source ref%3c/text%3e%3cline x1='76' y1='153' x2='306' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='R' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='191' y='168' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3echunk 3 with source ref%3c/text%3e%3cline x1='76' y1='197' x2='306' y2='197' class='messageLine0' data-et='message' data-id='i2' data-from='R' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='311' y='212' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3estitch chunks into passage block%3c/text%3e%3cpath d='M 311%2c241 C 371%2c231 371%2c271 311%2c261' class='messageLine0' data-et='message' data-id='i3' data-from='T' data-to='T' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='452' y='286' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3esystem %2b passages %2b question%3c/text%3e%3cline x1='311' y1='315' x2='592' y2='315' class='messageLine0' data-et='message' data-id='i4' data-from='T' data-to='L' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3ctext x='736' y='330' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eanswer with passage citations%3c/text%3e%3cline x1='597' y1='359' x2='875' y2='359' class='messageLine0' data-et='message' data-id='i5' data-from='L' data-to='U' stroke-width='2' stroke='none' marker-end='url(%23mermaid-4-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
A reasonable template looks like this:
You have access to the following relevant passages from the user's documents:
<passage id="1" source="handbook.md">{chunk 1 text}</passage>
<passage id="2" source="deploy-runbook.md">{chunk 2 text}</passage>
...
Use these passages to answer the user's question. If the passages donot contain the answer, say so rather than guessing. Cite passages by id.
Question: {user's question}This is where the magic happens — not because the template is special, but because the model now has the answer in its context window and is being told to use it. A strong RAG system will quote from the passages almost verbatim on factual questions, which is exactly what you want. A weak one will still hallucinate despite having the passages right there, which is almost always a sign that the model isn’t being given enough explicit instruction to prefer the retrieved text over its own knowledge.
Failure modes, honest
RAG is powerful and regularly disappoints. The most common failure modes, roughly in order of frequency:
%3b%7d%23mermaid-5 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-5 .cluster text%7bfill:%23333%3b%7d%23mermaid-5 .cluster span%7bcolor:%23333%3b%7d%23mermaid-5 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-5 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-5 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-5 .icon-shape%2c%23mermaid-5 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-5 .icon-shape p%2c%23mermaid-5 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-5 .icon-shape .label rect%2c%23mermaid-5 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-5 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-5 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-5 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node rect%2c%23mermaid-5 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-5 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-5-gradient)%3bstroke-width:1px%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-5-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-5 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-5_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M558.094%2c44.514L485.467%2c51.595C412.841%2c58.676%2c267.589%2c72.838%2c194.962%2c83.419C122.336%2c94%2c122.336%2c101%2c122.336%2c104.5L122.336%2c108' id='mermaid-5-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6NTU4LjA5Mzc1LCJ5Ijo0NC41MTQ0NDMwNzcyODM2NDR9LHsieCI6MTIyLjMzNTkzNzUsInkiOjg3fSx7IngiOjEyMi4zMzU5Mzc1LCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M558.094%2c54.232L530.383%2c59.694C502.672%2c65.155%2c447.25%2c76.077%2c419.539%2c85.039C391.828%2c94%2c391.828%2c101%2c391.828%2c104.5L391.828%2c108' id='mermaid-5-L_A_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_C_0' data-points='W3sieCI6NTU4LjA5Mzc1LCJ5Ijo1NC4yMzIyODYxNDU3Mzc3Mn0seyJ4IjozOTEuODI4MTI1LCJ5Ijo4N30seyJ4IjozOTEuODI4MTI1LCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M655.68%2c62L655.68%2c66.167C655.68%2c70.333%2c655.68%2c78.667%2c655.68%2c86.333C655.68%2c94%2c655.68%2c101%2c655.68%2c104.5L655.68%2c108' id='mermaid-5-L_A_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_D_0' data-points='W3sieCI6NjU1LjY3OTY4NzUsInkiOjYyfSx7IngiOjY1NS42Nzk2ODc1LCJ5Ijo4N30seyJ4Ijo2NTUuNjc5Njg3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M753.266%2c54.834L779.642%2c60.195C806.018%2c65.556%2c858.771%2c76.278%2c885.147%2c85.139C911.523%2c94%2c911.523%2c101%2c911.523%2c104.5L911.523%2c108' id='mermaid-5-L_A_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_E_0' data-points='W3sieCI6NzUzLjI2NTYyNSwieSI6NTQuODM0MjQ5NDE5ODExOX0seyJ4Ijo5MTEuNTIzNDM3NSwieSI6ODd9LHsieCI6OTExLjUyMzQzNzUsInkiOjExMn1d' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M753.266%2c44.831L823.026%2c51.86C892.786%2c58.888%2c1032.307%2c72.944%2c1102.068%2c83.472C1171.828%2c94%2c1171.828%2c101%2c1171.828%2c104.5L1171.828%2c108' id='mermaid-5-L_A_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_F_0' data-points='W3sieCI6NzUzLjI2NTYyNSwieSI6NDQuODMxNDEzNTY1MDE3MzN9LHsieCI6MTE3MS44MjgxMjUsInkiOjg3fSx7IngiOjExNzEuODI4MTI1LCJ5IjoxMTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M122.336%2c166L122.336%2c170.167C122.336%2c174.333%2c122.336%2c182.667%2c122.336%2c190.333C122.336%2c198%2c122.336%2c205%2c122.336%2c208.5L122.336%2c212' id='mermaid-5-L_B_B1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_B1_0' data-points='W3sieCI6MTIyLjMzNTkzNzUsInkiOjE2Nn0seyJ4IjoxMjIuMzM1OTM3NSwieSI6MTkxfSx7IngiOjEyMi4zMzU5Mzc1LCJ5IjoyMTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M391.828%2c166L391.828%2c170.167C391.828%2c174.333%2c391.828%2c182.667%2c391.828%2c192.333C391.828%2c202%2c391.828%2c213%2c391.828%2c218.5L391.828%2c224' id='mermaid-5-L_C_C1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_C1_0' data-points='W3sieCI6MzkxLjgyODEyNSwieSI6MTY2fSx7IngiOjM5MS44MjgxMjUsInkiOjE5MX0seyJ4IjozOTEuODI4MTI1LCJ5IjoyMjh9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M655.68%2c166L655.68%2c170.167C655.68%2c174.333%2c655.68%2c182.667%2c655.68%2c192.333C655.68%2c202%2c655.68%2c213%2c655.68%2c218.5L655.68%2c224' id='mermaid-5-L_D_D1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_D1_0' data-points='W3sieCI6NjU1LjY3OTY4NzUsInkiOjE2Nn0seyJ4Ijo2NTUuNjc5Njg3NSwieSI6MTkxfSx7IngiOjY1NS42Nzk2ODc1LCJ5IjoyMjh9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M911.523%2c166L911.523%2c170.167C911.523%2c174.333%2c911.523%2c182.667%2c911.523%2c192.333C911.523%2c202%2c911.523%2c213%2c911.523%2c218.5L911.523%2c224' id='mermaid-5-L_E_E1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_E1_0' data-points='W3sieCI6OTExLjUyMzQzNzUsInkiOjE2Nn0seyJ4Ijo5MTEuNTIzNDM3NSwieSI6MTkxfSx7IngiOjkxMS41MjM0Mzc1LCJ5IjoyMjh9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3cpath d='M1171.828%2c166L1171.828%2c170.167C1171.828%2c174.333%2c1171.828%2c182.667%2c1171.828%2c192.333C1171.828%2c202%2c1171.828%2c213%2c1171.828%2c218.5L1171.828%2c224' id='mermaid-5-L_F_F1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_F1_0' data-points='W3sieCI6MTE3MS44MjgxMjUsInkiOjE2Nn0seyJ4IjoxMTcxLjgyODEyNSwieSI6MTkxfSx7IngiOjExNzEuODI4MTI1LCJ5IjoyMjh9XQ==' data-look='classic' marker-end='url(%23mermaid-5_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_B1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_C1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_D1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_E1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_F1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-5-flowchart-A-0' data-look='classic' transform='translate(655.6796875%2c 35)'%3e%3crect class='basic label-container' style='' x='-97.5859375' y='-27' width='195.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-67.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='135.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRAG failure modes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-B-1' data-look='classic' transform='translate(122.3359375%2c 139)'%3e%3crect class='basic label-container' style='' x='-114.3359375' y='-27' width='228.671875' height='54'/%3e%3cg class='label' style='' transform='translate(-84.3359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='168.671875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWrong chunks retrieved%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-C-3' data-look='classic' transform='translate(391.828125%2c 139)'%3e%3crect class='basic label-container' style='' x='-105.15625' y='-27' width='210.3125' height='54'/%3e%3cg class='label' style='' transform='translate(-75.15625%2c -12)'%3e%3crect/%3e%3cforeignObject width='150.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRight chunks ignored%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-D-5' data-look='classic' transform='translate(655.6796875%2c 139)'%3e%3crect class='basic label-container' style='' x='-69.5859375' y='-27' width='139.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-39.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='79.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStale index%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-E-7' data-look='classic' transform='translate(911.5234375%2c 139)'%3e%3crect class='basic label-container' style='' x='-102.4921875' y='-27' width='204.984375' height='54'/%3e%3cg class='label' style='' transform='translate(-72.4921875%2c -12)'%3e%3crect/%3e%3cforeignObject width='144.984375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAmbiguous question%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-F-9' data-look='classic' transform='translate(1171.828125%2c 139)'%3e%3crect class='basic label-container' style='' x='-107.8125' y='-27' width='215.625' height='54'/%3e%3cg class='label' style='' transform='translate(-77.8125%2c -12)'%3e%3crect/%3e%3cforeignObject width='155.625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eContradictory sources%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-B1-11' data-look='classic' transform='translate(122.3359375%2c 267)'%3e%3crect class='basic label-container' style='' x='-99.8125' y='-51' width='199.625' height='102'/%3e%3cg class='label' style='' transform='translate(-69.8125%2c -36)'%3e%3crect/%3e%3cforeignObject width='139.625' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFix: better chunking%3cbr /%3ehybrid search%3cbr /%3ere-ranking%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-C1-13' data-look='classic' transform='translate(391.828125%2c 267)'%3e%3crect class='basic label-container' style='' x='-99.359375' y='-39' width='198.71875' height='78'/%3e%3cg class='label' style='' transform='translate(-69.359375%2c -24)'%3e%3crect/%3e%3cforeignObject width='138.71875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFix: sharper prompt%3cbr /%3estronger model%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-D1-15' data-look='classic' transform='translate(655.6796875%2c 267)'%3e%3crect class='basic label-container' style='' x='-114.4921875' y='-39' width='228.984375' height='78'/%3e%3cg class='label' style='' transform='translate(-84.4921875%2c -24)'%3e%3crect/%3e%3cforeignObject width='168.984375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFix: rebuild on schedule%3cbr /%3eor on doc change%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-E1-17' data-look='classic' transform='translate(911.5234375%2c 267)'%3e%3crect class='basic label-container' style='' x='-91.3515625' y='-39' width='182.703125' height='78'/%3e%3cg class='label' style='' transform='translate(-61.3515625%2c -24)'%3e%3crect/%3e%3cforeignObject width='122.703125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFix: ask clarifying%3cbr /%3eor surface top-K%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-5-flowchart-F1-19' data-look='classic' transform='translate(1171.828125%2c 267)'%3e%3crect class='basic label-container' style='' x='-112.703125' y='-39' width='225.40625' height='78'/%3e%3cg class='label' style='' transform='translate(-82.703125%2c -24)'%3e%3crect/%3e%3cforeignObject width='165.40625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFix: curate source docs%3cbr /%3eone source of truth%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-5-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-5-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
1. Wrong chunks retrieved. The user’s question looks semantically close to a chunk about a different topic. The model answers confidently using the wrong source. Fix: better chunking, hybrid search, re-ranking.
2. Right chunks retrieved, ignored by the model. The passages contain the answer, but the model leans on its prior training instead. Fix: sharper prompt (“if the passages contradict your prior knowledge, trust the passages”), or use a stronger model.
3. Stale index. Documents have changed since the embeddings were built. Fix: rebuild on a schedule, or on document change.
4. Ambiguous questions. The user asks something so vague that no chunk is clearly best. Fix: make the product ask a clarifying question first, or return the top-K as suggestions rather than an answer.
5. Contradictory sources. The documents themselves disagree (version A says one thing, version B says another). The model averages them and confuses everyone. Fix: curate the source documents; RAG is not a substitute for a single source of truth.
Notice that four of the five failure modes are about the retrieval step, not the model. Good RAG is 80% retrieval engineering, 20% prompting.
RAG vs fine-tuning
Every time RAG comes up, someone asks: “Why not just fine-tune the model on our data?” Here’s the honest comparison.
%3b%7d%23mermaid-6 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-6 .cluster text%7bfill:%23333%3b%7d%23mermaid-6 .cluster span%7bcolor:%23333%3b%7d%23mermaid-6 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-6 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-6 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-6 .icon-shape%2c%23mermaid-6 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-6 .icon-shape p%2c%23mermaid-6 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-6 .icon-shape .label rect%2c%23mermaid-6 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-6 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-6 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-6 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node rect%2c%23mermaid-6 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-6 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-6-gradient)%3bstroke-width:1px%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-6-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-6 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-6_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-6-FT' data-look='classic'%3e%3crect style='' x='8' y='8' width='1376.140625' height='124'/%3e%3cg class='cluster-label' transform='translate(638.25%2c 8)'%3e%3cforeignObject width='115.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFine-tuning path%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M229.469%2c70L235.719%2c70C241.969%2c70%2c254.469%2c70%2c266.302%2c70C278.135%2c70%2c289.302%2c70%2c294.885%2c70L300.469%2c70' id='mermaid-6-L_F1_F2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F1_F2_0' data-points='W3sieCI6MjI5LjQ2ODc1LCJ5Ijo3MH0seyJ4IjoyNjYuOTY4NzUsInkiOjcwfSx7IngiOjMwNC40Njg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M522.781%2c70L529.031%2c70C535.281%2c70%2c547.781%2c70%2c559.615%2c70C571.448%2c70%2c582.615%2c70%2c588.198%2c70L593.781%2c70' id='mermaid-6-L_F2_F3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F2_F3_0' data-points='W3sieCI6NTIyLjc4MTI1LCJ5Ijo3MH0seyJ4Ijo1NjAuMjgxMjUsInkiOjcwfSx7IngiOjU5Ny43ODEyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M796.516%2c70L802.766%2c70C809.016%2c70%2c821.516%2c70%2c833.349%2c70C845.182%2c70%2c856.349%2c70%2c861.932%2c70L867.516%2c70' id='mermaid-6-L_F3_F4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F3_F4_0' data-points='W3sieCI6Nzk2LjUxNTYyNSwieSI6NzB9LHsieCI6ODM0LjAxNTYyNSwieSI6NzB9LHsieCI6ODcxLjUxNTYyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M1100.469%2c70L1106.719%2c70C1112.969%2c70%2c1125.469%2c70%2c1137.302%2c70C1149.135%2c70%2c1160.302%2c70%2c1165.885%2c70L1171.469%2c70' id='mermaid-6-L_F4_F5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F4_F5_0' data-points='W3sieCI6MTEwMC40Njg3NSwieSI6NzB9LHsieCI6MTEzNy45Njg3NSwieSI6NzB9LHsieCI6MTE3NS40Njg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F1_F2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F2_F3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F3_F4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F4_F5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-F1-8' data-look='classic' transform='translate(137.484375%2c 70)'%3e%3crect class='basic label-container' style='' x='-91.984375' y='-27' width='183.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-61.984375%2c -12)'%3e%3crect/%3e%3cforeignObject width='123.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eYour labeled data%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-F2-9' data-look='classic' transform='translate(413.625%2c 70)'%3e%3crect class='basic label-container' style='' x='-109.15625' y='-27' width='218.3125' height='54'/%3e%3cg class='label' style='' transform='translate(-79.15625%2c -12)'%3e%3crect/%3e%3cforeignObject width='158.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eExpensive training run%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-F3-11' data-look='classic' transform='translate(697.1484375%2c 70)'%3e%3crect class='basic label-container' style='' x='-99.3671875' y='-27' width='198.734375' height='54'/%3e%3cg class='label' style='' transform='translate(-69.3671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='138.734375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNew model weights%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-F4-13' data-look='classic' transform='translate(985.9921875%2c 70)'%3e%3crect class='basic label-container' style='' x='-114.4765625' y='-27' width='228.953125' height='54'/%3e%3cg class='label' style='' transform='translate(-84.4765625%2c -12)'%3e%3crect/%3e%3cforeignObject width='168.953125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBaked-in style or format%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-F5-15' data-look='classic' transform='translate(1261.0546875%2c 70)'%3e%3crect class='basic label-container' style='' x='-85.5859375' y='-27' width='171.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-55.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='111.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUpdate: re-train%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1426.140625%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-6-RAG' data-look='classic'%3e%3crect style='' x='8' y='8' width='1403.6875' height='124'/%3e%3cg class='cluster-label' transform='translate(674.7109375%2c 8)'%3e%3cforeignObject width='70.265625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRAG path%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M220.547%2c70L226.797%2c70C233.047%2c70%2c245.547%2c70%2c257.38%2c70C269.214%2c70%2c280.38%2c70%2c285.964%2c70L291.547%2c70' id='mermaid-6-L_R1_R2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R1_R2_0' data-points='W3sieCI6MjIwLjU0Njg3NSwieSI6NzB9LHsieCI6MjU4LjA0Njg3NSwieSI6NzB9LHsieCI6Mjk1LjU0Njg3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M484.5%2c70L490.75%2c70C497%2c70%2c509.5%2c70%2c521.333%2c70C533.167%2c70%2c544.333%2c70%2c549.917%2c70L555.5%2c70' id='mermaid-6-L_R2_R3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R2_R3_0' data-points='W3sieCI6NDg0LjUsInkiOjcwfSx7IngiOjUyMiwieSI6NzB9LHsieCI6NTU5LjUsInkiOjcwfV0=' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M767.125%2c70L773.375%2c70C779.625%2c70%2c792.125%2c70%2c803.958%2c70C815.792%2c70%2c826.958%2c70%2c832.542%2c70L838.125%2c70' id='mermaid-6-L_R3_R4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R3_R4_0' data-points='W3sieCI6NzY3LjEyNSwieSI6NzB9LHsieCI6ODA0LjYyNSwieSI6NzB9LHsieCI6ODQyLjEyNSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3cpath d='M1087.094%2c70L1093.344%2c70C1099.594%2c70%2c1112.094%2c70%2c1123.927%2c70C1135.76%2c70%2c1146.927%2c70%2c1152.51%2c70L1158.094%2c70' id='mermaid-6-L_R4_R5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R4_R5_0' data-points='W3sieCI6MTA4Ny4wOTM3NSwieSI6NzB9LHsieCI6MTEyNC41OTM3NSwieSI6NzB9LHsieCI6MTE2Mi4wOTM3NSwieSI6NzB9XQ==' data-look='classic' marker-end='url(%23mermaid-6_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R1_R2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R2_R3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R3_R4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R4_R5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-6-flowchart-R1-0' data-look='classic' transform='translate(133.0234375%2c 70)'%3e%3crect class='basic label-container' style='' x='-87.5234375' y='-27' width='175.046875' height='54'/%3e%3cg class='label' style='' transform='translate(-57.5234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='115.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eYour documents%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-R2-1' data-look='classic' transform='translate(390.0234375%2c 70)'%3e%3crect class='basic label-container' style='' x='-94.4765625' y='-27' width='188.953125' height='54'/%3e%3cg class='label' style='' transform='translate(-64.4765625%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.953125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRe-index any time%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-R3-3' data-look='classic' transform='translate(663.3125%2c 70)'%3e%3crect class='basic label-container' style='' x='-103.8125' y='-27' width='207.625' height='54'/%3e%3cg class='label' style='' transform='translate(-73.8125%2c -12)'%3e%3crect/%3e%3cforeignObject width='147.625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eSearch at query time%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-R4-5' data-look='classic' transform='translate(964.609375%2c 70)'%3e%3crect class='basic label-container' style='' x='-122.484375' y='-27' width='244.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-92.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='184.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eAnswer with cited sources%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-6-flowchart-R5-7' data-look='classic' transform='translate(1268.140625%2c 70)'%3e%3crect class='basic label-container' style='' x='-106.046875' y='-27' width='212.09375' height='54'/%3e%3cg class='label' style='' transform='translate(-76.046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='152.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eUpdate: re-index only%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-6-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-6-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
| RAG | Fine-tuning | |
|---|---|---|
| Adds new knowledge | Yes, instantly | Yes, but slowly and imprecisely |
| Updates when docs change | Just re-index | Re-train |
| Shows sources to the user | Naturally | Almost never |
| Hallucination risk | Low, if retrieval is good | Still moderate |
| Cost per query | Higher (more tokens) | Lower |
| Setup cost | Medium | High |
| Good for teaching style / format | Weak | Strong |
RAG is almost always the right first move for “the model doesn’t know this specific thing.” Fine-tuning is the right move for “the model consistently gets the shape of the answer wrong” (wrong voice, wrong format, wrong reasoning pattern). They’re solving different problems and can be used together.
What RAG still cannot do
RAG fixes one specific limit of the chat baseline: the model’s ignorance of external data. It does nothing about the other three limits.
It still cannot take action in the world. It still cannot remember across sessions without more work. It still answers one turn at a time and gives up when the first attempt fails.
Those are the next three rungs. The next one — tool use — is the big one. It is the rung where AI products stop being information retrievers and start being actors.
Read next: Tool Use — Giving the Model Hands.