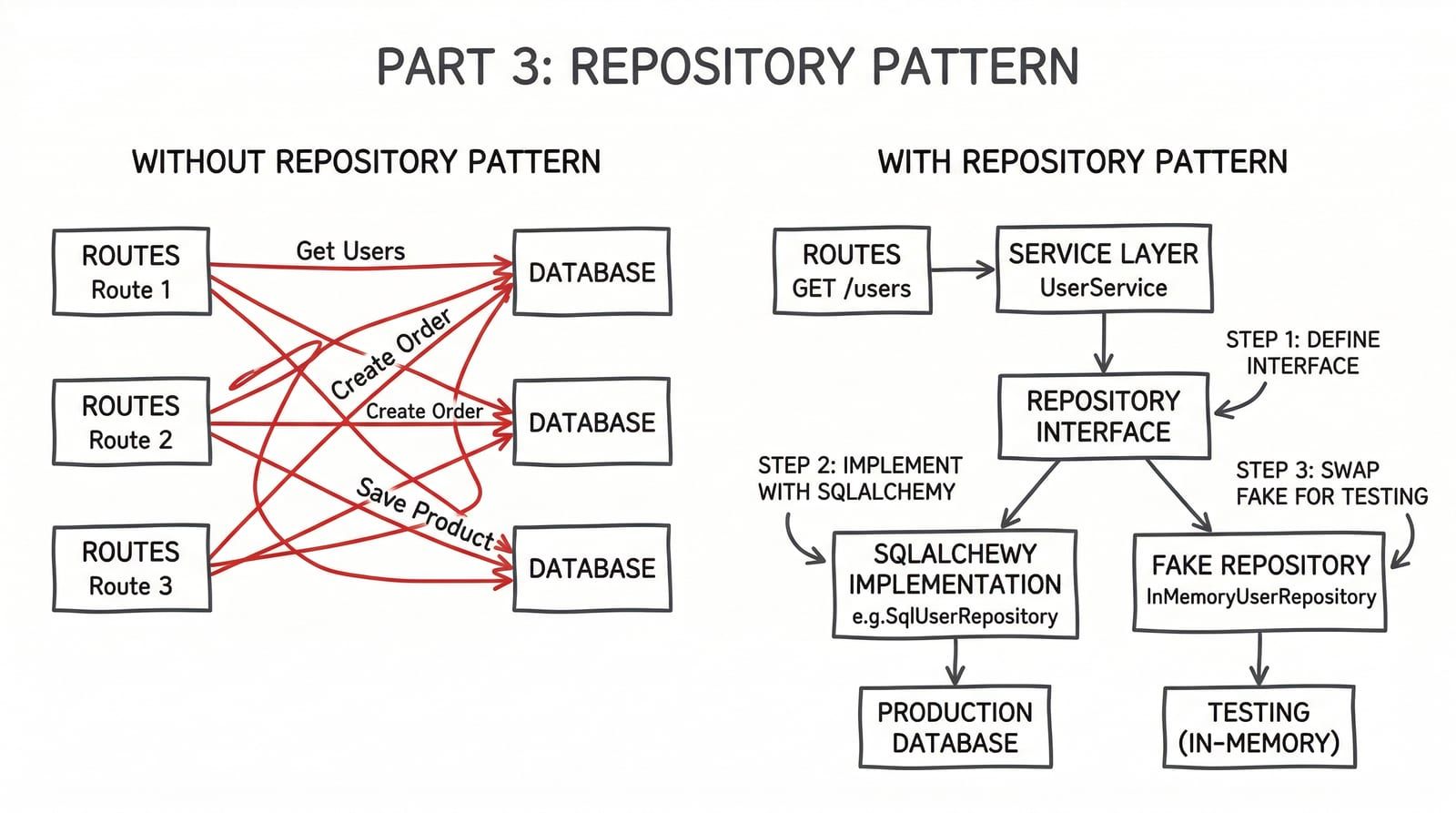
Your SQLAlchemy session is leaking into your route handlers. Every db.execute(select(Book).where(...)) in a FastAPI endpoint is a query you cannot test without spinning up a database, a migration, and test fixtures. Add a second endpoint that needs the same query with slightly different filtering, and you have just duplicated a SQL expression across two files.
The Repository pattern fixes this by placing all database access — queries, inserts, updates, deletes — behind a class interface. Route handlers call services. Services call repositories. Repositories call SQLAlchemy. The database is invisible to everything except the repository.
What the Repository Pattern Solves
Two architectures, same functionality:
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'/%3e%3cg class='edgeLabels'/%3e%3cg class='nodes'%3e%3cg class='root' transform='translate(0%2c 44.482017517089844)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-subGraph1' data-look='classic'%3e%3crect style='' x='8' y='8' width='1049.5625' height='243.03597259521484'/%3e%3cg class='cluster-label' transform='translate(476.3203125%2c 8)'%3e%3cforeignObject width='112.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWith Repository%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M208.672%2c73.759L214.922%2c73.759C221.172%2c73.759%2c233.672%2c73.759%2c247.934%2c78.823C262.197%2c83.886%2c278.221%2c94.013%2c286.234%2c99.077L294.246%2c104.14' id='mermaid-0-L_R2_S2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R2_S2_0' data-points='W3sieCI6MjA4LjY3MTg3NSwieSI6NzMuNzU4OTkzMTQ4ODAzNzF9LHsieCI6MjQ2LjE3MTg3NSwieSI6NzMuNzU4OTkzMTQ4ODAzNzF9LHsieCI6Mjk3LjYyNzQ3NjU0NDExNzc3LCJ5IjoxMDYuMjc2OTc5NDQ2NDExMTN9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M385.956%2c106.277L394.052%2c101.484C402.148%2c96.691%2c418.339%2c87.104%2c432.019%2c82.311C445.698%2c77.518%2c456.865%2c77.518%2c462.448%2c77.518L468.031%2c77.518' id='mermaid-0-L_S2_RP_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_RP_0' data-points='W3sieCI6Mzg1Ljk1NTg5MzE5MDAwOTIsInkiOjEwNi4yNzY5Nzk0NDY0MTExM30seyJ4Ijo0MzQuNTMxMjUsInkiOjc3LjUxNzk4NjI5NzYwNzQyfSx7IngiOjQ3Mi4wMzEyNSwieSI6NzcuNTE3OTg2Mjk3NjA3NDJ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M675.219%2c77.518L694.141%2c77.518C713.063%2c77.518%2c750.906%2c77.518%2c790.94%2c77.518C830.974%2c77.518%2c873.198%2c77.518%2c894.31%2c77.518L915.422%2c77.518' id='mermaid-0-L_RP_DB2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RP_DB2_0' data-points='W3sieCI6Njc1LjIxODc1LCJ5Ijo3Ny41MTc5ODYyOTc2MDc0Mn0seyJ4Ijo3ODguNzUsInkiOjc3LjUxNzk4NjI5NzYwNzQyfSx7IngiOjkxOS40MjE4NzUsInkiOjc3LjUxNzk4NjI5NzYwNzQyfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M171.758%2c189.036L184.16%2c189.036C196.563%2c189.036%2c221.367%2c189.036%2c241.292%2c184.582C261.216%2c180.129%2c276.261%2c171.222%2c283.783%2c166.768L291.305%2c162.315' id='mermaid-0-L_T2_S2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T2_S2_0' data-points='W3sieCI6MTcxLjc1NzgxMjUsInkiOjE4OS4wMzU5NzI1OTUyMTQ4NH0seyJ4IjoyNDYuMTcxODc1LCJ5IjoxODkuMDM1OTcyNTk1MjE0ODR9LHsieCI6Mjk0Ljc0NzIzMTgwOTk5MDgsInkiOjE2MC4yNzY5Nzk0NDY0MTExM31d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M385.956%2c160.277L394.052%2c165.07C402.148%2c169.863%2c418.339%2c179.45%2c434.243%2c184.243C450.146%2c189.036%2c465.76%2c189.036%2c473.568%2c189.036L481.375%2c189.036' id='mermaid-0-L_S2_FRP_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_FRP_0' data-points='W3sieCI6Mzg1Ljk1NTg5MzE5MDAwOTIsInkiOjE2MC4yNzY5Nzk0NDY0MTExM30seyJ4Ijo0MzQuNTMxMjUsInkiOjE4OS4wMzU5NzI1OTUyMTQ4NH0seyJ4Ijo0ODUuMzc1LCJ5IjoxODkuMDM1OTcyNTk1MjE0ODR9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M661.875%2c189.036L683.021%2c189.036C704.167%2c189.036%2c746.458%2c189.036%2c785.859%2c189.036C825.26%2c189.036%2c861.771%2c189.036%2c880.026%2c189.036L898.281%2c189.036' id='mermaid-0-L_FRP_M_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_FRP_M_0' data-points='W3sieCI6NjYxLjg3NSwieSI6MTg5LjAzNTk3MjU5NTIxNDg0fSx7IngiOjc4OC43NSwieSI6MTg5LjAzNTk3MjU5NTIxNDg0fSx7IngiOjkwMi4yODEyNSwieSI6MTg5LjAzNTk3MjU5NTIxNDg0fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_R2_S2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S2_RP_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(788.75%2c 77.51798629760742)'%3e%3cg class='label' data-id='L_RP_DB2_0' transform='translate(-76.03125%2c -12)'%3e%3cforeignObject width='152.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eSQLAlchemy session%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_T2_S2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S2_FRP_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(788.75%2c 189.03597259521484)'%3e%3cg class='label' data-id='L_FRP_M_0' transform='translate(-52.453125%2c -12)'%3e%3cforeignObject width='104.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3ein-memory dict%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-R2-6' data-look='classic' transform='translate(127.0859375%2c 73.75899314880371)'%3e%3crect class='basic label-container' style='fill:%23e8f4f8 !important%3bstroke:%230D6B6E !important' x='-81.5859375' y='-27' width='163.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-51.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='103.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRoute Handler%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-S2-7' data-look='classic' transform='translate(340.3515625%2c 133.27697944641113)'%3e%3crect class='basic label-container' style='fill:%23e8f4f8 !important%3bstroke:%230D6B6E !important' x='-56.6796875' y='-27' width='113.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-26.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='53.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eService%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-RP-9' data-look='classic' transform='translate(573.625%2c 77.51798629760742)'%3e%3crect class='basic label-container' style='fill:%23e8f4f8 !important%3bstroke:%230D6B6E !important' x='-101.59375' y='-27' width='203.1875' height='54'/%3e%3cg class='label' style='' transform='translate(-71.59375%2c -12)'%3e%3crect/%3e%3cforeignObject width='143.1875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRepository Interface%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-DB2-11' data-look='classic' transform='translate(961.171875%2c 77.51798629760742)'%3e%3cpath d='M0%2c10.011990407673862 a41.75%2c10.011990407673862 0%2c0%2c0 83.5%2c0 a41.75%2c10.011990407673862 0%2c0%2c0 -83.5%2c0 l0%2c49.01199040767386 a41.75%2c10.011990407673862 0%2c0%2c0 83.5%2c0 l0%2c-49.01199040767386' class='basic label-container outer-path' style='' transform='translate(-41.75%2c -34.517985611510795)'/%3e%3cg class='label' style='' transform='translate(-34.25%2c -2)'%3e%3crect/%3e%3cforeignObject width='68.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-T2-12' data-look='classic' transform='translate(127.0859375%2c 189.03597259521484)'%3e%3crect class='basic label-container' style='fill:%23e8f4f8 !important%3bstroke:%230D6B6E !important' x='-44.671875' y='-27' width='89.34375' height='54'/%3e%3cg class='label' style='' transform='translate(-14.671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='29.34375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTest%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-FRP-15' data-look='classic' transform='translate(573.625%2c 189.03597259521484)'%3e%3crect class='basic label-container' style='fill:%23e8f4f8 !important%3bstroke:%230D6B6E !important' x='-88.25' y='-27' width='176.5' height='54'/%3e%3cg class='label' style='' transform='translate(-58.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='116.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFake Repository%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-M-17' data-look='classic' transform='translate(961.171875%2c 189.03597259521484)'%3e%3crect class='basic label-container' style='' x='-58.890625' y='-27' width='117.78125' height='54'/%3e%3cg class='label' style='' transform='translate(-28.890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='57.78125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMemory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='root' transform='translate(1099.5625%2c 0)'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-subGraph0' data-look='classic'%3e%3crect style='' x='8' y='8' width='544.28125' height='332'/%3e%3cg class='cluster-label' transform='translate(212.5546875%2c 8)'%3e%3cforeignObject width='135.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWithout Repository%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M208.672%2c70L227.223%2c70C245.773%2c70%2c282.875%2c70%2c319.448%2c83.867C356.021%2c97.735%2c392.066%2c125.469%2c410.089%2c139.336L428.111%2c153.204' id='mermaid-0-L_R1_DB1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_R1_DB1_0' data-points='W3sieCI6MjA4LjY3MTg3NSwieSI6NzB9LHsieCI6MzE5Ljk3NjU2MjUsInkiOjcwfSx7IngiOjQzMS4yODEyNSwieSI6MTU1LjY0MzA0NTQ4Mzk4NDQyfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M183.766%2c174L206.467%2c174C229.169%2c174%2c274.573%2c174%2c315.159%2c174C355.745%2c174%2c391.513%2c174%2c409.397%2c174L427.281%2c174' id='mermaid-0-L_S1_DB1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S1_DB1_0' data-points='W3sieCI6MTgzLjc2NTYyNSwieSI6MTc0fSx7IngiOjMxOS45NzY1NjI1LCJ5IjoxNzR9LHsieCI6NDMxLjI4MTI1LCJ5IjoxNzR9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M171.758%2c278L196.461%2c278C221.164%2c278%2c270.57%2c278%2c313.296%2c264.133C356.021%2c250.265%2c392.066%2c222.531%2c410.089%2c208.664L428.111%2c194.796' id='mermaid-0-L_T1_DB1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T1_DB1_0' data-points='W3sieCI6MTcxLjc1NzgxMjUsInkiOjI3OH0seyJ4IjozMTkuOTc2NTYyNSwieSI6Mjc4fSx7IngiOjQzMS4yODEyNSwieSI6MTkyLjM1Njk1NDUxNjAxNTU4fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(319.9765625%2c 70)'%3e%3cg class='label' data-id='L_R1_DB1_0' transform='translate(-73.8046875%2c -12)'%3e%3cforeignObject width='147.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eselect(Book).where()%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(319.9765625%2c 174)'%3e%3cg class='label' data-id='L_S1_DB1_0' transform='translate(-73.8046875%2c -12)'%3e%3cforeignObject width='147.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eselect(Book).where()%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(319.9765625%2c 278)'%3e%3cg class='label' data-id='L_T1_DB1_0' transform='translate(-52.0234375%2c -12)'%3e%3cforeignObject width='104.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eNeeds real DB%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-R1-0' data-look='classic' transform='translate(127.0859375%2c 70)'%3e%3crect class='basic label-container' style='fill:%23fde8e8 !important%3bstroke:%23c0392b !important' x='-81.5859375' y='-27' width='163.171875' height='54'/%3e%3cg class='label' style='' transform='translate(-51.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='103.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRoute Handler%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-DB1-1' data-look='classic' transform='translate(473.03125%2c 174)'%3e%3cpath d='M0%2c10.011990407673862 a41.75%2c10.011990407673862 0%2c0%2c0 83.5%2c0 a41.75%2c10.011990407673862 0%2c0%2c0 -83.5%2c0 l0%2c49.01199040767386 a41.75%2c10.011990407673862 0%2c0%2c0 83.5%2c0 l0%2c-49.01199040767386' class='basic label-container outer-path' style='' transform='translate(-41.75%2c -34.517985611510795)'/%3e%3cg class='label' style='' transform='translate(-34.25%2c -2)'%3e%3crect/%3e%3cforeignObject width='68.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-S1-2' data-look='classic' transform='translate(127.0859375%2c 174)'%3e%3crect class='basic label-container' style='fill:%23fde8e8 !important%3bstroke:%23c0392b !important' x='-56.6796875' y='-27' width='113.359375' height='54'/%3e%3cg class='label' style='' transform='translate(-26.6796875%2c -12)'%3e%3crect/%3e%3cforeignObject width='53.359375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eService%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-T1-4' data-look='classic' transform='translate(127.0859375%2c 278)'%3e%3crect class='basic label-container' style='fill:%23fde8e8 !important%3bstroke:%23c0392b !important' x='-44.671875' y='-27' width='89.34375' height='54'/%3e%3cg class='label' style='' transform='translate(-14.671875%2c -12)'%3e%3crect/%3e%3cforeignObject width='29.34375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTest%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Without the pattern, every layer that needs data talks directly to SQLAlchemy. A test for the service layer requires a real database connection. With the pattern, the test substitutes a fake repository — the service is isolated from the database entirely.
The Full BookRepository Implementation
Building on the Protocol from Part 2, here is the complete BookRepository with eager loading, a search query, integrity error handling, and a count method:
from sqlalchemy.ext.asyncio import AsyncSessionfrom sqlalchemy import select, funcfrom sqlalchemy.orm import selectinloadfrom sqlalchemy.exc import IntegrityErrorfrom src.models.book import Bookfrom src.models.author import Authorfrom src.schemas.book import BookCreate, BookResponse, BookWithAuthorResponse
class BookRepository: def __init__(self, session: AsyncSession) -> None: self._session = session
async def get_by_id(self, book_id: int) -> BookWithAuthorResponse | None: result = await self._session.execute( select(Book) .options(selectinload(Book.author)) .where(Book.id == book_id) ) book = result.scalar_one_or_none() return BookWithAuthorResponse.model_validate(book) if book else None
async def list_all( self, *, limit: int = 50, offset: int = 0, ) -> list[BookResponse]: result = await self._session.execute( select(Book).limit(limit).offset(offset) ) return [BookResponse.model_validate(b) for b in result.scalars()]
async def search(self, query: str, *, limit: int = 20) -> list[BookResponse]: result = await self._session.execute( select(Book) .where(Book.title.ilike(f"%{query}%")) .limit(limit) ) return [BookResponse.model_validate(b) for b in result.scalars()]
async def create(self, data: BookCreate) -> BookResponse: book = Book(**data.model_dump()) self._session.add(book) try: await self._session.commit() except IntegrityError: await self._session.rollback() raise ValueError(f"Book with ISBN {data.isbn} already exists") await self._session.refresh(book) return BookResponse.model_validate(book)
async def delete(self, book_id: int) -> bool: book = await self._session.get(Book, book_id) if not book: return False await self._session.delete(book) await self._session.commit() return True
async def count(self) -> int: result = await self._session.execute( select(func.count()).select_from(Book) ) return result.scalar_one()Three patterns worth noting in this implementation:
selectinload for related data. get_by_id uses selectinload(Book.author) to fetch the author in a second query batched by SQLAlchemy — not an N+1 query, but also not a JOIN. Use selectinload when you need the related object on a single entity fetch. Use joinedload for list queries where the JOIN reduces round-trips.
IntegrityError handling. The create method catches IntegrityError — the exception raised when the unique constraint on isbn is violated — rolls back the session, and raises a domain exception (ValueError) that the service layer can catch and convert to a 409 Conflict HTTP response. The database error never leaks to the API layer.
scalar_one_or_none vs scalar_one. scalar_one_or_none() returns None when no row matches. scalar_one() raises NoResultFound when no row matches and MultipleResultsFound when more than one matches. Use scalar_one_or_none for lookup by ID (user may request a missing ID). Use scalar_one for lookups that must exist (e.g., fetching the current user by session token).
Transaction Management
The repository handles single-operation transactions internally (each method commits its own changes). When a service needs to perform multiple operations atomically — create an order and add line items — it manages the transaction externally:
from sqlalchemy.ext.asyncio import AsyncSessionfrom src.repositories.book_repository import BookRepositoryfrom src.repositories.order_repository import OrderRepositoryfrom src.schemas.order import OrderCreate, OrderResponse
class OrderService: def __init__( self, session: AsyncSession, order_repo: OrderRepository, book_repo: BookRepository, ) -> None: self._session = session self._order_repo = order_repo self._book_repo = book_repo
async def place_order( self, user_id: int, book_ids: list[int], ) -> OrderResponse: async with self._session.begin(): # Both operations share the same transaction order = await self._order_repo.create(user_id=user_id) for book_id in book_ids: await self._order_repo.add_item(order.id, book_id) # Commit happens automatically when the context exits without error # Rollback happens automatically if an exception is raised return orderWhen the async with self._session.begin() block completes without an exception, SQLAlchemy commits automatically. If any statement inside the block raises — say, add_item finds the book does not exist — SQLAlchemy rolls back all changes from that transaction, including the create_order call.
Connection Pooling Configuration
The default create_async_engine configuration is fine for development but too conservative for production. Here is a production-ready async engine setup:
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmakerfrom src.core.config import settings
engine = create_async_engine( settings.DATABASE_URL, pool_size=10, max_overflow=20, pool_timeout=30, pool_recycle=1800, # recycle connections every 30 minutes pool_pre_ping=True, # verify connection health before use echo=settings.DEBUG,)
AsyncSessionLocal = async_sessionmaker(engine, expire_on_commit=False)pool_pre_ping=True sends a cheap SELECT 1 before returning a connection from the pool. This catches connections that were dropped by the database server (e.g., after a 30-minute idle timeout) before your application tries to use them. Without this, you get OperationalError: server closed the connection unexpectedly under low traffic.
Here is a guide to sizing the pool for different environments:
| Environment | pool_size | max_overflow | pool_recycle |
|---|---|---|---|
| Development (local) | 2 | 5 | 3600 (1 hour) |
| Staging (1-2 replicas) | 5 | 10 | 1800 (30 min) |
| Production (load balanced) | 10 | 20 | 1800 (30 min) |
| Production (high throughput) | 20 | 40 | 900 (15 min) |
The formula: pool_size + max_overflow is the maximum number of concurrent database connections from a single process. For a PostgreSQL server with a max_connections = 100 limit and three application replicas: (10 + 20) * 3 = 90 — comfortably under the limit with headroom for admin connections.
The FastAPI Dependency for Sessions
FastAPI’s dependency injection system wires the session and repository into route handlers without manual instantiation. This is the bridge between the HTTP layer and the repository layer:
from typing import AsyncGeneratorfrom fastapi import Dependsfrom sqlalchemy.ext.asyncio import AsyncSessionfrom src.db.session import AsyncSessionLocalfrom src.repositories.book_repository import BookRepository
async def get_db() -> AsyncGenerator[AsyncSession, None]: async with AsyncSessionLocal() as session: yield session
async def get_book_repo( session: AsyncSession = Depends(get_db),) -> BookRepository: return BookRepository(session)Usage in a route handler:
from fastapi import APIRouter, Depends, HTTPExceptionfrom src.api.deps import get_book_repofrom src.repositories.book_repository import BookRepositoryfrom src.schemas.book import BookResponse
router = APIRouter(prefix="/books", tags=["books"])
@router.get("/{book_id}", response_model=BookResponse)async def get_book( book_id: int, repo: BookRepository = Depends(get_book_repo),) -> BookResponse: book = await repo.get_by_id(book_id) if not book: raise HTTPException(status_code=404, detail="Book not found") return bookThe route handler does not know the session exists. It receives a BookRepository and calls get_by_id. The async with AsyncSessionLocal() as session in get_db ensures the session is closed after every request — even if the request raises an exception.
Keeping the Repository Focused
A repository should have one responsibility: database access for a single entity. When a repository method grows beyond 20-25 lines, it is usually doing too much. Common signals:
- The method fetches an entity, applies business logic, and updates a different entity — split the logic into the service
- The method builds a complex query conditionally based on many optional parameters — extract the query builder to a separate function
- The method calls another repository — services coordinate multiple repositories, not repositories themselves
A well-structured repository is boring. It is a thin layer of SQLAlchemy calls with consistent error handling. The interesting code lives in the service layer, not here.
Key Takeaways
- Repository pattern isolates database access: only repositories import from SQLAlchemy; services and route handlers never call
session.execute()directly selectinloadvsjoinedload: useselectinloadfor single-entity eager loading,joinedloadfor list queries; never rely on lazy loading in an async contextIntegrityErrorhandling belongs in the repository: catch it, rollback, raise a domain exception; let the service layer decide the HTTP status code- Transaction boundaries belong in the service: repositories commit their own single-operation transactions; services manage multi-operation transactions with
session.begin() pool_pre_ping=Truein production: eliminates stale connection errors under low traffic; the overhead is negligible