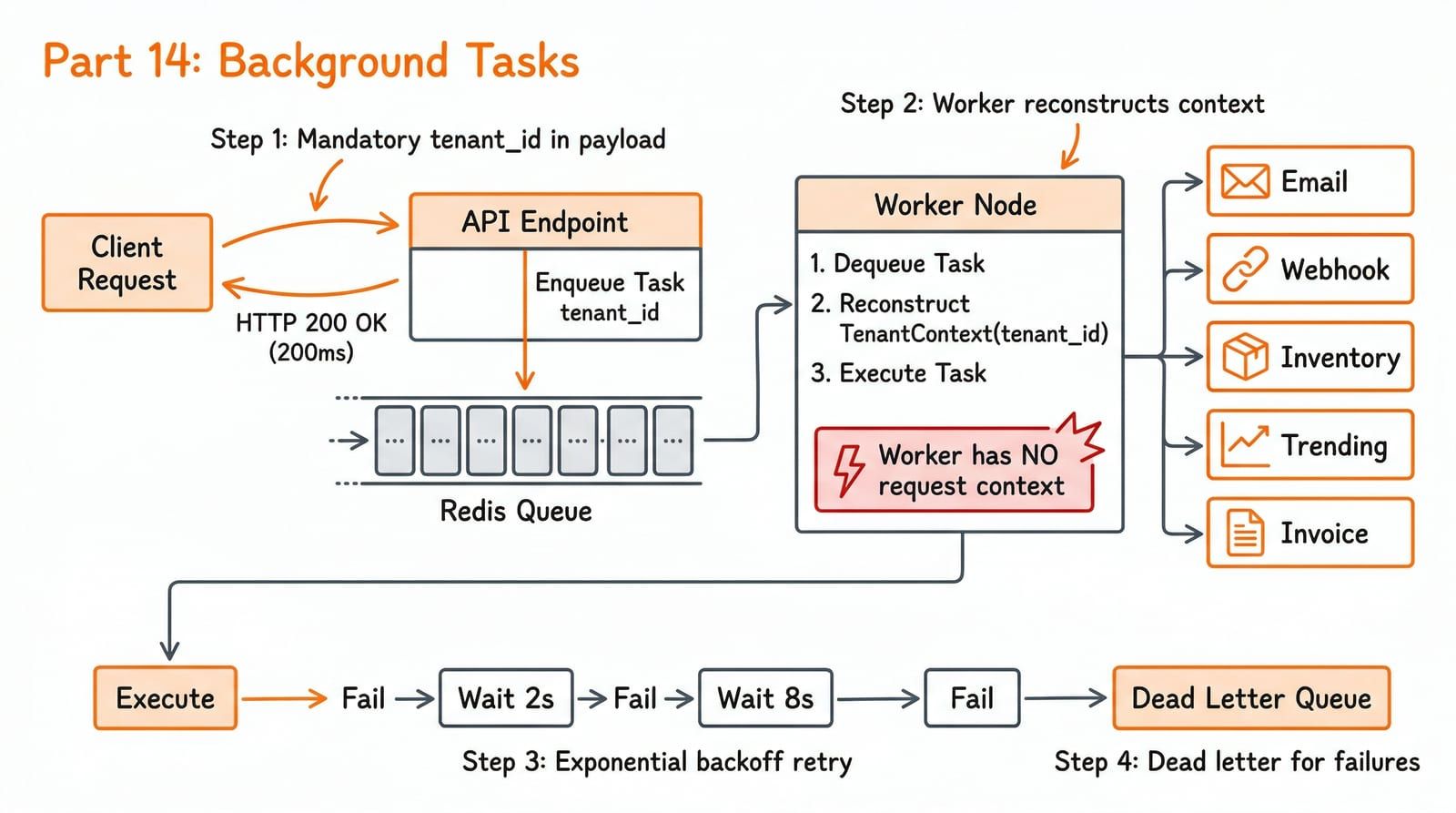
At 1M transactions per day, you cannot process everything in the request cycle. Order confirmation emails, webhook delivery, invoice PDF generation, and analytics aggregation must happen asynchronously. The API returns a 201 in 200ms. The background worker sends the email, fires the webhook, and generates the invoice over the next 30 seconds.
But background tasks are where tenant context silently disappears. The worker has no HTTP request, no middleware, no headers. The TenantContext contextvar from Part 9 is empty. If your task code calls TenantContext.get(), it returns None — and every operation runs without tenant scoping. One team learned this the hard way: six months of background analytics jobs ran without tenant context, attributing every tenant’s metrics to a single default account. The fix required reprocessing 180 days of data.
The solution is explicit: every task carries its tenant ID in the payload, and the worker reconstructs the TenantContext before executing any business logic.
Why ARQ Over Celery
| ARQ | Celery | Dramatiq | |
|---|---|---|---|
| Async native | Yes — built on asyncio from the ground up | No — async support is bolted on via eventlet/gevent | No — sync workers with optional async |
| Broker | Redis only | Redis, RabbitMQ, SQS | Redis, RabbitMQ |
| Dependencies | 1 (redis) | 12+ transitive dependencies | 3-5 depending on broker |
| Task definition | Plain async functions | Decorated functions with Celery app import | Decorated functions with actor import |
| Startup overhead | Minimal — single event loop | Heavy — worker prefork, broker connection pool | Moderate |
| Python 3.12+ compat | Full | Frequent breakage on new Python releases | Good |
| Best for | Async Python backends (FastAPI, Starlette) | Django projects, mixed sync/async | Sync Python backends |
ARQ is the natural choice for a FastAPI backend. The entire ShelfWise stack is async — FastAPI, SQLAlchemy async, httpx, Redis async. Celery’s sync-first architecture forces you to choose between running async code inside sync workers (defeating the purpose) or bolting on eventlet (adding complexity and subtle bugs). ARQ runs on the same event loop as the rest of the application.
Task Definition: The TenantTask Base
Every background task must carry the tenant ID. Forgetting it is the single most common source of multi-tenant bugs in background processing. The TenantTask pattern makes the tenant ID mandatory at the type level:
from dataclasses import dataclassfrom typing import Any
from src.core.tenant import TenantContext
@dataclass(frozen=True, slots=True, kw_only=True)class TenantTask: """Base payload for all background tasks.
tenant_id is required — not optional, not defaulted. The worker MUST reconstruct TenantContext from this field before executing any business logic. """ tenant_id: str
@dataclass(frozen=True, slots=True, kw_only=True)class SendOrderConfirmationTask(TenantTask): order_id: int customer_email: str
@dataclass(frozen=True, slots=True, kw_only=True)class DeliverWebhookTask(TenantTask): order_id: int webhook_url: str event_type: str
@dataclass(frozen=True, slots=True, kw_only=True)class GenerateInvoiceTask(TenantTask): order_id: int
@dataclass(frozen=True, slots=True, kw_only=True)class UpdateTrendingTask(TenantTask): book_ids: list[int]
@dataclass(frozen=True, slots=True, kw_only=True)class UpdateInventoryTask(TenantTask): items: list[dict[str, Any]]Using frozen=True dataclasses makes task payloads immutable — they cannot be accidentally modified between enqueue and execution. Using kw_only=True forces explicit field names at the call site, preventing positional argument mistakes.
Worker Setup: Reconstructing Context
The worker has no HTTP middleware. It must reconstruct the tenant context from the task payload before executing any business logic:
import structlogfrom arq import cronfrom arq.connections import RedisSettingsfrom opentelemetry import trace
from src.core.tenant import TenantContextfrom src.tasks.handlers import ( handle_send_order_confirmation, handle_deliver_webhook, handle_generate_invoice, handle_update_trending, handle_update_inventory,)
logger = structlog.get_logger()tracer = trace.get_tracer(__name__)
async def execute_task(ctx: dict, task_name: str, payload: dict) -> None: """Universal task executor that reconstructs tenant context.
Every task goes through this function. It: 1. Extracts tenant_id from the payload (mandatory) 2. Sets TenantContext for the duration of the task 3. Binds structlog context (request_id, tenant_id) 4. Creates an OpenTelemetry span for the task 5. Dispatches to the appropriate handler """ tenant_id = payload.get("tenant_id") if not tenant_id: logger.error("task_missing_tenant_id", task_name=task_name) raise ValueError(f"Task {task_name} missing required tenant_id")
# Reconstruct the context that middleware would normally provide TenantContext.set(tenant_id) structlog.contextvars.clear_contextvars() structlog.contextvars.bind_contextvars( tenant_id=tenant_id, task_name=task_name, task_id=ctx.get("job_id", "unknown"), )
with tracer.start_as_current_span(f"task.{task_name}") as span: span.set_attribute("tenant_id", tenant_id) span.set_attribute("task_name", task_name)
handlers = { "send_order_confirmation": handle_send_order_confirmation, "deliver_webhook": handle_deliver_webhook, "generate_invoice": handle_generate_invoice, "update_trending": handle_update_trending, "update_inventory": handle_update_inventory, }
handler = handlers.get(task_name) if not handler: logger.error("unknown_task", task_name=task_name) raise ValueError(f"Unknown task: {task_name}")
logger.info("task_started") await handler(ctx, payload) logger.info("task_completed")The execute_task function is the background equivalent of the ObservabilityMiddleware from Part 12. It sets up TenantContext, binds structlog context variables, and creates an OpenTelemetry span — all before any business logic runs. Every log line emitted by the handler includes tenant_id and task_name automatically.
Enqueuing Tasks from the Request Cycle
The API handler creates the order synchronously (within the request) and enqueues background tasks for everything else. The response returns immediately:
# src/services/order_service.py (extended)import structlogfrom arq.connections import ArqRedis
from src.core.tenant import TenantContextfrom src.tasks.base import ( SendOrderConfirmationTask, DeliverWebhookTask, GenerateInvoiceTask, UpdateTrendingTask, UpdateInventoryTask,)
logger = structlog.get_logger()
class OrderService: def __init__( self, *, order_repo: OrderRepositoryProtocol, task_queue: ArqRedis, ) -> None: self._order_repo = order_repo self._queue = task_queue
async def create_order(self, data: OrderCreate) -> OrderResponse: tenant_id = TenantContext.get()
# Synchronous: must complete before response order = await self._order_repo.create(data) logger.info("order_persisted", order_id=order.id)
# Asynchronous: enqueue and return immediately tasks = [ ("send_order_confirmation", SendOrderConfirmationTask( tenant_id=tenant_id, order_id=order.id, customer_email=data.customer_email, )), ("deliver_webhook", DeliverWebhookTask( tenant_id=tenant_id, order_id=order.id, webhook_url=data.webhook_url, event_type="order.created", )), ("generate_invoice", GenerateInvoiceTask( tenant_id=tenant_id, order_id=order.id, )), ("update_trending", UpdateTrendingTask( tenant_id=tenant_id, book_ids=[item.book_id for item in data.items], )), ("update_inventory", UpdateInventoryTask( tenant_id=tenant_id, items=[ {"book_id": item.book_id, "quantity": -item.quantity} for item in data.items ], )), ]
for task_name, payload in tasks: await self._queue.enqueue_job( "execute_task", task_name, payload.__dict__, )
logger.info("tasks_enqueued", count=len(tasks), order_id=order.id) return orderA large order with 50 items returns in ~200ms. The 5 background tasks execute over the next 30 seconds in the worker process. The customer sees their order confirmation page immediately; the email arrives shortly after.
Task Lifecycle
%3bstroke:white%3bstroke-width:1.5%3b%7d%23mermaid-0 .end-state-inner%7bfill:white%3bstroke-width:1.5%3b%7d%23mermaid-0 .node rect%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 .node polygon%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 %5bid%24='-barbEnd'%5d%7bfill:%23666%3b%7d%23mermaid-0 .statediagram-cluster rect%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster-label%2c%23mermaid-0 .nodeLabel%7bcolor:%23111111%3b%7d%23mermaid-0 .statediagram-cluster rect.outer%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-state .divider%7bstroke:black%3b%7d%23mermaid-0 .statediagram-state .title-state%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-cluster.statediagram-cluster .inner%7bfill:white%3b%7d%23mermaid-0 .statediagram-cluster.statediagram-cluster-alt .inner%7bfill:%23f4f4f4%3b%7d%23mermaid-0 .statediagram-cluster .inner%7brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-state rect.basic%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-state rect.divider%7bstroke-dasharray:10%2c10%3bfill:%23f4f4f4%3b%7d%23mermaid-0 .note-edge%7bstroke-dasharray:5%3b%7d%23mermaid-0 .statediagram-note rect%7bfill:%23666%3bstroke:%23999%3bstroke-width:1px%3brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-note rect%7bfill:%23666%3bstroke:%23999%3bstroke-width:1px%3brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-note text%7bfill:white%3b%7d%23mermaid-0 .statediagram-note .nodeLabel%7bcolor:white%3b%7d%23mermaid-0 .statediagram .edgeLabel%7bcolor:red%3b%7d%23mermaid-0 %5bid%24='-dependencyStart'%5d%2c%23mermaid-0 %5bid%24='-dependencyEnd'%5d%7bfill:%23666%3bstroke:%23666%3bstroke-width:1%3b%7d%23mermaid-0 .statediagramTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.statediagram-cluster rect%7bfill:%23eee%3bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.statediagram-cluster rect.outer%7brx:5px%3bry:5px%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cdefs%3e%3cmarker id='mermaid-0_stateDiagram-barbEnd' refX='19' refY='7' markerWidth='20' markerHeight='14' markerUnits='userSpaceOnUse' orient='auto'%3e%3cpath d='M 19%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M198.199%2c22L198.199%2c28.167C198.199%2c34.333%2c198.199%2c46.667%2c198.199%2c59C198.199%2c71.333%2c198.199%2c83.667%2c198.199%2c89.833L198.199%2c96' id='mermaid-0-edge0' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge0' data-points='W3sieCI6MTk4LjE5OTIxODc1LCJ5IjoyMn0seyJ4IjoxOTguMTk5MjE4NzUsInkiOjU5fSx7IngiOjE5OC4xOTkyMTg3NSwieSI6OTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M198.199%2c136L198.199%2c142.167C198.199%2c148.333%2c198.199%2c160.667%2c198.199%2c173C198.199%2c185.333%2c198.199%2c197.667%2c198.199%2c203.833L198.199%2c210' id='mermaid-0-edge1' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge1' data-points='W3sieCI6MTk4LjE5OTIxODc1LCJ5IjoxMzZ9LHsieCI6MTk4LjE5OTIxODc1LCJ5IjoxNzN9LHsieCI6MTk4LjE5OTIxODc1LCJ5IjoyMTB9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M160.395%2c247.08L145.669%2c253.734C130.943%2c260.387%2c101.491%2c273.693%2c86.765%2c289.847C72.039%2c306%2c72.039%2c325%2c72.039%2c344C72.039%2c363%2c72.039%2c382%2c72.039%2c397.667C72.039%2c413.333%2c72.039%2c425.667%2c72.039%2c431.833L72.039%2c438' id='mermaid-0-edge2' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge2' data-points='W3sieCI6MTYwLjM5NDUzMTI1LCJ5IjoyNDcuMDgwNDA5OTQ1MTk2MTV9LHsieCI6NzIuMDM5MDYyNSwieSI6Mjg3fSx7IngiOjcyLjAzOTA2MjUsInkiOjM0NH0seyJ4Ijo3Mi4wMzkwNjI1LCJ5Ijo0MDF9LHsieCI6NzIuMDM5MDYyNSwieSI6NDM4fV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M198.199%2c250L198.199%2c256.167C198.199%2c262.333%2c198.199%2c274.667%2c207.62%2c287C217.042%2c299.333%2c235.884%2c311.667%2c245.305%2c317.833L254.726%2c324' id='mermaid-0-edge3' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge3' data-points='W3sieCI6MTk4LjE5OTIxODc1LCJ5IjoyNTB9LHsieCI6MTk4LjE5OTIxODc1LCJ5IjoyODd9LHsieCI6MjU0LjcyNjE1MTMxNTc4OTQ4LCJ5IjozMjR9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M315.836%2c324L325.258%2c317.833C334.679%2c311.667%2c353.521%2c299.333%2c340.216%2c285.729C326.91%2c272.124%2c281.457%2c257.248%2c258.73%2c249.811L236.004%2c242.373' id='mermaid-0-edge4' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge4' data-points='W3sieCI6MzE1LjgzNjM0ODY4NDIxMDUsInkiOjMyNH0seyJ4IjozNzIuMzYzMjgxMjUsInkiOjI4N30seyJ4IjoyMzYuMDAzOTA2MjUsInkiOjI0Mi4zNzI2MjgxNzkyNDkxfV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M285.281%2c364L285.281%2c370.167C285.281%2c376.333%2c285.281%2c388.667%2c285.281%2c401C285.281%2c413.333%2c285.281%2c425.667%2c285.281%2c431.833L285.281%2c438' id='mermaid-0-edge5' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge5' data-points='W3sieCI6Mjg1LjI4MTI1LCJ5IjozNjR9LHsieCI6Mjg1LjI4MTI1LCJ5Ijo0MDF9LHsieCI6Mjg1LjI4MTI1LCJ5Ijo0Mzh9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M72.039%2c478L72.039%2c484.167C72.039%2c490.333%2c72.039%2c502.667%2c94.442%2c515.819C116.845%2c528.971%2c161.65%2c542.943%2c184.053%2c549.929L206.456%2c556.914' id='mermaid-0-edge6' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge6' data-points='W3sieCI6NzIuMDM5MDYyNSwieSI6NDc4fSx7IngiOjcyLjAzOTA2MjUsInkiOjUxNX0seyJ4IjoyMDYuNDU1NTQwMjk1NDU3OTUsInkiOjU1Ni45MTQyMTU0ODI4NzkxfV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M285.281%2c478L285.281%2c484.167C285.281%2c490.333%2c285.281%2c502.667%2c274.255%2c515.559C263.23%2c528.45%2c241.178%2c541.901%2c230.152%2c548.626L219.126%2c555.351' id='mermaid-0-edge7' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge7' data-points='W3sieCI6Mjg1LjI4MTI1LCJ5Ijo0Nzh9LHsieCI6Mjg1LjI4MTI1LCJ5Ijo1MTV9LHsieCI6MjE5LjEyNjI1NjA1MzY1NjI1LCJ5Ijo1NTUuMzUxNDI5Njc1MTgzN31d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(198.19921875%2c 59)'%3e%3cg class='label' data-id='edge0' transform='translate(-67.15625%2c -12)'%3e%3cforeignObject width='134.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eAPI enqueues task%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(198.19921875%2c 173)'%3e%3cg class='label' data-id='edge1' transform='translate(-74.1015625%2c -12)'%3e%3cforeignObject width='148.203125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eWorker picks up task%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(72.0390625%2c 344)'%3e%3cg class='label' data-id='edge2' transform='translate(-64.0390625%2c -12)'%3e%3cforeignObject width='128.078125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHandler succeeds%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(198.19921875%2c 287)'%3e%3cg class='label' data-id='edge3' transform='translate(-88.046875%2c -12)'%3e%3cforeignObject width='176.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHandler raises exception%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(336.28775%2c 275.19329)'%3e%3cg class='label' data-id='edge4' transform='translate(-66.1171875%2c -12)'%3e%3cforeignObject width='132.234375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eAfter backoff delay%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(285.28125%2c 401)'%3e%3cg class='label' data-id='edge5' transform='translate(-76.484375%2c -12)'%3e%3cforeignObject width='152.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eMax retries exceeded%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='edge6' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(285.28125%2c 515)'%3e%3cg class='label' data-id='edge7' transform='translate(-83.15625%2c -12)'%3e%3cforeignObject width='166.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eManual review required%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-state-root_start-0' data-look='classic' transform='translate(198.19921875%2c 15)'%3e%3ccircle class='state-start' r='7' width='14' height='14'/%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Enqueued-1' data-look='classic' transform='translate(198.19921875%2c 116)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-44.484375' y='-20' width='88.96875' height='40'/%3e%3cg class='label' style='' transform='translate(-36.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='72.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eEnqueued%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Running-4' data-look='classic' transform='translate(198.19921875%2c 230)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-37.8046875' y='-20' width='75.609375' height='40'/%3e%3cg class='label' style='' transform='translate(-29.8046875%2c -12)'%3e%3crect/%3e%3cforeignObject width='59.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eRunning%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Completed-6' data-look='classic' transform='translate(72.0390625%2c 458)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-46.6875' y='-20' width='93.375' height='40'/%3e%3cg class='label' style='' transform='translate(-38.6875%2c -12)'%3e%3crect/%3e%3cforeignObject width='77.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eCompleted%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Retrying-5' data-look='classic' transform='translate(285.28125%2c 344)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-37.7890625' y='-20' width='75.578125' height='40'/%3e%3cg class='label' style='' transform='translate(-29.7890625%2c -12)'%3e%3crect/%3e%3cforeignObject width='59.578125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eRetrying%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-DeadLetter-7' data-look='classic' transform='translate(285.28125%2c 458)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-47.5859375' y='-20' width='95.171875' height='40'/%3e%3cg class='label' style='' transform='translate(-39.5859375%2c -12)'%3e%3crect/%3e%3cforeignObject width='79.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eDeadLetter%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-state-root_end-7' data-look='classic' transform='translate(213.14453125%2c 559)'%3e%3cg class='outer-path'%3e%3cpath d='M7 0 C7 0.40517908122283747%2c 6.964012880168563 0.816513743121899%2c 6.893654271085456 1.2155372436685123 C6.823295662002349 1.6145607442151257%2c 6.716427752933756 2.013397210557766%2c 6.5778483455013586 2.394141003279681 C6.439268938068961 2.7748847960015954%2c 6.26476736710249 3.149104622578984%2c 6.062177826491071 3.4999999999999996 C5.859588285879653 3.8508953774210153%2c 5.622755194947063 4.189128084166967%2c 5.362311101832846 4.499513267805774 C5.10186700871863 4.809898451444582%2c 4.809898451444583 5.10186700871863%2c 4.499513267805775 5.362311101832846 C4.189128084166968 5.622755194947063%2c 3.8508953774210166 5.859588285879652%2c 3.500000000000001 6.06217782649107 C3.149104622578985 6.264767367102489%2c 2.7748847960015963 6.439268938068961%2c 2.3941410032796817 6.5778483455013586 C2.013397210557767 6.716427752933756%2c 1.6145607442151264 6.823295662002349%2c 1.2155372436685128 6.893654271085456 C0.8165137431218992 6.964012880168563%2c 0.4051790812228379 7%2c 4.286263797015736e-16 7 C-0.405179081222837 7%2c -0.8165137431218985 6.964012880168563%2c -1.2155372436685121 6.893654271085456 C-1.6145607442151257 6.823295662002349%2c -2.0133972105577667 6.716427752933756%2c -2.394141003279681 6.5778483455013586 C-2.774884796001595 6.439268938068961%2c -3.149104622578983 6.26476736710249%2c -3.4999999999999982 6.062177826491071 C-3.8508953774210135 5.859588285879653%2c -4.189128084166966 5.6227551949470636%2c -4.499513267805773 5.362311101832848 C-4.809898451444581 5.101867008718632%2c -5.101867008718628 4.809898451444586%2c -5.3623111018328435 4.499513267805779 C-5.622755194947059 4.189128084166971%2c -5.859588285879649 3.8508953774210206%2c -6.062177826491068 3.5000000000000053 C-6.264767367102486 3.14910462257899%2c -6.439268938068958 2.774884796001602%2c -6.577848345501356 2.394141003279688 C-6.716427752933754 2.0133972105577738%2c -6.823295662002347 1.614560744215134%2c -6.893654271085454 1.215537243668521 C-6.9640128801685615 0.816513743121908%2c -6.999999999999999 0.4051790812228472%2c -7 1.0183126166254463e-14 C-7.000000000000001 -0.40517908122282686%2c -6.964012880168565 -0.8165137431218878%2c -6.893654271085459 -1.215537243668501 C-6.823295662002352 -1.6145607442151142%2c -6.716427752933759 -2.0133972105577542%2c -6.577848345501363 -2.394141003279669 C-6.439268938068967 -2.7748847960015834%2c -6.264767367102496 -3.149104622578972%2c -6.062177826491078 -3.4999999999999876 C-5.859588285879661 -3.8508953774210033%2c -5.6227551949470715 -4.1891280841669545%2c -5.362311101832856 -4.499513267805763 C-5.10186700871864 -4.809898451444571%2c -4.809898451444594 -5.10186700871862%2c -4.499513267805787 -5.362311101832836 C-4.189128084166979 -5.622755194947053%2c -3.850895377421028 -5.859588285879643%2c -3.5000000000000133 -6.062177826491062 C-3.1491046225789985 -6.264767367102482%2c -2.774884796001611 -6.439268938068954%2c -2.3941410032796973 -6.577848345501353 C-2.0133972105577835 -6.716427752933752%2c -1.6145607442151435 -6.823295662002345%2c -1.2155372436685306 -6.893654271085453 C-0.8165137431219176 -6.9640128801685615%2c -0.40517908122285695 -6.999999999999999%2c -1.9937625952807352e-14 -7 C0.4051790812228171 -7.000000000000001%2c 0.8165137431218781 -6.964012880168565%2c 1.2155372436684913 -6.89365427108546 C1.6145607442151044 -6.823295662002354%2c 2.013397210557745 -6.716427752933763%2c 2.3941410032796595 -6.5778483455013665 C2.774884796001574 -6.43926893806897%2c 3.149104622578963 -6.2647673671025%2c 3.499999999999979 -6.062177826491083 C3.8508953774209953 -5.859588285879665%2c 4.189128084166947 -5.622755194947077%2c 4.499513267805756 -5.362311101832862 C4.809898451444564 -5.1018670087186475%2c 5.101867008718613 -4.809898451444602%2c 5.362311101832829 -4.499513267805796 C5.622755194947046 -4.189128084166989%2c 5.859588285879637 -3.8508953774210393%2c 6.062177826491056 -3.500000000000025 C6.2647673671024755 -3.1491046225790105%2c 6.439268938068949 -2.774884796001623%2c 6.577848345501348 -2.3941410032797092 C6.716427752933747 -2.0133972105577955%2c 6.823295662002342 -1.6145607442151562%2c 6.893654271085451 -1.2155372436685434 C6.96401288016856 -0.8165137431219307%2c 6.982275711847575 -0.2025895406114567%2c 7 -3.2800750208310675e-14 C7.017724288152425 0.2025895406113911%2c 7.017724288152424 -0.2025895406114242%2c 7 0' stroke='none' stroke-width='0' fill='%23eee' style=''/%3e%3cpath d='M7 0 C7 0.40517908122283747%2c 6.964012880168563 0.816513743121899%2c 6.893654271085456 1.2155372436685123 C6.823295662002349 1.6145607442151257%2c 6.716427752933756 2.013397210557766%2c 6.5778483455013586 2.394141003279681 C6.439268938068961 2.7748847960015954%2c 6.26476736710249 3.149104622578984%2c 6.062177826491071 3.4999999999999996 C5.859588285879653 3.8508953774210153%2c 5.622755194947063 4.189128084166967%2c 5.362311101832846 4.499513267805774 C5.10186700871863 4.809898451444582%2c 4.809898451444583 5.10186700871863%2c 4.499513267805775 5.362311101832846 C4.189128084166968 5.622755194947063%2c 3.8508953774210166 5.859588285879652%2c 3.500000000000001 6.06217782649107 C3.149104622578985 6.264767367102489%2c 2.7748847960015963 6.439268938068961%2c 2.3941410032796817 6.5778483455013586 C2.013397210557767 6.716427752933756%2c 1.6145607442151264 6.823295662002349%2c 1.2155372436685128 6.893654271085456 C0.8165137431218992 6.964012880168563%2c 0.4051790812228379 7%2c 4.286263797015736e-16 7 C-0.405179081222837 7%2c -0.8165137431218985 6.964012880168563%2c -1.2155372436685121 6.893654271085456 C-1.6145607442151257 6.823295662002349%2c -2.0133972105577667 6.716427752933756%2c -2.394141003279681 6.5778483455013586 C-2.774884796001595 6.439268938068961%2c -3.149104622578983 6.26476736710249%2c -3.4999999999999982 6.062177826491071 C-3.8508953774210135 5.859588285879653%2c -4.189128084166966 5.6227551949470636%2c -4.499513267805773 5.362311101832848 C-4.809898451444581 5.101867008718632%2c -5.101867008718628 4.809898451444586%2c -5.3623111018328435 4.499513267805779 C-5.622755194947059 4.189128084166971%2c -5.859588285879649 3.8508953774210206%2c -6.062177826491068 3.5000000000000053 C-6.264767367102486 3.14910462257899%2c -6.439268938068958 2.774884796001602%2c -6.577848345501356 2.394141003279688 C-6.716427752933754 2.0133972105577738%2c -6.823295662002347 1.614560744215134%2c -6.893654271085454 1.215537243668521 C-6.9640128801685615 0.816513743121908%2c -6.999999999999999 0.4051790812228472%2c -7 1.0183126166254463e-14 C-7.000000000000001 -0.40517908122282686%2c -6.964012880168565 -0.8165137431218878%2c -6.893654271085459 -1.215537243668501 C-6.823295662002352 -1.6145607442151142%2c -6.716427752933759 -2.0133972105577542%2c -6.577848345501363 -2.394141003279669 C-6.439268938068967 -2.7748847960015834%2c -6.264767367102496 -3.149104622578972%2c -6.062177826491078 -3.4999999999999876 C-5.859588285879661 -3.8508953774210033%2c -5.6227551949470715 -4.1891280841669545%2c -5.362311101832856 -4.499513267805763 C-5.10186700871864 -4.809898451444571%2c -4.809898451444594 -5.10186700871862%2c -4.499513267805787 -5.362311101832836 C-4.189128084166979 -5.622755194947053%2c -3.850895377421028 -5.859588285879643%2c -3.5000000000000133 -6.062177826491062 C-3.1491046225789985 -6.264767367102482%2c -2.774884796001611 -6.439268938068954%2c -2.3941410032796973 -6.577848345501353 C-2.0133972105577835 -6.716427752933752%2c -1.6145607442151435 -6.823295662002345%2c -1.2155372436685306 -6.893654271085453 C-0.8165137431219176 -6.9640128801685615%2c -0.40517908122285695 -6.999999999999999%2c -1.9937625952807352e-14 -7 C0.4051790812228171 -7.000000000000001%2c 0.8165137431218781 -6.964012880168565%2c 1.2155372436684913 -6.89365427108546 C1.6145607442151044 -6.823295662002354%2c 2.013397210557745 -6.716427752933763%2c 2.3941410032796595 -6.5778483455013665 C2.774884796001574 -6.43926893806897%2c 3.149104622578963 -6.2647673671025%2c 3.499999999999979 -6.062177826491083 C3.8508953774209953 -5.859588285879665%2c 4.189128084166947 -5.622755194947077%2c 4.499513267805756 -5.362311101832862 C4.809898451444564 -5.1018670087186475%2c 5.101867008718613 -4.809898451444602%2c 5.362311101832829 -4.499513267805796 C5.622755194947046 -4.189128084166989%2c 5.859588285879637 -3.8508953774210393%2c 6.062177826491056 -3.500000000000025 C6.2647673671024755 -3.1491046225790105%2c 6.439268938068949 -2.774884796001623%2c 6.577848345501348 -2.3941410032797092 C6.716427752933747 -2.0133972105577955%2c 6.823295662002342 -1.6145607442151562%2c 6.893654271085451 -1.2155372436685434 C6.96401288016856 -0.8165137431219307%2c 6.982275711847575 -0.2025895406114567%2c 7 -3.2800750208310675e-14 C7.017724288152425 0.2025895406113911%2c 7.017724288152424 -0.2025895406114242%2c 7 0' stroke='%23666' stroke-width='2' fill='none' stroke-dasharray='0 0' style=''/%3e%3cg%3e%3cpath d='M2.5 0 C2.5 0.14470681472244193%2c 2.487147457203058 0.29161205111496386%2c 2.46201938253052 0.4341204441673258 C2.436891307857982 0.5766288372196877%2c 2.3987241974763416 0.7190704323420595%2c 2.3492315519647713 0.8550503583141718 C2.299738906453201 0.991030284286284%2c 2.2374169168223177 1.124680222349637%2c 2.165063509461097 1.2499999999999998 C2.092710102099876 1.3753197776503625%2c 2.0081268553382365 1.496117172916774%2c 1.915111107797445 1.6069690242163481 C1.8220953602566536 1.7178208755159223%2c 1.7178208755159226 1.8220953602566536%2c 1.6069690242163484 1.915111107797445 C1.4961171729167742 2.0081268553382365%2c 1.375319777650363 2.0927101020998755%2c 1.2500000000000002 2.1650635094610964 C1.1246802223496375 2.2374169168223172%2c 0.9910302842862845 2.2997389064532%2c 0.8550503583141721 2.349231551964771 C0.7190704323420597 2.3987241974763416%2c 0.576628837219688 2.436891307857982%2c 0.43412044416732604 2.46201938253052 C0.291612051114964 2.487147457203058%2c 0.14470681472244212 2.5%2c 1.5308084989341916e-16 2.5 C-0.1447068147224418 2.5%2c -0.2916120511149638 2.487147457203058%2c -0.43412044416732576 2.46201938253052 C-0.5766288372196877 2.436891307857982%2c -0.7190704323420595 2.3987241974763416%2c -0.8550503583141718 2.3492315519647713 C-0.991030284286284 2.299738906453201%2c -1.124680222349637 2.2374169168223177%2c -1.2499999999999996 2.165063509461097 C-1.375319777650362 2.092710102099876%2c -1.4961171729167733 2.008126855338237%2c -1.6069690242163475 1.9151111077974459 C-1.7178208755159217 1.8220953602566548%2c -1.822095360256653 1.7178208755159234%2c -1.9151111077974443 1.6069690242163495 C-2.0081268553382357 1.4961171729167755%2c -2.0927101020998746 1.3753197776503645%2c -2.1650635094610955 1.250000000000002 C-2.2374169168223164 1.1246802223496395%2c -2.2997389064531992 0.9910302842862865%2c -2.34923155196477 0.8550503583141743 C-2.3987241974763407 0.7190704323420621%2c -2.436891307857981 0.5766288372196907%2c -2.4620193825305194 0.434120444167329 C-2.487147457203058 0.29161205111496724%2c -2.5 0.14470681472244545%2c -2.5 3.636830773662308e-15 C-2.5 -0.14470681472243818%2c -2.4871474572030587 -0.2916120511149599%2c -2.4620193825305208 -0.4341204441673218 C-2.436891307857983 -0.5766288372196837%2c -2.398724197476343 -0.7190704323420553%2c -2.3492315519647726 -0.8550503583141675 C-2.2997389064532023 -0.9910302842862798%2c -2.23741691682232 -1.1246802223496328%2c -2.165063509461099 -1.2499999999999956 C-2.092710102099878 -1.3753197776503583%2c -2.00812685533824 -1.4961171729167695%2c -1.9151111077974488 -1.606969024216344 C-1.8220953602566576 -1.7178208755159183%2c -1.7178208755159263 -1.82209536025665%2c -1.6069690242163523 -1.9151111077974416 C-1.4961171729167784 -2.0081268553382334%2c -1.3753197776503672 -2.0927101020998724%2c -1.2500000000000047 -2.1650635094610937 C-1.1246802223496422 -2.237416916822315%2c -0.9910302842862897 -2.299738906453198%2c -0.8550503583141776 -2.3492315519647686 C-0.7190704323420656 -2.3987241974763394%2c -0.5766288372196942 -2.4368913078579806%2c -0.43412044416733236 -2.462019382530519 C-0.29161205111497057 -2.4871474572030574%2c -0.1447068147224489 -2.4999999999999996%2c -7.120580697431198e-15 -2.5 C0.14470681472243463 -2.5000000000000004%2c 0.29161205111495647 -2.487147457203059%2c 0.4341204441673183 -2.4620193825305217 C0.5766288372196802 -2.436891307857984%2c 0.7190704323420518 -2.3987241974763442%2c 0.8550503583141642 -2.349231551964774 C0.9910302842862766 -2.2997389064532037%2c 1.1246802223496295 -2.2374169168223212%2c 1.2499999999999925 -2.165063509461101 C1.3753197776503554 -2.0927101020998804%2c 1.4961171729167668 -2.008126855338242%2c 1.6069690242163412 -1.915111107797451 C1.7178208755159157 -1.82209536025666%2c 1.8220953602566472 -1.7178208755159294%2c 1.915111107797439 -1.6069690242163557 C2.0081268553382308 -1.496117172916782%2c 2.09271010209987 -1.3753197776503712%2c 2.1650635094610915 -1.2500000000000089 C2.237416916822313 -1.1246802223496466%2c 2.299738906453196 -0.9910302842862939%2c 2.3492315519647673 -0.855050358314182 C2.3987241974763385 -0.71907043234207%2c 2.4368913078579792 -0.5766288372196986%2c 2.462019382530518 -0.4341204441673369 C2.487147457203057 -0.29161205111497523%2c 2.4936698970884197 -0.07235340736123454%2c 2.5 -1.1714553645825241e-14 C2.5063301029115803 0.07235340736121111%2c 2.50633010291158 -0.07235340736122292%2c 2.5 0' stroke='none' stroke-width='0' fill='black' style=''/%3e%3cpath d='M2.5 0 C2.5 0.14470681472244193%2c 2.487147457203058 0.29161205111496386%2c 2.46201938253052 0.4341204441673258 C2.436891307857982 0.5766288372196877%2c 2.3987241974763416 0.7190704323420595%2c 2.3492315519647713 0.8550503583141718 C2.299738906453201 0.991030284286284%2c 2.2374169168223177 1.124680222349637%2c 2.165063509461097 1.2499999999999998 C2.092710102099876 1.3753197776503625%2c 2.0081268553382365 1.496117172916774%2c 1.915111107797445 1.6069690242163481 C1.8220953602566536 1.7178208755159223%2c 1.7178208755159226 1.8220953602566536%2c 1.6069690242163484 1.915111107797445 C1.4961171729167742 2.0081268553382365%2c 1.375319777650363 2.0927101020998755%2c 1.2500000000000002 2.1650635094610964 C1.1246802223496375 2.2374169168223172%2c 0.9910302842862845 2.2997389064532%2c 0.8550503583141721 2.349231551964771 C0.7190704323420597 2.3987241974763416%2c 0.576628837219688 2.436891307857982%2c 0.43412044416732604 2.46201938253052 C0.291612051114964 2.487147457203058%2c 0.14470681472244212 2.5%2c 1.5308084989341916e-16 2.5 C-0.1447068147224418 2.5%2c -0.2916120511149638 2.487147457203058%2c -0.43412044416732576 2.46201938253052 C-0.5766288372196877 2.436891307857982%2c -0.7190704323420595 2.3987241974763416%2c -0.8550503583141718 2.3492315519647713 C-0.991030284286284 2.299738906453201%2c -1.124680222349637 2.2374169168223177%2c -1.2499999999999996 2.165063509461097 C-1.375319777650362 2.092710102099876%2c -1.4961171729167733 2.008126855338237%2c -1.6069690242163475 1.9151111077974459 C-1.7178208755159217 1.8220953602566548%2c -1.822095360256653 1.7178208755159234%2c -1.9151111077974443 1.6069690242163495 C-2.0081268553382357 1.4961171729167755%2c -2.0927101020998746 1.3753197776503645%2c -2.1650635094610955 1.250000000000002 C-2.2374169168223164 1.1246802223496395%2c -2.2997389064531992 0.9910302842862865%2c -2.34923155196477 0.8550503583141743 C-2.3987241974763407 0.7190704323420621%2c -2.436891307857981 0.5766288372196907%2c -2.4620193825305194 0.434120444167329 C-2.487147457203058 0.29161205111496724%2c -2.5 0.14470681472244545%2c -2.5 3.636830773662308e-15 C-2.5 -0.14470681472243818%2c -2.4871474572030587 -0.2916120511149599%2c -2.4620193825305208 -0.4341204441673218 C-2.436891307857983 -0.5766288372196837%2c -2.398724197476343 -0.7190704323420553%2c -2.3492315519647726 -0.8550503583141675 C-2.2997389064532023 -0.9910302842862798%2c -2.23741691682232 -1.1246802223496328%2c -2.165063509461099 -1.2499999999999956 C-2.092710102099878 -1.3753197776503583%2c -2.00812685533824 -1.4961171729167695%2c -1.9151111077974488 -1.606969024216344 C-1.8220953602566576 -1.7178208755159183%2c -1.7178208755159263 -1.82209536025665%2c -1.6069690242163523 -1.9151111077974416 C-1.4961171729167784 -2.0081268553382334%2c -1.3753197776503672 -2.0927101020998724%2c -1.2500000000000047 -2.1650635094610937 C-1.1246802223496422 -2.237416916822315%2c -0.9910302842862897 -2.299738906453198%2c -0.8550503583141776 -2.3492315519647686 C-0.7190704323420656 -2.3987241974763394%2c -0.5766288372196942 -2.4368913078579806%2c -0.43412044416733236 -2.462019382530519 C-0.29161205111497057 -2.4871474572030574%2c -0.1447068147224489 -2.4999999999999996%2c -7.120580697431198e-15 -2.5 C0.14470681472243463 -2.5000000000000004%2c 0.29161205111495647 -2.487147457203059%2c 0.4341204441673183 -2.4620193825305217 C0.5766288372196802 -2.436891307857984%2c 0.7190704323420518 -2.3987241974763442%2c 0.8550503583141642 -2.349231551964774 C0.9910302842862766 -2.2997389064532037%2c 1.1246802223496295 -2.2374169168223212%2c 1.2499999999999925 -2.165063509461101 C1.3753197776503554 -2.0927101020998804%2c 1.4961171729167668 -2.008126855338242%2c 1.6069690242163412 -1.915111107797451 C1.7178208755159157 -1.82209536025666%2c 1.8220953602566472 -1.7178208755159294%2c 1.915111107797439 -1.6069690242163557 C2.0081268553382308 -1.496117172916782%2c 2.09271010209987 -1.3753197776503712%2c 2.1650635094610915 -1.2500000000000089 C2.237416916822313 -1.1246802223496466%2c 2.299738906453196 -0.9910302842862939%2c 2.3492315519647673 -0.855050358314182 C2.3987241974763385 -0.71907043234207%2c 2.4368913078579792 -0.5766288372196986%2c 2.462019382530518 -0.4341204441673369 C2.487147457203057 -0.29161205111497523%2c 2.4936698970884197 -0.07235340736123454%2c 2.5 -1.1714553645825241e-14 C2.5063301029115803 0.07235340736121111%2c 2.50633010291158 -0.07235340736122292%2c 2.5 0' stroke='black' stroke-width='2' fill='none' stroke-dasharray='0 0' style=''/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Retry Strategies: Exponential Backoff with Jitter
Transient failures — network timeouts, temporary rate limits, brief database unavailability — resolve themselves if you wait and retry. But retrying immediately floods the failing service. Exponential backoff with jitter spreads retries over time:
import randomimport asynciofrom collections.abc import Awaitable, Callablefrom typing import Any
import structlog
logger = structlog.get_logger()
async def with_retry( fn: Callable[..., Awaitable[Any]], *args: Any, max_retries: int = 3, base_delay: float = 1.0, max_delay: float = 60.0, retryable_exceptions: tuple[type[Exception], ...] = ( ConnectionError, TimeoutError, OSError, ), **kwargs: Any,) -> Any: """Execute an async function with exponential backoff and jitter.
Delay formula: min(max_delay, base_delay * 2^attempt) + random jitter Attempt 1: ~1-2s, Attempt 2: ~2-4s, Attempt 3: ~4-8s """ last_exception: Exception | None = None
for attempt in range(max_retries + 1): try: return await fn(*args, **kwargs) except retryable_exceptions as exc: last_exception = exc if attempt == max_retries: logger.error( "task_retries_exhausted", attempt=attempt, error=str(exc), ) break
delay = min(max_delay, base_delay * (2 ** attempt)) jitter = random.uniform(0, delay * 0.5) total_delay = delay + jitter
logger.warning( "task_retry_scheduled", attempt=attempt + 1, max_retries=max_retries, delay_seconds=round(total_delay, 2), error=str(exc), ) await asyncio.sleep(total_delay)
raise last_exception # type: ignore[misc]The jitter prevents thundering herd: if 100 tasks fail at the same time, they all retry at slightly different times instead of hitting the failing service simultaneously at the 2-second mark.
Task Handlers with Idempotency
A task may execute more than once. The worker might crash after completing the work but before acknowledging the task. The queue redelivers it. If the handler is not idempotent, the customer receives two confirmation emails:
import structlogfrom src.tasks.retry import with_retry
logger = structlog.get_logger()
async def handle_send_order_confirmation(ctx: dict, payload: dict) -> None: """Send order confirmation email. Idempotent via idempotency key.""" order_id = payload["order_id"] email = payload["customer_email"] tenant_id = payload["tenant_id"]
# Idempotency check: has this email already been sent? idempotency_key = f"email:order_confirm:{tenant_id}:{order_id}" redis = ctx["redis"]
already_sent = await redis.set(idempotency_key, "1", nx=True, ex=86400) if not already_sent: logger.info("task_skipped_duplicate", idempotency_key=idempotency_key) return
await with_retry( _send_email, to=email, template="order_confirmation", context={"order_id": order_id, "tenant_id": tenant_id}, ) logger.info("order_confirmation_sent", order_id=order_id)
async def handle_deliver_webhook(ctx: dict, payload: dict) -> None: """Deliver webhook to tenant's configured endpoint. Idempotent via delivery log.""" order_id = payload["order_id"] webhook_url = payload["webhook_url"] event_type = payload["event_type"] tenant_id = payload["tenant_id"]
idempotency_key = f"webhook:{event_type}:{tenant_id}:{order_id}" redis = ctx["redis"]
already_delivered = await redis.set(idempotency_key, "1", nx=True, ex=86400) if not already_delivered: logger.info("task_skipped_duplicate", idempotency_key=idempotency_key) return
await with_retry( _post_webhook, url=webhook_url, event_type=event_type, order_id=order_id, tenant_id=tenant_id, retryable_exceptions=(ConnectionError, TimeoutError), ) logger.info("webhook_delivered", order_id=order_id, event_type=event_type)The idempotency key is {action}:{entity}:{tenant_id}:{id}. The SET NX command (set if not exists) is atomic — if two workers pick up the same task, only one succeeds in setting the key. The other sees already_sent = False and skips execution. The key expires after 24 hours to prevent unbounded growth.
Dead Letter Queue
After max_retries exhausted, the task moves to a dead letter queue for manual investigation. It is not silently dropped:
import orjsonimport structlogfrom datetime import UTC, datetimefrom redis.asyncio import Redis
logger = structlog.get_logger()
async def move_to_dead_letter( redis: Redis, *, task_name: str, payload: dict, error: str, attempts: int,) -> None: """Move a permanently failed task to the dead letter queue.
Tasks in the DLQ are stored as a Redis sorted set keyed by timestamp. Operations can review, retry, or discard them via an admin endpoint. """ entry = { "task_name": task_name, "payload": payload, "error": error, "attempts": attempts, "failed_at": datetime.now(UTC).isoformat(), "tenant_id": payload.get("tenant_id", "unknown"), }
await redis.zadd( "dead_letter_queue", {orjson.dumps(entry): datetime.now(UTC).timestamp()}, )
logger.error( "task_moved_to_dead_letter", task_name=task_name, tenant_id=payload.get("tenant_id"), error=error, attempts=attempts, )The dead letter queue is a Redis sorted set ordered by failure time. Operations can list recent failures, inspect payloads, and selectively retry via an admin API. The alert threshold from Part 12 fires when any task enters the DLQ.
Priority Queues
Not all tasks are equal. Payment capture must happen before report generation. ARQ supports multiple queues with different priorities:
from arq.connections import RedisSettings
class QueueConfig: """Queue configuration with priority levels.""" CRITICAL = "arq:critical" # Payment, inventory — processed first DEFAULT = "arq:default" # Email, webhook — standard priority BACKGROUND = "arq:background" # Reports, analytics — processed when idle
# Enqueue with priorityasync def enqueue_critical(queue, task_name: str, payload: dict) -> None: """Enqueue to the critical queue. Payment, inventory operations.""" await queue.enqueue_job( "execute_task", task_name, payload, _queue_name=QueueConfig.CRITICAL, )
async def enqueue_background(queue, task_name: str, payload: dict) -> None: """Enqueue to the background queue. Reports, analytics.""" await queue.enqueue_job( "execute_task", task_name, payload, _queue_name=QueueConfig.BACKGROUND, )Run separate worker processes for each priority level. Critical workers process payment tasks within seconds. Background workers handle report generation during off-peak hours. If the background queue backs up, critical tasks are unaffected.
Graceful Worker Shutdown
When deploying a new version, workers must finish their current task before shutting down. Killing a worker mid-task means the task is neither completed nor re-queued — it is lost:
# src/tasks/worker.py (extended)import signalimport asyncioimport structlog
logger = structlog.get_logger()
class GracefulWorker: """Worker wrapper that handles SIGTERM for graceful shutdown."""
def __init__(self, drain_timeout: float = 30.0) -> None: self._shutting_down = False self._drain_timeout = drain_timeout
def install_signal_handlers(self) -> None: loop = asyncio.get_event_loop() for sig in (signal.SIGTERM, signal.SIGINT): loop.add_signal_handler(sig, self._handle_shutdown)
def _handle_shutdown(self) -> None: if self._shutting_down: logger.warning("forced_shutdown") raise SystemExit(1) self._shutting_down = True logger.info( "graceful_shutdown_initiated", drain_timeout=self._drain_timeout, )
@property def should_stop(self) -> bool: return self._shutting_downThe first SIGTERM sets _shutting_down = True. The worker finishes its current task and exits cleanly. A second SIGTERM forces immediate shutdown — use this only if the drain timeout is exceeded.
Periodic Tasks: Scheduled Jobs with Tenant Iteration
Some tasks run on a schedule rather than being enqueued by a request. Daily report generation, weekly analytics aggregation, and hourly cache warming all need to iterate over all tenants:
import structlogfrom arq import cron
from src.core.tenant import TenantContextfrom src.repositories.tenant_repo import TenantRepository
logger = structlog.get_logger()
async def daily_report_generation(ctx: dict) -> None: """Generate daily reports for all active tenants.
Runs at 02:00 UTC. Iterates tenants and enqueues one report task per tenant. Each task carries its own tenant_id — no shared state between tenants. """ tenant_repo = TenantRepository(ctx["db_session"]) tenants = await tenant_repo.list_active()
logger.info("periodic_report_started", tenant_count=len(tenants))
for tenant in tenants: await ctx["redis"].enqueue_job( "execute_task", "generate_daily_report", {"tenant_id": tenant.id, "report_date": str(ctx["today"])}, _queue_name="arq:background", )
logger.info("periodic_report_enqueued", tenant_count=len(tenants))
# ARQ worker configurationclass WorkerSettings: functions = [execute_task] cron_jobs = [ cron(daily_report_generation, hour=2, minute=0), ] redis_settings = RedisSettings(host="redis", port=6379) max_jobs = 20 job_timeout = 300The periodic task does not process reports directly. It enqueues one task per tenant, each with its own tenant_id. This means each report task gets its own retry logic, its own deadline, and its own entry in the dead letter queue if it fails. A failure for one tenant does not block reports for other tenants.
The ShelfWise Flow: Large Order Processing
A customer at Powell’s Books places a large order (50 items). Here is the complete flow:
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-1 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-1 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-1 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-1 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-1 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-1 .sequenceNumber%7bfill:white%3b%7d%23mermaid-1 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-1 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-1 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-1 .labelText%2c%23mermaid-1 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .loopText%2c%23mermaid-1 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-1 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-1 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-1 .noteText%2c%23mermaid-1 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-1 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-1 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-1 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-1 .actor-man circle%2c%23mermaid-1 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-1 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-1-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-1-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-1-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-1-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cg data-et='note' data-id='i5'%3e%3crect x='1019' y='295' fill='%23EDF2AE' stroke='%23666' width='176' height='37' class='note'/%3e%3ctext x='1107' y='300' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='noteText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='1107'%3eWorker picks up tasks%3c/tspan%3e%3c/text%3e%3c/g%3e%3cg data-et='note' data-id='i21'%3e%3crect x='666' y='1332' fill='%23EDF2AE' stroke='%23666' width='250' height='37' class='note'/%3e%3ctext x='791' y='1337' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='noteText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='791'%3eAlert fires: DLQ entry for powells%3c/tspan%3e%3c/text%3e%3c/g%3e%3ctext x='219' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ePOST /api/v1/orders (50 items)%3c/text%3e%3cline x1='76' y1='109' x2='361' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='C' data-to='API' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='477' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eINSERT order %2b items%3c/text%3e%3cline x1='366' y1='153' x2='587' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='API' data-to='DB' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='480' y='168' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eorder_id=789%3c/text%3e%3cline x1='590' y1='197' x2='369' y2='197' class='messageLine1' data-et='message' data-id='i2' data-from='DB' data-to='API' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='577' y='212' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eEnqueue 5 tasks (tenant_id=powells)%3c/text%3e%3cline x1='366' y1='241' x2='787' y2='241' class='messageLine0' data-et='message' data-id='i3' data-from='API' data-to='Q' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='222' y='256' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e201 Created (200ms)%3c/text%3e%3cline x1='364' y1='285' x2='79' y2='285' class='messageLine1' data-et='message' data-id='i4' data-from='API' data-to='C' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='951' y='347' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eDequeue send_order_confirmation%3c/text%3e%3cline x1='1106' y1='376' x2='795' y2='376' class='messageLine0' data-et='message' data-id='i6' data-from='W' data-to='Q' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='391' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSet TenantContext('powells')%3c/text%3e%3cpath d='M 1108%2c420 C 1168%2c410 1168%2c450 1108%2c440' class='messageLine0' data-et='message' data-id='i7' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='465' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSend email%3c/text%3e%3cpath d='M 1108%2c494 C 1168%2c484 1168%2c524 1108%2c514' class='messageLine0' data-et='message' data-id='i8' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='951' y='539' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eACK%3c/text%3e%3cline x1='1106' y1='568' x2='795' y2='568' class='messageLine1' data-et='message' data-id='i9' data-from='W' data-to='Q' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='951' y='583' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eDequeue deliver_webhook%3c/text%3e%3cline x1='1106' y1='612' x2='795' y2='612' class='messageLine0' data-et='message' data-id='i10' data-from='W' data-to='Q' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='627' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eSet TenantContext('powells')%3c/text%3e%3cpath d='M 1108%2c656 C 1168%2c646 1168%2c686 1108%2c676' class='messageLine0' data-et='message' data-id='i11' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='701' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ePOST webhook_url%3c/text%3e%3cpath d='M 1108%2c730 C 1168%2c720 1168%2c760 1108%2c750' class='messageLine0' data-et='message' data-id='i12' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='775' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eConnectionError!%3c/text%3e%3cpath d='M 1108%2c804 C 1168%2c794 1168%2c834 1108%2c824' class='messageLine1' data-et='message' data-id='i13' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-crosshead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='1108' y='849' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRetry%3c/text%3e%3cpath d='M 1108%2c878 C 1168%2c868 1168%2c908 1108%2c898' class='messageLine0' data-et='message' data-id='i14' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='923' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ePOST webhook_url%3c/text%3e%3cpath d='M 1108%2c952 C 1168%2c942 1168%2c982 1108%2c972' class='messageLine0' data-et='message' data-id='i15' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='997' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eConnectionError!%3c/text%3e%3cpath d='M 1108%2c1026 C 1168%2c1016 1168%2c1056 1108%2c1046' class='messageLine1' data-et='message' data-id='i16' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-crosshead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='1108' y='1071' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRetry%3c/text%3e%3cpath d='M 1108%2c1100 C 1168%2c1090 1168%2c1130 1108%2c1120' class='messageLine0' data-et='message' data-id='i17' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='1145' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ePOST webhook_url%3c/text%3e%3cpath d='M 1108%2c1174 C 1168%2c1164 1168%2c1204 1108%2c1194' class='messageLine0' data-et='message' data-id='i18' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3ctext x='1108' y='1219' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eConnectionError!%3c/text%3e%3cpath d='M 1108%2c1248 C 1168%2c1238 1168%2c1278 1108%2c1268' class='messageLine1' data-et='message' data-id='i19' data-from='W' data-to='W' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-crosshead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='951' y='1293' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eMove to Dead Letter Queue%3c/text%3e%3cline x1='1106' y1='1322' x2='795' y2='1322' class='messageLine0' data-et='message' data-id='i20' data-from='W' data-to='Q' stroke-width='2' stroke='none' marker-end='url(%23mermaid-1-arrowhead)' style='fill: none%3b'/%3e%3c/svg%3e)
The API responds in 200ms. The email sends successfully. The webhook delivery fails three times and moves to the dead letter queue. The alert from Part 12 fires, and on-call sees exactly which tenant, which order, and which webhook URL failed — including the full error trace.
The Context Propagation Failure Story
A ShelfWise engineering team added background tasks for analytics aggregation. The tasks worked correctly in development — every test passed, every metric looked right. Six months later, a product manager noticed that one tenant had 10x more “orders processed” than their actual order volume, while newer tenants showed zero.
The root cause: the analytics task did not carry tenant_id in its payload. In development, the TenantContext contextvar still held the value from the test setup. In production, the worker’s contextvar was empty on the first task and retained the value from the previous task on subsequent runs.
The first task that happened to execute after worker startup ran with tenant_id=None, which the repository silently treated as the default tenant. Every subsequent task inherited the tenant ID from whatever task ran before it — a random, non-deterministic assignment.
The fix was the TenantTask base class shown earlier: make tenant_id a required field at the type level so the code does not compile without it, and clear_contextvars() at the start of every task execution so context never bleeds between tasks.
Key Takeaways
- ARQ for async-native stacks. If your backend is FastAPI + SQLAlchemy async + httpx, your task queue should be async too. ARQ runs on the same event loop.
- TenantTask base class with mandatory tenant_id. The type system prevents enqueuing tasks without tenant context. This is not a convention — it is a compile-time guarantee.
- Reconstruct context in the worker.
TenantContext.set(),bind_contextvars(), andtracer.start_span()at the start of every task. The worker is the middleware for background processing. - Idempotency keys prevent duplicate execution.
SET NXin Redis ensures at-most-once semantics for side effects. Include tenant ID in the key. - Dead letter queue for permanent failures. Never silently drop a failed task. Alert on DLQ entries and provide admin tooling for inspection and retry.
- Clear contextvars between tasks. Without clearing, tenant context from the previous task contaminates the current one. This is the background-task equivalent of a cross-tenant data leak.
Next: Part 15 covers API versioning and backward compatibility — how to evolve your API contract without breaking existing clients.