ShelfWise deploys three times a day. Each deploy takes about 30 seconds to roll out. At peak load, the platform handles 12 requests per second. That means every deploy risks dropping roughly 360 requests — orders that vanish, inventory updates that never land, webhooks that fire but never complete.
For months, nobody noticed. The frontend retried silently, users saw a brief spinner, and support tickets trickled in as “intermittent errors.” Then the team calculated the cost: 12 dropped requests per deploy, 3 deploys per day, 30 days per month. Over a thousand lost transactions per month, some of them order placements from enterprise tenants with SLAs.
The fix is not “deploy less often.” The fix is making deploys invisible to every client, every time.
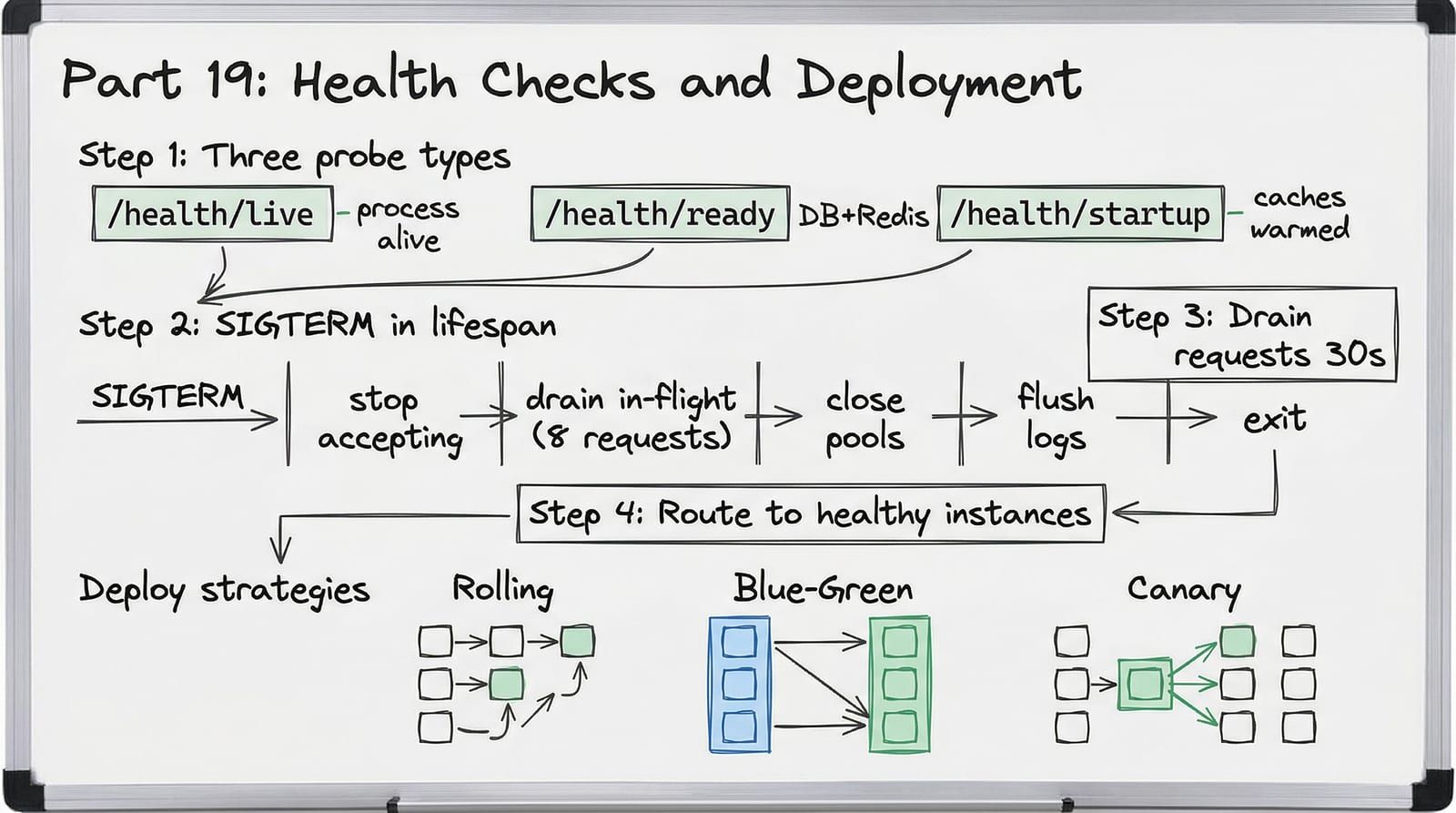
The Three Health Probes
Kubernetes, ECS, and every serious load balancer support three distinct probes. Each answers a different question, and conflating them causes cascading failures.
from __future__ import annotationsfrom datetime import UTC, datetimefrom typing import Annotatedfrom fastapi import APIRouter, Depends, statusfrom fastapi.responses import JSONResponsefrom sqlalchemy import textfrom sqlalchemy.ext.asyncio import AsyncSessionfrom src.db.session import get_session
router = APIRouter(prefix="/health", tags=["health"])
@router.get("/live", status_code=status.HTTP_200_OK)async def liveness() -> dict[str, str]: """Is the process running and not deadlocked?
This endpoint does zero I/O. If it fails, the process is broken and the orchestrator should kill and replace it. """ return {"status": "alive", "timestamp": datetime.now(UTC).isoformat()}
@router.get("/ready")async def readiness( session: Annotated[AsyncSession, Depends(get_session)],) -> JSONResponse: """Can this instance serve traffic?
Checks every downstream dependency. If any check fails, the load balancer stops sending traffic but does NOT kill the instance — it may recover. """ checks: dict[str, bool] = {} all_healthy = True
# Database try: await session.execute(text("SELECT 1")) checks["database"] = True except Exception: checks["database"] = False all_healthy = False
# Redis try: from src.cache.redis import get_redis_pool redis = get_redis_pool() await redis.ping() checks["redis"] = True except Exception: checks["redis"] = False all_healthy = False
status_code = status.HTTP_200_OK if all_healthy else status.HTTP_503_SERVICE_UNAVAILABLE return JSONResponse( content={"status": "ready" if all_healthy else "degraded", "checks": checks}, status_code=status_code, )
@router.get("/startup")async def startup_probe() -> JSONResponse: """Has the application finished initializing?
Returns 200 only after migrations are verified, caches are warmed, and the application is fully ready to handle its first request. Unlike readiness, this runs only during boot — not continuously. """ from src.core.app_state import app_state
if not app_state.startup_complete: return JSONResponse( content={"status": "starting"}, status_code=status.HTTP_503_SERVICE_UNAVAILABLE, ) return JSONResponse(content={"status": "started"}, status_code=status.HTTP_200_OK)| Probe | Question | Failure Action | I/O Allowed | Frequency |
|---|---|---|---|---|
| Liveness | Is the process alive? | Kill and restart | No — must be instant | Every 10s |
| Readiness | Can it serve traffic? | Remove from load balancer | Yes — check dependencies | Every 5s |
| Startup | Has it finished booting? | Keep waiting (do not kill) | Yes — one-time checks | Every 3s until ready |
Dependency Health Checks with Timeout
A readiness check that hangs for 30 seconds waiting for a dead Redis is worse than no check at all. Every dependency check needs a timeout shorter than the probe interval.
from __future__ import annotationsimport asynciofrom dataclasses import dataclass, fieldfrom typing import Callable, Awaitable
@dataclass(frozen=True, slots=True)class HealthCheckResult: name: str healthy: bool latency_ms: float error: str | None = None
@dataclassclass HealthChecker: """Runs dependency checks with individual timeouts.""" checks: dict[str, Callable[[], Awaitable[None]]] = field(default_factory=dict) timeout_seconds: float = 3.0
def register(self, name: str, check: Callable[[], Awaitable[None]]) -> None: self.checks[name] = check
async def run_all(self) -> list[HealthCheckResult]: """Run all checks concurrently with per-check timeouts.""" results: list[HealthCheckResult] = []
async def _run_one(name: str, check: Callable[[], Awaitable[None]]) -> HealthCheckResult: start = asyncio.get_event_loop().time() try: async with asyncio.timeout(self.timeout_seconds): await check() elapsed = (asyncio.get_event_loop().time() - start) * 1000 return HealthCheckResult(name=name, healthy=True, latency_ms=elapsed) except TimeoutError: elapsed = (asyncio.get_event_loop().time() - start) * 1000 return HealthCheckResult( name=name, healthy=False, latency_ms=elapsed, error=f"Timeout after {self.timeout_seconds}s", ) except Exception as exc: elapsed = (asyncio.get_event_loop().time() - start) * 1000 return HealthCheckResult( name=name, healthy=False, latency_ms=elapsed, error=str(exc), )
async with asyncio.TaskGroup() as tg: tasks = [ tg.create_task(_run_one(name, check)) for name, check in self.checks.items() ]
return [t.result() for t in tasks]Register checks during application startup:
health_checker = HealthChecker(timeout_seconds=2.0)health_checker.register("postgres", check_postgres)health_checker.register("redis", check_redis)health_checker.register("s3", check_s3_bucket)Graceful Shutdown: The SIGTERM Handler
When the orchestrator decides to replace your instance, it sends SIGTERM. You have a window — typically 30 seconds — to finish in-flight work before SIGKILL arrives. Without a handler, the process dies mid-request.
Here is the sequence that ShelfWise follows:
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-0 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-0 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-0 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-0 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-0 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .sequenceNumber%7bfill:white%3b%7d%23mermaid-0 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-0 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-0 .labelText%2c%23mermaid-0 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .loopText%2c%23mermaid-0 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-0 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-0 .noteText%2c%23mermaid-0 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-0 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-0 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-0 .actor-man circle%2c%23mermaid-0 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-0 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-0-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-0-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-0-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3ctext x='312' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSIGTERM%3c/text%3e%3cline x1='76' y1='109' x2='547' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='K' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='552' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSet shutdown flag%3c/text%3e%3cpath d='M 552%2c153 C 612%2c143 612%2c183 552%2c173' class='messageLine0' data-et='message' data-id='i1' data-from='App' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='415' y='198' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eReadiness probe returns 503%3c/text%3e%3cline x1='550' y1='227' x2='279' y2='227' class='messageLine0' data-et='message' data-id='i2' data-from='App' data-to='LB' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='276' y='242' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eStop sending new traffic%3c/text%3e%3cpath d='M 276%2c273 C 336%2c263 336%2c303 276%2c293' class='messageLine0' data-et='message' data-id='i3' data-from='LB' data-to='LB' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='763' y='318' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eCancel background tasks (await completion)%3c/text%3e%3cline x1='552' y1='347' x2='974' y2='347' class='messageLine0' data-et='message' data-id='i4' data-from='App' data-to='BG' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='552' y='362' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eWait for in-flight requests (30s max)%3c/text%3e%3cpath d='M 552%2c391 C 612%2c381 612%2c421 552%2c411' class='messageLine0' data-et='message' data-id='i5' data-from='App' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='663' y='436' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eClose connection pool%3c/text%3e%3cline x1='552' y1='465' x2='774' y2='465' class='messageLine0' data-et='message' data-id='i6' data-from='App' data-to='DB' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='552' y='480' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eFlush structured logs%3c/text%3e%3cpath d='M 552%2c509 C 612%2c499 612%2c539 552%2c529' class='messageLine0' data-et='message' data-id='i7' data-from='App' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='315' y='554' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eProcess exits cleanly (code 0)%3c/text%3e%3cline x1='550' y1='583' x2='79' y2='583' class='messageLine0' data-et='message' data-id='i8' data-from='App' data-to='K' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
The implementation uses FastAPI’s lifespan context manager — a single function that handles both startup and shutdown:
from __future__ import annotationsimport asyncioimport signalfrom collections.abc import AsyncIteratorfrom contextlib import asynccontextmanagerfrom fastapi import FastAPIfrom src.core.app_state import app_statefrom src.db.session import engine, async_session_factoryfrom src.cache.redis import redis_poolfrom src.tasks.scheduler import task_scheduler
@asynccontextmanagerasync def lifespan(app: FastAPI) -> AsyncIterator[None]: """Manage application lifecycle: startup and shutdown.""" # --- STARTUP --- # 1. Run migrations check await verify_migrations_current()
# 2. Warm critical caches await warm_tenant_config_cache()
# 3. Start background task scheduler await task_scheduler.start()
# 4. Mark startup complete (startup probe begins returning 200) app_state.startup_complete = True
# 5. Register SIGTERM handler for graceful shutdown shutdown_event = asyncio.Event() loop = asyncio.get_running_loop()
def _signal_handler() -> None: app_state.shutting_down = True shutdown_event.set()
loop.add_signal_handler(signal.SIGTERM, _signal_handler)
yield
# --- SHUTDOWN (runs on SIGTERM or normal exit) --- app_state.shutting_down = True
# 1. Stop accepting new background tasks await task_scheduler.stop(timeout=15.0)
# 2. Wait for in-flight HTTP requests to drain # (Uvicorn handles this via --timeout-graceful-shutdown) await asyncio.sleep(0.5) # Brief pause for request completion
# 3. Close database connections await engine.dispose()
# 4. Close Redis connections await redis_pool.aclose()
# 5. Flush logs import logging for handler in logging.root.handlers: handler.flush()
app = FastAPI(lifespan=lifespan)The app_state.shutting_down flag is checked by the readiness probe. The moment it is set, readiness returns 503, the load balancer stops routing new traffic, and existing requests complete naturally.
from __future__ import annotationsfrom dataclasses import dataclass, field
@dataclassclass AppState: """Mutable application state — not a singleton, injected via lifespan.""" startup_complete: bool = False shutting_down: bool = False active_requests: int = 0
app_state = AppState()The Real Failure: ShelfWise Before Graceful Shutdown
Here is what happened before the SIGTERM handler existed:
- Deploy triggered at 2:14 PM during peak operations.
- Orchestrator sent SIGTERM to old instance.
- Instance died immediately — 8 in-flight requests killed mid-execution.
- Two of those were order placements. The database transaction started but never committed. Inventory was decremented (in a prior query) but the order row was never written.
- Result: phantom inventory loss. Two tenants reported missing stock with no corresponding orders.
- The team spent 4 hours reconciling inventory manually.
After implementing graceful shutdown:
- Deploy triggered at 2:14 PM.
- SIGTERM received. Readiness probe returns 503.
- Load balancer drains traffic to new instance within 3 seconds.
- 8 in-flight requests complete normally, including a 2-second report generation.
- Background tasks finish their current batch (inventory sync for 3 tenants).
- Connection pools close. Process exits with code 0.
- Zero dropped requests. Zero manual intervention. Team does not even notice.
Deployment Strategies
Graceful shutdown handles the instance level. Deployment strategy handles the fleet level — how you roll out new code across multiple instances without downtime.
| Strategy | How It Works | Rollback Speed | Risk | Best For |
|---|---|---|---|---|
| Rolling | Replace instances one at a time | Minutes (re-deploy old) | Brief mixed versions | Stateless services, most deploys |
| Blue-Green | Run two full environments, swap traffic | Seconds (flip DNS/LB) | Double infrastructure cost | Critical releases, database migrations |
| Canary | Route 5% traffic to new version, monitor, expand | Seconds (route 0% to canary) | Lowest risk, highest complexity | High-traffic services, breaking changes |
ShelfWise uses rolling deploys for routine releases and canary deploys for changes that touch the database or payment flow.
Canary Deploy: 5% Traffic, Auto-Rollback
The canary pipeline monitors error rate and p99 latency. If either regresses beyond the threshold, it automatically rolls back — no human intervention required.
"""Canary health verification — runs every 30s during canary window."""from __future__ import annotationsfrom dataclasses import dataclassimport httpx
@dataclass(frozen=True, slots=True)class CanaryMetrics: error_rate: float # 0.0 to 1.0 p99_latency_ms: float request_count: int
@dataclass(frozen=True, slots=True)class CanaryThresholds: max_error_rate: float = 0.01 # 1% error budget max_p99_latency_ms: float = 500 # 500ms p99 ceiling min_requests: int = 100 # Minimum sample size before judging
async def evaluate_canary( metrics: CanaryMetrics, baseline: CanaryMetrics, thresholds: CanaryThresholds,) -> tuple[bool, str]: """Return (should_promote, reason).""" if metrics.request_count < thresholds.min_requests: return True, "Insufficient sample size — continuing canary"
if metrics.error_rate > thresholds.max_error_rate: return False, ( f"Error rate {metrics.error_rate:.2%} exceeds " f"threshold {thresholds.max_error_rate:.2%}" )
if metrics.p99_latency_ms > thresholds.max_p99_latency_ms: return False, ( f"p99 latency {metrics.p99_latency_ms:.0f}ms exceeds " f"threshold {thresholds.max_p99_latency_ms:.0f}ms" )
# Compare against baseline — reject if 2x regression if baseline.p99_latency_ms > 0: ratio = metrics.p99_latency_ms / baseline.p99_latency_ms if ratio > 2.0: return False, f"p99 latency {ratio:.1f}x baseline regression"
return True, "All metrics within thresholds"Feature Flags: Decoupling Deploy from Release
The safest deploy is one that changes nothing visible. Feature flags let you deploy code to production without activating it — then turn it on for specific tenants, percentages, or environments.
from __future__ import annotationsfrom uuid import UUID
class FeatureFlags: """Simple feature flag evaluation — backed by tenant config from Part 10."""
def __init__(self, flags: dict[str, bool | list[str]]) -> None: self._flags = flags
def is_enabled(self, flag: str, *, tenant_id: UUID | None = None) -> bool: """Check if a feature flag is enabled.""" value = self._flags.get(flag) if value is None: return False if isinstance(value, bool): return value # List of tenant IDs — progressive rollout if isinstance(value, list) and tenant_id is not None: return str(tenant_id) in value return FalseUsage in the order service:
async def create_order(self, payload: CreateOrderRequest) -> Order: order = await self._repo.create(payload)
if self._feature_flags.is_enabled("new_invoice_engine", tenant_id=order.tenant_id): await self._new_invoice_service.generate(order) else: await self._legacy_invoice_service.generate(order)
return orderDeploy the new invoice engine on Monday. Enable it for your internal test tenant. Monitor for a week. Enable for 10% of tenants. Monitor. Roll to 100%. Remove the flag. At no point did a deploy carry risk — the flag controlled exposure, not the deployment pipeline.
Health Check Testing
Health checks are production infrastructure. They need tests like any other feature.
import pytestfrom unittest.mock import AsyncMock, patchfrom httpx import AsyncClient
class TestHealthEndpoints: @pytest.mark.asyncio async def test_liveness_always_succeeds(self, client: AsyncClient) -> None: resp = await client.get("/health/live") assert resp.status_code == 200 assert resp.json()["status"] == "alive"
@pytest.mark.asyncio async def test_readiness_fails_when_db_down(self, client: AsyncClient) -> None: with patch("src.api.health.get_session") as mock_session: mock_session.return_value.__aenter__ = AsyncMock( side_effect=ConnectionRefusedError ) resp = await client.get("/health/ready") assert resp.status_code == 503 assert resp.json()["checks"]["database"] is False
@pytest.mark.asyncio async def test_readiness_returns_503_during_shutdown( self, client: AsyncClient ) -> None: from src.core.app_state import app_state app_state.shutting_down = True try: resp = await client.get("/health/ready") assert resp.status_code == 503 finally: app_state.shutting_down = FalseThe Deployment Checklist
Every ShelfWise release follows this checklist. Items 1 through 4 are automated in CI — humans only intervene if something fails.
- Feature flag isolation — New behavior behind flags, defaulting to off.
- Health probes verified — Startup, readiness, and liveness endpoints tested in staging.
- Graceful shutdown tested — Send SIGTERM to staging instance during load test, verify zero dropped requests.
- Canary pipeline configured — Error rate and latency thresholds set, auto-rollback enabled.
- Rollback plan documented — For database migrations, include the reverse migration script.
- Monitoring dashboards open — Error rate, p99 latency, active connections during rollout.
The goal is not zero-risk deploys — that would mean never deploying. The goal is making deploys boring. When every deploy is invisible to users, the team deploys more often, ships smaller changes, and catches problems earlier. That feedback loop is worth more than any single feature.