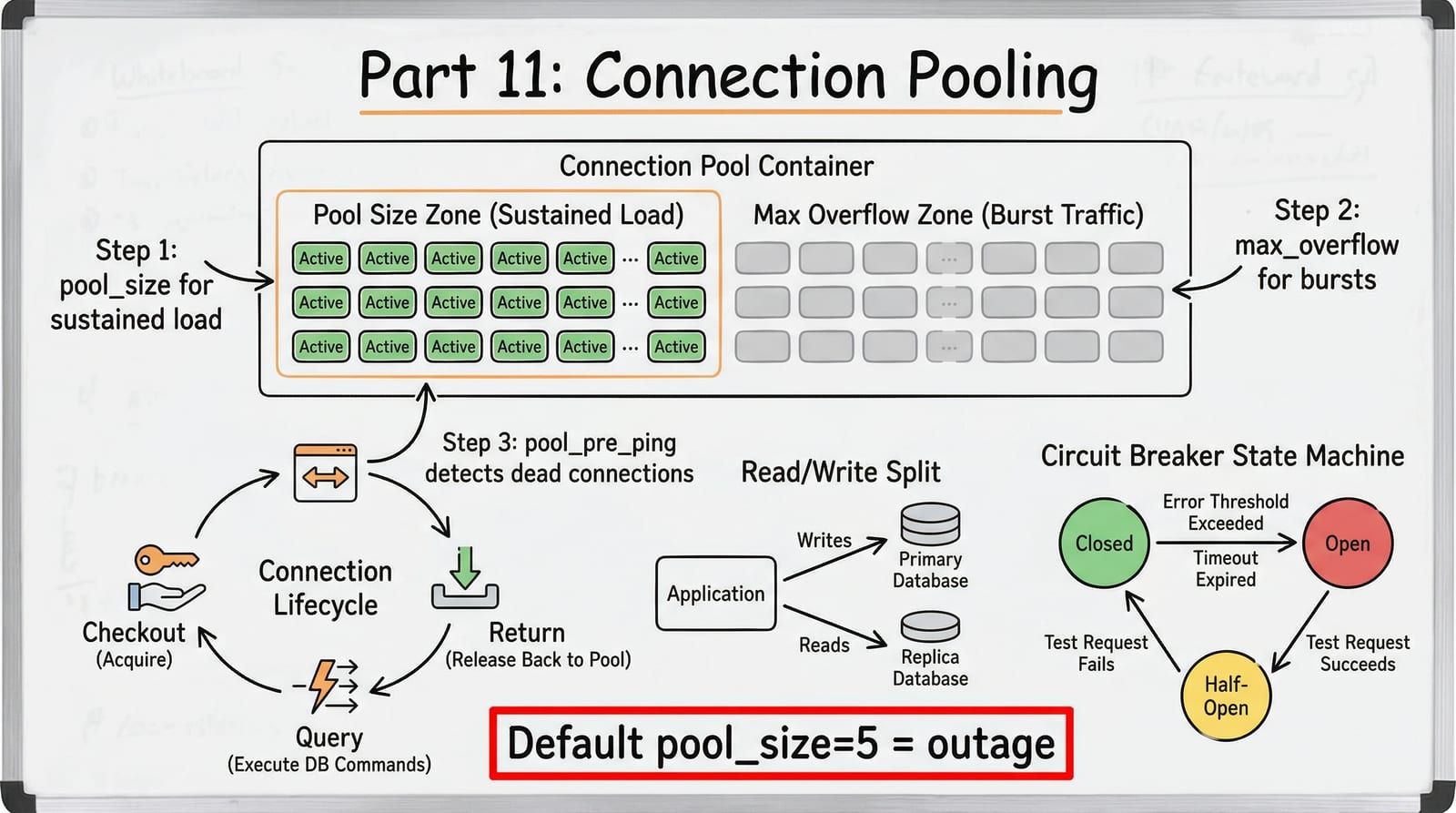
It is Black Friday. ShelfWise traffic spikes to 200 concurrent requests per instance. Your create_async_engine() call uses SQLAlchemy’s defaults: pool_size=5, max_overflow=10. That is 15 connections total. The other 185 coroutines are queued, waiting for a connection to become available. After 30 seconds, pool_timeout fires and they all get TimeoutError. Your load balancer sees 5xx responses, retries them, which adds more requests to the queue. Within 90 seconds, every instance is unresponsive.
This is pool exhaustion — the number one cause of production database failures in Python async applications. It is not a database problem. The database is fine. It is a connection pool problem, and it is entirely preventable with correct configuration.
The Connection Pool Lifecycle
Every database operation in an async SQLAlchemy application follows the same lifecycle:
%3bstroke:white%3bstroke-width:1.5%3b%7d%23mermaid-0 .end-state-inner%7bfill:white%3bstroke-width:1.5%3b%7d%23mermaid-0 .node rect%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 .node polygon%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 %5bid%24='-barbEnd'%5d%7bfill:%23666%3b%7d%23mermaid-0 .statediagram-cluster rect%7bfill:%23eee%3bstroke:black%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster-label%2c%23mermaid-0 .nodeLabel%7bcolor:%23111111%3b%7d%23mermaid-0 .statediagram-cluster rect.outer%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-state .divider%7bstroke:black%3b%7d%23mermaid-0 .statediagram-state .title-state%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-cluster.statediagram-cluster .inner%7bfill:white%3b%7d%23mermaid-0 .statediagram-cluster.statediagram-cluster-alt .inner%7bfill:%23f4f4f4%3b%7d%23mermaid-0 .statediagram-cluster .inner%7brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-state rect.basic%7brx:5px%3bry:5px%3b%7d%23mermaid-0 .statediagram-state rect.divider%7bstroke-dasharray:10%2c10%3bfill:%23f4f4f4%3b%7d%23mermaid-0 .note-edge%7bstroke-dasharray:5%3b%7d%23mermaid-0 .statediagram-note rect%7bfill:%23666%3bstroke:%23999%3bstroke-width:1px%3brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-note rect%7bfill:%23666%3bstroke:%23999%3bstroke-width:1px%3brx:0%3bry:0%3b%7d%23mermaid-0 .statediagram-note text%7bfill:white%3b%7d%23mermaid-0 .statediagram-note .nodeLabel%7bcolor:white%3b%7d%23mermaid-0 .statediagram .edgeLabel%7bcolor:red%3b%7d%23mermaid-0 %5bid%24='-dependencyStart'%5d%2c%23mermaid-0 %5bid%24='-dependencyEnd'%5d%7bfill:%23666%3bstroke:%23666%3bstroke-width:1%3b%7d%23mermaid-0 .statediagramTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.statediagram-cluster rect%7bfill:%23eee%3bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.statediagram-cluster rect.outer%7brx:5px%3bry:5px%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cdefs%3e%3cmarker id='mermaid-0_stateDiagram-barbEnd' refX='19' refY='7' markerWidth='20' markerHeight='14' markerUnits='userSpaceOnUse' orient='auto'%3e%3cpath d='M 19%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M552.637%2c22L552.637%2c28.167C552.637%2c34.333%2c552.637%2c46.667%2c552.637%2c59C552.637%2c71.333%2c552.637%2c83.667%2c552.637%2c89.833L552.637%2c96' id='mermaid-0-edge0' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge0' data-points='W3sieCI6NTUyLjYzNjcxODc1LCJ5IjoyMn0seyJ4Ijo1NTIuNjM2NzE4NzUsInkiOjU5fSx7IngiOjU1Mi42MzY3MTg3NSwieSI6OTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M531.738%2c119.839L483.504%2c128.699C435.27%2c137.559%2c338.801%2c155.28%2c303.146%2c170.306C267.491%2c185.333%2c292.651%2c197.667%2c305.231%2c203.833L317.81%2c210' id='mermaid-0-edge1' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge1' data-points='W3sieCI6NTMxLjczODI4MTI1LCJ5IjoxMTkuODM4ODQyODcxMTY5OTd9LHsieCI6MjQyLjMzMjAzMTI1LCJ5IjoxNzN9LHsieCI6MzE3LjgxMDMwNzAxNzU0MzksInkiOjIxMH1d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M327.642%2c250L318.093%2c256.167C308.545%2c262.333%2c289.448%2c274.667%2c289.793%2c287.223C290.138%2c299.779%2c309.924%2c312.558%2c319.818%2c318.947L329.711%2c325.336' id='mermaid-0-edge2' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge2' data-points='W3sieCI6MzI3LjY0MTcyMTQ5MTIyODA1LCJ5IjoyNTB9LHsieCI6MjcwLjM1MTU2MjUsInkiOjI4N30seyJ4IjozMjkuNzEwOTM3NSwieSI6MzI1LjMzNjM3MjQ4ODI3MTJ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M387.508%2c331.789L405.174%2c324.324C422.841%2c316.86%2c458.174%2c301.93%2c461.247%2c288.298C464.319%2c274.667%2c435.131%2c262.333%2c420.536%2c256.167L405.942%2c250' id='mermaid-0-edge3' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge3' data-points='W3sieCI6Mzg3LjUwNzgxMjUsInkiOjMzMS43ODkyNTExNzI3NTczfSx7IngiOjQ5My41MDc4MTI1LCJ5IjoyODd9LHsieCI6NDA1Ljk0MjE2MDA4NzcxOTMsInkiOjI1MH1d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M394.643%2c210L405.753%2c203.833C416.863%2c197.667%2c439.084%2c185.333%2c461.933%2c171.84C484.783%2c158.348%2c508.26%2c143.695%2c519.999%2c136.369L531.738%2c129.043' id='mermaid-0-edge4' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge4' data-points='W3sieCI6Mzk0LjY0MjgxNzk4MjQ1NjEsInkiOjIxMH0seyJ4Ijo0NjEuMzA0Njg3NSwieSI6MTczfSx7IngiOjUzMS43MzgyODEyNSwieSI6MTI5LjA0MjY0MTQ2MTAxNTM2fV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M531.738%2c118.632L459.79%2c127.693C387.841%2c136.755%2c243.944%2c154.877%2c171.995%2c173.439C100.047%2c192%2c100.047%2c211%2c100.047%2c230C100.047%2c249%2c100.047%2c268%2c100.047%2c287C100.047%2c306%2c100.047%2c325%2c100.047%2c344C100.047%2c363%2c100.047%2c382%2c114.018%2c397.954C127.988%2c413.908%2c155.93%2c426.816%2c169.9%2c433.27L183.871%2c439.724' id='mermaid-0-edge5' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge5' data-points='W3sieCI6NTMxLjczODI4MTI1LCJ5IjoxMTguNjMxOTg3Nzc4NjY5NjR9LHsieCI6MTAwLjA0Njg3NSwieSI6MTczfSx7IngiOjEwMC4wNDY4NzUsInkiOjIzMH0seyJ4IjoxMDAuMDQ2ODc1LCJ5IjoyODd9LHsieCI6MTAwLjA0Njg3NSwieSI6MzQ0fSx7IngiOjEwMC4wNDY4NzUsInkiOjQwMX0seyJ4IjoxODMuODcxMDkzNzUsInkiOjQzOS43MjM2MjA0NzY3Nzg0fV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M262.996%2c448.692L296.779%2c440.743C330.563%2c432.794%2c398.129%2c416.897%2c418.881%2c402.012C439.633%2c387.127%2c413.57%2c373.255%2c400.539%2c366.318L387.508%2c359.382' id='mermaid-0-edge6' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge6' data-points='W3sieCI6MjYyLjk5NjA5Mzc1LCJ5Ijo0NDguNjkxNjI2NzU5NTQxNH0seyJ4Ijo0NjUuNjk1MzEyNSwieSI6NDAxfSx7IngiOjM4Ny41MDc4MTI1LCJ5IjozNTkuMzgyMTQwNTEyMTQ3MX1d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M329.711%2c356.186L311.998%2c363.655C294.285%2c371.124%2c258.859%2c386.062%2c241.146%2c399.698C223.434%2c413.333%2c223.434%2c425.667%2c223.434%2c431.833L223.434%2c438' id='mermaid-0-edge7' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge7' data-points='W3sieCI6MzI5LjcxMDkzNzUsInkiOjM1Ni4xODU2OTU3MDg3MTI2fSx7IngiOjIyMy40MzM1OTM3NSwieSI6NDAxfSx7IngiOjIyMy40MzM1OTM3NSwieSI6NDM4fV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M223.434%2c478L223.434%2c486.167C223.434%2c494.333%2c223.434%2c510.667%2c299.188%2c529.374C374.943%2c548.082%2c526.452%2c569.164%2c602.206%2c579.705L677.961%2c590.246' id='mermaid-0-edge8' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge8' data-points='W3sieCI6MjIzLjQzMzU5Mzc1LCJ5Ijo0Nzh9LHsieCI6MjIzLjQzMzU5Mzc1LCJ5Ijo1Mjd9LHsieCI6Njc3Ljk2MDkzNzUsInkiOjU5MC4yNDYwNTkzMTcwMjcxfV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M573.535%2c129.043L585.274%2c136.369C597.013%2c143.695%2c620.491%2c158.348%2c640.381%2c171.84C660.271%2c185.333%2c676.574%2c197.667%2c684.725%2c203.833L692.876%2c210' id='mermaid-0-edge9' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge9' data-points='W3sieCI6NTczLjUzNTE1NjI1LCJ5IjoxMjkuMDQyNjQxNDYxMDE1MzZ9LHsieCI6NjQzLjk2ODc1LCJ5IjoxNzN9LHsieCI6NjkyLjg3NjA5NjQ5MTIyOCwieSI6MjEwfV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M745.749%2c210L753.9%2c203.833C762.051%2c197.667%2c778.354%2c185.333%2c749.652%2c170.487C720.949%2c155.641%2c647.242%2c138.281%2c610.389%2c129.602L573.535%2c120.922' id='mermaid-0-edge10' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge10' data-points='W3sieCI6NzQ1Ljc0ODkwMzUwODc3MiwieSI6MjEwfSx7IngiOjc5NC42NTYyNSwieSI6MTczfSx7IngiOjU3My41MzUxNTYyNSwieSI6MTIwLjkyMTk2MjAwNTkwNzMyfV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M719.313%2c250L719.313%2c256.167C719.313%2c262.333%2c719.313%2c274.667%2c719.313%2c290.333C719.313%2c306%2c719.313%2c325%2c719.313%2c344C719.313%2c363%2c719.313%2c382%2c719.313%2c401C719.313%2c420%2c719.313%2c439%2c719.313%2c460C719.313%2c481%2c719.313%2c504%2c719.313%2c523.667C719.313%2c543.333%2c719.313%2c559.667%2c719.313%2c567.833L719.313%2c576' id='mermaid-0-edge11' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge11' data-points='W3sieCI6NzE5LjMxMjUsInkiOjI1MH0seyJ4Ijo3MTkuMzEyNSwieSI6Mjg3fSx7IngiOjcxOS4zMTI1LCJ5IjozNDR9LHsieCI6NzE5LjMxMjUsInkiOjQwMX0seyJ4Ijo3MTkuMzEyNSwieSI6NDU4fSx7IngiOjcxOS4zMTI1LCJ5Ijo1Mjd9LHsieCI6NzE5LjMxMjUsInkiOjU3Nn1d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M573.535%2c119.51L626.62%2c128.425C679.704%2c137.34%2c785.874%2c155.17%2c838.958%2c173.585C892.043%2c192%2c892.043%2c211%2c892.043%2c230C892.043%2c249%2c892.043%2c268%2c892.043%2c287C892.043%2c306%2c892.043%2c325%2c892.043%2c344C892.043%2c363%2c892.043%2c382%2c892.043%2c397.667C892.043%2c413.333%2c892.043%2c425.667%2c892.043%2c431.833L892.043%2c438' id='mermaid-0-edge12' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge12' data-points='W3sieCI6NTczLjUzNTE1NjI1LCJ5IjoxMTkuNTA5NjkwNjM2MjIxMzR9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5IjoxNzN9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5IjoyMzB9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5IjoyODd9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5IjozNDR9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5Ijo0MDF9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5Ijo0Mzh9XQ==' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M892.043%2c478L892.043%2c486.167C892.043%2c494.333%2c892.043%2c510.667%2c870.146%2c527.58C848.25%2c544.494%2c804.457%2c561.988%2c782.561%2c570.735L760.664%2c579.481' id='mermaid-0-edge13' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge13' data-points='W3sieCI6ODkyLjA0Mjk2ODc1LCJ5Ijo0Nzh9LHsieCI6ODkyLjA0Mjk2ODc1LCJ5Ijo1Mjd9LHsieCI6NzYwLjY2NDA2MjUsInkiOjU3OS40ODE0NDQ2Mjc4NzQ5fV0=' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3cpath d='M719.313%2c616L719.313%2c620.167C719.313%2c624.333%2c719.313%2c632.667%2c719.313%2c640.999C719.313%2c649.331%2c719.313%2c657.662%2c719.313%2c661.828L719.313%2c665.993' id='mermaid-0-edge14' class='edge-thickness-normal edge-pattern-solid transition' style='fill:none%3b%3b%3bfill:none' data-edge='true' data-et='edge' data-id='edge14' data-points='W3sieCI6NzE5LjMxMjUsInkiOjYxNn0seyJ4Ijo3MTkuMzEyNSwieSI6NjQxfSx7IngiOjcxOS4zMTI1LCJ5Ijo2NjUuOTkzMzUzMzY2ODUxOH1d' data-look='classic' marker-end='url(%23mermaid-0_stateDiagram-barbEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(552.63671875%2c 59)'%3e%3cg class='label' data-id='edge0' transform='translate(-53.8203125%2c -12)'%3e%3cforeignObject width='107.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eEngine created%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(345.69713%2c 154.01282)'%3e%3cg class='label' data-id='edge1' transform='translate(-94.265625%2c -12)'%3e%3cforeignObject width='188.53125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3esession.execute() / begin()%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(270.3515625%2c 287)'%3e%3cg class='label' data-id='edge2' transform='translate(-58.2578125%2c -12)'%3e%3cforeignObject width='116.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eQuery executing%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(484.29064%2c 290.89463)'%3e%3cg class='label' data-id='edge3' transform='translate(-98.2578125%2c -12)'%3e%3cforeignObject width='196.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eQuery complete%2c more work%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(464.18192%2c 171.20433)'%3e%3cg class='label' data-id='edge4' transform='translate(-91.125%2c -12)'%3e%3cforeignObject width='182.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3esession.close() / commit()%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(100.046875%2c 287)'%3e%3cg class='label' data-id='edge5' transform='translate(-92.046875%2c -12)'%3e%3cforeignObject width='184.09375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3ePool full%2c overflow allowed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(465.6953125%2c 401)'%3e%3cg class='label' data-id='edge6' transform='translate(-58.2578125%2c -12)'%3e%3cforeignObject width='116.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eQuery executing%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(223.43359375%2c 401)'%3e%3cg class='label' data-id='edge7' transform='translate(-56.46875%2c -12)'%3e%3cforeignObject width='112.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eQuery complete%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(223.43359375%2c 527)'%3e%3cg class='label' data-id='edge8' transform='translate(-100%2c -24)'%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eConnection returned%2c overflow shrinks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(634.76486%2c 167.25588)'%3e%3cg class='label' data-id='edge9' transform='translate(-71.5390625%2c -12)'%3e%3cforeignObject width='143.078125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3epool_pre_ping=True%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(713.9423%2c 153.9904)'%3e%3cg class='label' data-id='edge10' transform='translate(-59.1484375%2c -12)'%3e%3cforeignObject width='118.296875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eConnection alive%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(719.3125%2c 401)'%3e%3cg class='label' data-id='edge11' transform='translate(-95.625%2c -12)'%3e%3cforeignObject width='191.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eConnection dead%2c replaced%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(892.04296875%2c 287)'%3e%3cg class='label' data-id='edge12' transform='translate(-73.375%2c -12)'%3e%3cforeignObject width='146.75' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3epool_recycle timeout%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(892.04296875%2c 527)'%3e%3cg class='label' data-id='edge13' transform='translate(-84.953125%2c -12)'%3e%3cforeignObject width='169.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eOld connection dropped%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='edge14' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-state-root_start-0' data-look='classic' transform='translate(552.63671875%2c 15)'%3e%3ccircle class='state-start' r='7' width='14' height='14'/%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Idle-12' data-look='classic' transform='translate(552.63671875%2c 116)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-20.8984375' y='-20' width='41.796875' height='40'/%3e%3cg class='label' style='' transform='translate(-12.8984375%2c -12)'%3e%3crect/%3e%3cforeignObject width='25.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eIdle%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-CheckedOut-4' data-look='classic' transform='translate(358.609375%2c 230)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-52.46875' y='-20' width='104.9375' height='40'/%3e%3cg class='label' style='' transform='translate(-44.46875%2c -12)'%3e%3crect/%3e%3cforeignObject width='88.9375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eCheckedOut%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-InUse-7' data-look='classic' transform='translate(358.609375%2c 344)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-28.8984375' y='-20' width='57.796875' height='40'/%3e%3cg class='label' style='' transform='translate(-20.8984375%2c -12)'%3e%3crect/%3e%3cforeignObject width='41.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eInUse%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Overflow-8' data-look='classic' transform='translate(223.43359375%2c 458)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-39.5625' y='-20' width='79.125' height='40'/%3e%3cg class='label' style='' transform='translate(-31.5625%2c -12)'%3e%3crect/%3e%3cforeignObject width='63.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eOverflow%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Disposed-14' data-look='classic' transform='translate(719.3125%2c 596)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-41.3515625' y='-20' width='82.703125' height='40'/%3e%3cg class='label' style='' transform='translate(-33.3515625%2c -12)'%3e%3crect/%3e%3cforeignObject width='66.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eDisposed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-PrePing-11' data-look='classic' transform='translate(719.3125%2c 230)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-36.4609375' y='-20' width='72.921875' height='40'/%3e%3cg class='label' style='' transform='translate(-28.4609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='56.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3ePrePing%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node statediagram-state' id='mermaid-0-state-Recycled-13' data-look='classic' transform='translate(892.04296875%2c 458)'%3e%3crect class='basic label-container' style='' rx='5' ry='5' x='-40.90625' y='-20' width='81.8125' height='40'/%3e%3cg class='label' style='' transform='translate(-32.90625%2c -12)'%3e%3crect/%3e%3cforeignObject width='65.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel markdown-node-label'%3e%3cp%3eRecycled%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-state-root_end-14' data-look='classic' transform='translate(719.3125%2c 673)'%3e%3cg class='outer-path'%3e%3cpath d='M7 0 C7 0.40517908122283747%2c 6.964012880168563 0.816513743121899%2c 6.893654271085456 1.2155372436685123 C6.823295662002349 1.6145607442151257%2c 6.716427752933756 2.013397210557766%2c 6.5778483455013586 2.394141003279681 C6.439268938068961 2.7748847960015954%2c 6.26476736710249 3.149104622578984%2c 6.062177826491071 3.4999999999999996 C5.859588285879653 3.8508953774210153%2c 5.622755194947063 4.189128084166967%2c 5.362311101832846 4.499513267805774 C5.10186700871863 4.809898451444582%2c 4.809898451444583 5.10186700871863%2c 4.499513267805775 5.362311101832846 C4.189128084166968 5.622755194947063%2c 3.8508953774210166 5.859588285879652%2c 3.500000000000001 6.06217782649107 C3.149104622578985 6.264767367102489%2c 2.7748847960015963 6.439268938068961%2c 2.3941410032796817 6.5778483455013586 C2.013397210557767 6.716427752933756%2c 1.6145607442151264 6.823295662002349%2c 1.2155372436685128 6.893654271085456 C0.8165137431218992 6.964012880168563%2c 0.4051790812228379 7%2c 4.286263797015736e-16 7 C-0.405179081222837 7%2c -0.8165137431218985 6.964012880168563%2c -1.2155372436685121 6.893654271085456 C-1.6145607442151257 6.823295662002349%2c -2.0133972105577667 6.716427752933756%2c -2.394141003279681 6.5778483455013586 C-2.774884796001595 6.439268938068961%2c -3.149104622578983 6.26476736710249%2c -3.4999999999999982 6.062177826491071 C-3.8508953774210135 5.859588285879653%2c -4.189128084166966 5.6227551949470636%2c -4.499513267805773 5.362311101832848 C-4.809898451444581 5.101867008718632%2c -5.101867008718628 4.809898451444586%2c -5.3623111018328435 4.499513267805779 C-5.622755194947059 4.189128084166971%2c -5.859588285879649 3.8508953774210206%2c -6.062177826491068 3.5000000000000053 C-6.264767367102486 3.14910462257899%2c -6.439268938068958 2.774884796001602%2c -6.577848345501356 2.394141003279688 C-6.716427752933754 2.0133972105577738%2c -6.823295662002347 1.614560744215134%2c -6.893654271085454 1.215537243668521 C-6.9640128801685615 0.816513743121908%2c -6.999999999999999 0.4051790812228472%2c -7 1.0183126166254463e-14 C-7.000000000000001 -0.40517908122282686%2c -6.964012880168565 -0.8165137431218878%2c -6.893654271085459 -1.215537243668501 C-6.823295662002352 -1.6145607442151142%2c -6.716427752933759 -2.0133972105577542%2c -6.577848345501363 -2.394141003279669 C-6.439268938068967 -2.7748847960015834%2c -6.264767367102496 -3.149104622578972%2c -6.062177826491078 -3.4999999999999876 C-5.859588285879661 -3.8508953774210033%2c -5.6227551949470715 -4.1891280841669545%2c -5.362311101832856 -4.499513267805763 C-5.10186700871864 -4.809898451444571%2c -4.809898451444594 -5.10186700871862%2c -4.499513267805787 -5.362311101832836 C-4.189128084166979 -5.622755194947053%2c -3.850895377421028 -5.859588285879643%2c -3.5000000000000133 -6.062177826491062 C-3.1491046225789985 -6.264767367102482%2c -2.774884796001611 -6.439268938068954%2c -2.3941410032796973 -6.577848345501353 C-2.0133972105577835 -6.716427752933752%2c -1.6145607442151435 -6.823295662002345%2c -1.2155372436685306 -6.893654271085453 C-0.8165137431219176 -6.9640128801685615%2c -0.40517908122285695 -6.999999999999999%2c -1.9937625952807352e-14 -7 C0.4051790812228171 -7.000000000000001%2c 0.8165137431218781 -6.964012880168565%2c 1.2155372436684913 -6.89365427108546 C1.6145607442151044 -6.823295662002354%2c 2.013397210557745 -6.716427752933763%2c 2.3941410032796595 -6.5778483455013665 C2.774884796001574 -6.43926893806897%2c 3.149104622578963 -6.2647673671025%2c 3.499999999999979 -6.062177826491083 C3.8508953774209953 -5.859588285879665%2c 4.189128084166947 -5.622755194947077%2c 4.499513267805756 -5.362311101832862 C4.809898451444564 -5.1018670087186475%2c 5.101867008718613 -4.809898451444602%2c 5.362311101832829 -4.499513267805796 C5.622755194947046 -4.189128084166989%2c 5.859588285879637 -3.8508953774210393%2c 6.062177826491056 -3.500000000000025 C6.2647673671024755 -3.1491046225790105%2c 6.439268938068949 -2.774884796001623%2c 6.577848345501348 -2.3941410032797092 C6.716427752933747 -2.0133972105577955%2c 6.823295662002342 -1.6145607442151562%2c 6.893654271085451 -1.2155372436685434 C6.96401288016856 -0.8165137431219307%2c 6.982275711847575 -0.2025895406114567%2c 7 -3.2800750208310675e-14 C7.017724288152425 0.2025895406113911%2c 7.017724288152424 -0.2025895406114242%2c 7 0' stroke='none' stroke-width='0' fill='%23eee' style=''/%3e%3cpath d='M7 0 C7 0.40517908122283747%2c 6.964012880168563 0.816513743121899%2c 6.893654271085456 1.2155372436685123 C6.823295662002349 1.6145607442151257%2c 6.716427752933756 2.013397210557766%2c 6.5778483455013586 2.394141003279681 C6.439268938068961 2.7748847960015954%2c 6.26476736710249 3.149104622578984%2c 6.062177826491071 3.4999999999999996 C5.859588285879653 3.8508953774210153%2c 5.622755194947063 4.189128084166967%2c 5.362311101832846 4.499513267805774 C5.10186700871863 4.809898451444582%2c 4.809898451444583 5.10186700871863%2c 4.499513267805775 5.362311101832846 C4.189128084166968 5.622755194947063%2c 3.8508953774210166 5.859588285879652%2c 3.500000000000001 6.06217782649107 C3.149104622578985 6.264767367102489%2c 2.7748847960015963 6.439268938068961%2c 2.3941410032796817 6.5778483455013586 C2.013397210557767 6.716427752933756%2c 1.6145607442151264 6.823295662002349%2c 1.2155372436685128 6.893654271085456 C0.8165137431218992 6.964012880168563%2c 0.4051790812228379 7%2c 4.286263797015736e-16 7 C-0.405179081222837 7%2c -0.8165137431218985 6.964012880168563%2c -1.2155372436685121 6.893654271085456 C-1.6145607442151257 6.823295662002349%2c -2.0133972105577667 6.716427752933756%2c -2.394141003279681 6.5778483455013586 C-2.774884796001595 6.439268938068961%2c -3.149104622578983 6.26476736710249%2c -3.4999999999999982 6.062177826491071 C-3.8508953774210135 5.859588285879653%2c -4.189128084166966 5.6227551949470636%2c -4.499513267805773 5.362311101832848 C-4.809898451444581 5.101867008718632%2c -5.101867008718628 4.809898451444586%2c -5.3623111018328435 4.499513267805779 C-5.622755194947059 4.189128084166971%2c -5.859588285879649 3.8508953774210206%2c -6.062177826491068 3.5000000000000053 C-6.264767367102486 3.14910462257899%2c -6.439268938068958 2.774884796001602%2c -6.577848345501356 2.394141003279688 C-6.716427752933754 2.0133972105577738%2c -6.823295662002347 1.614560744215134%2c -6.893654271085454 1.215537243668521 C-6.9640128801685615 0.816513743121908%2c -6.999999999999999 0.4051790812228472%2c -7 1.0183126166254463e-14 C-7.000000000000001 -0.40517908122282686%2c -6.964012880168565 -0.8165137431218878%2c -6.893654271085459 -1.215537243668501 C-6.823295662002352 -1.6145607442151142%2c -6.716427752933759 -2.0133972105577542%2c -6.577848345501363 -2.394141003279669 C-6.439268938068967 -2.7748847960015834%2c -6.264767367102496 -3.149104622578972%2c -6.062177826491078 -3.4999999999999876 C-5.859588285879661 -3.8508953774210033%2c -5.6227551949470715 -4.1891280841669545%2c -5.362311101832856 -4.499513267805763 C-5.10186700871864 -4.809898451444571%2c -4.809898451444594 -5.10186700871862%2c -4.499513267805787 -5.362311101832836 C-4.189128084166979 -5.622755194947053%2c -3.850895377421028 -5.859588285879643%2c -3.5000000000000133 -6.062177826491062 C-3.1491046225789985 -6.264767367102482%2c -2.774884796001611 -6.439268938068954%2c -2.3941410032796973 -6.577848345501353 C-2.0133972105577835 -6.716427752933752%2c -1.6145607442151435 -6.823295662002345%2c -1.2155372436685306 -6.893654271085453 C-0.8165137431219176 -6.9640128801685615%2c -0.40517908122285695 -6.999999999999999%2c -1.9937625952807352e-14 -7 C0.4051790812228171 -7.000000000000001%2c 0.8165137431218781 -6.964012880168565%2c 1.2155372436684913 -6.89365427108546 C1.6145607442151044 -6.823295662002354%2c 2.013397210557745 -6.716427752933763%2c 2.3941410032796595 -6.5778483455013665 C2.774884796001574 -6.43926893806897%2c 3.149104622578963 -6.2647673671025%2c 3.499999999999979 -6.062177826491083 C3.8508953774209953 -5.859588285879665%2c 4.189128084166947 -5.622755194947077%2c 4.499513267805756 -5.362311101832862 C4.809898451444564 -5.1018670087186475%2c 5.101867008718613 -4.809898451444602%2c 5.362311101832829 -4.499513267805796 C5.622755194947046 -4.189128084166989%2c 5.859588285879637 -3.8508953774210393%2c 6.062177826491056 -3.500000000000025 C6.2647673671024755 -3.1491046225790105%2c 6.439268938068949 -2.774884796001623%2c 6.577848345501348 -2.3941410032797092 C6.716427752933747 -2.0133972105577955%2c 6.823295662002342 -1.6145607442151562%2c 6.893654271085451 -1.2155372436685434 C6.96401288016856 -0.8165137431219307%2c 6.982275711847575 -0.2025895406114567%2c 7 -3.2800750208310675e-14 C7.017724288152425 0.2025895406113911%2c 7.017724288152424 -0.2025895406114242%2c 7 0' stroke='%23666' stroke-width='2' fill='none' stroke-dasharray='0 0' style=''/%3e%3cg%3e%3cpath d='M2.5 0 C2.5 0.14470681472244193%2c 2.487147457203058 0.29161205111496386%2c 2.46201938253052 0.4341204441673258 C2.436891307857982 0.5766288372196877%2c 2.3987241974763416 0.7190704323420595%2c 2.3492315519647713 0.8550503583141718 C2.299738906453201 0.991030284286284%2c 2.2374169168223177 1.124680222349637%2c 2.165063509461097 1.2499999999999998 C2.092710102099876 1.3753197776503625%2c 2.0081268553382365 1.496117172916774%2c 1.915111107797445 1.6069690242163481 C1.8220953602566536 1.7178208755159223%2c 1.7178208755159226 1.8220953602566536%2c 1.6069690242163484 1.915111107797445 C1.4961171729167742 2.0081268553382365%2c 1.375319777650363 2.0927101020998755%2c 1.2500000000000002 2.1650635094610964 C1.1246802223496375 2.2374169168223172%2c 0.9910302842862845 2.2997389064532%2c 0.8550503583141721 2.349231551964771 C0.7190704323420597 2.3987241974763416%2c 0.576628837219688 2.436891307857982%2c 0.43412044416732604 2.46201938253052 C0.291612051114964 2.487147457203058%2c 0.14470681472244212 2.5%2c 1.5308084989341916e-16 2.5 C-0.1447068147224418 2.5%2c -0.2916120511149638 2.487147457203058%2c -0.43412044416732576 2.46201938253052 C-0.5766288372196877 2.436891307857982%2c -0.7190704323420595 2.3987241974763416%2c -0.8550503583141718 2.3492315519647713 C-0.991030284286284 2.299738906453201%2c -1.124680222349637 2.2374169168223177%2c -1.2499999999999996 2.165063509461097 C-1.375319777650362 2.092710102099876%2c -1.4961171729167733 2.008126855338237%2c -1.6069690242163475 1.9151111077974459 C-1.7178208755159217 1.8220953602566548%2c -1.822095360256653 1.7178208755159234%2c -1.9151111077974443 1.6069690242163495 C-2.0081268553382357 1.4961171729167755%2c -2.0927101020998746 1.3753197776503645%2c -2.1650635094610955 1.250000000000002 C-2.2374169168223164 1.1246802223496395%2c -2.2997389064531992 0.9910302842862865%2c -2.34923155196477 0.8550503583141743 C-2.3987241974763407 0.7190704323420621%2c -2.436891307857981 0.5766288372196907%2c -2.4620193825305194 0.434120444167329 C-2.487147457203058 0.29161205111496724%2c -2.5 0.14470681472244545%2c -2.5 3.636830773662308e-15 C-2.5 -0.14470681472243818%2c -2.4871474572030587 -0.2916120511149599%2c -2.4620193825305208 -0.4341204441673218 C-2.436891307857983 -0.5766288372196837%2c -2.398724197476343 -0.7190704323420553%2c -2.3492315519647726 -0.8550503583141675 C-2.2997389064532023 -0.9910302842862798%2c -2.23741691682232 -1.1246802223496328%2c -2.165063509461099 -1.2499999999999956 C-2.092710102099878 -1.3753197776503583%2c -2.00812685533824 -1.4961171729167695%2c -1.9151111077974488 -1.606969024216344 C-1.8220953602566576 -1.7178208755159183%2c -1.7178208755159263 -1.82209536025665%2c -1.6069690242163523 -1.9151111077974416 C-1.4961171729167784 -2.0081268553382334%2c -1.3753197776503672 -2.0927101020998724%2c -1.2500000000000047 -2.1650635094610937 C-1.1246802223496422 -2.237416916822315%2c -0.9910302842862897 -2.299738906453198%2c -0.8550503583141776 -2.3492315519647686 C-0.7190704323420656 -2.3987241974763394%2c -0.5766288372196942 -2.4368913078579806%2c -0.43412044416733236 -2.462019382530519 C-0.29161205111497057 -2.4871474572030574%2c -0.1447068147224489 -2.4999999999999996%2c -7.120580697431198e-15 -2.5 C0.14470681472243463 -2.5000000000000004%2c 0.29161205111495647 -2.487147457203059%2c 0.4341204441673183 -2.4620193825305217 C0.5766288372196802 -2.436891307857984%2c 0.7190704323420518 -2.3987241974763442%2c 0.8550503583141642 -2.349231551964774 C0.9910302842862766 -2.2997389064532037%2c 1.1246802223496295 -2.2374169168223212%2c 1.2499999999999925 -2.165063509461101 C1.3753197776503554 -2.0927101020998804%2c 1.4961171729167668 -2.008126855338242%2c 1.6069690242163412 -1.915111107797451 C1.7178208755159157 -1.82209536025666%2c 1.8220953602566472 -1.7178208755159294%2c 1.915111107797439 -1.6069690242163557 C2.0081268553382308 -1.496117172916782%2c 2.09271010209987 -1.3753197776503712%2c 2.1650635094610915 -1.2500000000000089 C2.237416916822313 -1.1246802223496466%2c 2.299738906453196 -0.9910302842862939%2c 2.3492315519647673 -0.855050358314182 C2.3987241974763385 -0.71907043234207%2c 2.4368913078579792 -0.5766288372196986%2c 2.462019382530518 -0.4341204441673369 C2.487147457203057 -0.29161205111497523%2c 2.4936698970884197 -0.07235340736123454%2c 2.5 -1.1714553645825241e-14 C2.5063301029115803 0.07235340736121111%2c 2.50633010291158 -0.07235340736122292%2c 2.5 0' stroke='none' stroke-width='0' fill='black' style=''/%3e%3cpath d='M2.5 0 C2.5 0.14470681472244193%2c 2.487147457203058 0.29161205111496386%2c 2.46201938253052 0.4341204441673258 C2.436891307857982 0.5766288372196877%2c 2.3987241974763416 0.7190704323420595%2c 2.3492315519647713 0.8550503583141718 C2.299738906453201 0.991030284286284%2c 2.2374169168223177 1.124680222349637%2c 2.165063509461097 1.2499999999999998 C2.092710102099876 1.3753197776503625%2c 2.0081268553382365 1.496117172916774%2c 1.915111107797445 1.6069690242163481 C1.8220953602566536 1.7178208755159223%2c 1.7178208755159226 1.8220953602566536%2c 1.6069690242163484 1.915111107797445 C1.4961171729167742 2.0081268553382365%2c 1.375319777650363 2.0927101020998755%2c 1.2500000000000002 2.1650635094610964 C1.1246802223496375 2.2374169168223172%2c 0.9910302842862845 2.2997389064532%2c 0.8550503583141721 2.349231551964771 C0.7190704323420597 2.3987241974763416%2c 0.576628837219688 2.436891307857982%2c 0.43412044416732604 2.46201938253052 C0.291612051114964 2.487147457203058%2c 0.14470681472244212 2.5%2c 1.5308084989341916e-16 2.5 C-0.1447068147224418 2.5%2c -0.2916120511149638 2.487147457203058%2c -0.43412044416732576 2.46201938253052 C-0.5766288372196877 2.436891307857982%2c -0.7190704323420595 2.3987241974763416%2c -0.8550503583141718 2.3492315519647713 C-0.991030284286284 2.299738906453201%2c -1.124680222349637 2.2374169168223177%2c -1.2499999999999996 2.165063509461097 C-1.375319777650362 2.092710102099876%2c -1.4961171729167733 2.008126855338237%2c -1.6069690242163475 1.9151111077974459 C-1.7178208755159217 1.8220953602566548%2c -1.822095360256653 1.7178208755159234%2c -1.9151111077974443 1.6069690242163495 C-2.0081268553382357 1.4961171729167755%2c -2.0927101020998746 1.3753197776503645%2c -2.1650635094610955 1.250000000000002 C-2.2374169168223164 1.1246802223496395%2c -2.2997389064531992 0.9910302842862865%2c -2.34923155196477 0.8550503583141743 C-2.3987241974763407 0.7190704323420621%2c -2.436891307857981 0.5766288372196907%2c -2.4620193825305194 0.434120444167329 C-2.487147457203058 0.29161205111496724%2c -2.5 0.14470681472244545%2c -2.5 3.636830773662308e-15 C-2.5 -0.14470681472243818%2c -2.4871474572030587 -0.2916120511149599%2c -2.4620193825305208 -0.4341204441673218 C-2.436891307857983 -0.5766288372196837%2c -2.398724197476343 -0.7190704323420553%2c -2.3492315519647726 -0.8550503583141675 C-2.2997389064532023 -0.9910302842862798%2c -2.23741691682232 -1.1246802223496328%2c -2.165063509461099 -1.2499999999999956 C-2.092710102099878 -1.3753197776503583%2c -2.00812685533824 -1.4961171729167695%2c -1.9151111077974488 -1.606969024216344 C-1.8220953602566576 -1.7178208755159183%2c -1.7178208755159263 -1.82209536025665%2c -1.6069690242163523 -1.9151111077974416 C-1.4961171729167784 -2.0081268553382334%2c -1.3753197776503672 -2.0927101020998724%2c -1.2500000000000047 -2.1650635094610937 C-1.1246802223496422 -2.237416916822315%2c -0.9910302842862897 -2.299738906453198%2c -0.8550503583141776 -2.3492315519647686 C-0.7190704323420656 -2.3987241974763394%2c -0.5766288372196942 -2.4368913078579806%2c -0.43412044416733236 -2.462019382530519 C-0.29161205111497057 -2.4871474572030574%2c -0.1447068147224489 -2.4999999999999996%2c -7.120580697431198e-15 -2.5 C0.14470681472243463 -2.5000000000000004%2c 0.29161205111495647 -2.487147457203059%2c 0.4341204441673183 -2.4620193825305217 C0.5766288372196802 -2.436891307857984%2c 0.7190704323420518 -2.3987241974763442%2c 0.8550503583141642 -2.349231551964774 C0.9910302842862766 -2.2997389064532037%2c 1.1246802223496295 -2.2374169168223212%2c 1.2499999999999925 -2.165063509461101 C1.3753197776503554 -2.0927101020998804%2c 1.4961171729167668 -2.008126855338242%2c 1.6069690242163412 -1.915111107797451 C1.7178208755159157 -1.82209536025666%2c 1.8220953602566472 -1.7178208755159294%2c 1.915111107797439 -1.6069690242163557 C2.0081268553382308 -1.496117172916782%2c 2.09271010209987 -1.3753197776503712%2c 2.1650635094610915 -1.2500000000000089 C2.237416916822313 -1.1246802223496466%2c 2.299738906453196 -0.9910302842862939%2c 2.3492315519647673 -0.855050358314182 C2.3987241974763385 -0.71907043234207%2c 2.4368913078579792 -0.5766288372196986%2c 2.462019382530518 -0.4341204441673369 C2.487147457203057 -0.29161205111497523%2c 2.4936698970884197 -0.07235340736123454%2c 2.5 -1.1714553645825241e-14 C2.5063301029115803 0.07235340736121111%2c 2.50633010291158 -0.07235340736122292%2c 2.5 0' stroke='black' stroke-width='2' fill='none' stroke-dasharray='0 0' style=''/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
The pool maintains a set of persistent connections (pool_size). When all persistent connections are in use, it creates temporary overflow connections up to max_overflow. When overflow connections are returned, they are disposed — not kept in the pool. If both the pool and overflow are exhausted, the next checkout blocks until pool_timeout expires.
Production Engine Configuration
Here is the create_async_engine configuration for ShelfWise, with every parameter justified:
from sqlalchemy.ext.asyncio import create_async_engine, AsyncEngine
from src.core.config import settings
def create_engine() -> AsyncEngine: """Create the primary async engine with production pool settings.""" return create_async_engine( settings.database.url.get_secret_value(),
# ── Pool sizing ────────────────────────────────────────── pool_size=20, # Persistent connections kept open max_overflow=30, # Temporary connections under burst # Total max: 20 + 30 = 50 connections # Rule of thumb: 1 connection handles ~1 concurrent query # 50 connections ≈ 50 concurrent database operations per instance
# ── Timeouts ───────────────────────────────────────────── pool_timeout=10, # Seconds to wait for a connection before raising # Default is 30 — too long. A user waiting 30s has already left. # 10s is enough for burst absorption without hiding pool exhaustion.
# ── Connection health ──────────────────────────────────── pool_pre_ping=True, # SELECT 1 before every checkout # Adds ~1ms latency per checkout. Worth it. # Without it, a connection dropped by the database (idle timeout, # failover, network blip) causes a hard error on the NEXT query. # With it, the dead connection is silently replaced.
# ── Connection recycling ───────────────────────────────── pool_recycle=1800, # Replace connections older than 30 minutes # PostgreSQL and PgBouncer have idle connection timeouts. # Recycling before those timeouts prevents "connection reset" errors. # Also prevents long-lived connections from accumulating memory.
# ── Diagnostics ────────────────────────────────────────── echo=settings.database.echo, # SQL logging (off in prod) echo_pool="debug" if settings.debug else False, )| Traffic Level | pool_size | max_overflow | pool_timeout | Handles (concurrent) |
|---|---|---|---|---|
| Dev / staging | 5 | 5 | 30 | ~10 requests |
| Low traffic (< 50 RPS) | 10 | 10 | 15 | ~20 requests |
| Medium traffic (50-200 RPS) | 20 | 30 | 10 | ~50 requests |
| High traffic (200-1000 RPS) | 30 | 50 | 5 | ~80 requests |
| Extreme (1000+ RPS) | Use PgBouncer | Pool in PgBouncer | 3 | Thousands |
The numbers follow a formula: pool_size + max_overflow should be less than your PostgreSQL max_connections divided by the number of application instances. If PostgreSQL allows 200 connections and you run 4 instances, each instance gets at most 50 connections — so pool_size=20, max_overflow=30 is the ceiling.
Request-Scoped Session Lifecycle
Every request gets its own session. The session is created at the start of the request, used for all database operations during that request, and closed when the request ends. This is not optional — sharing sessions across requests is a race condition.
from collections.abc import AsyncIterator
from sqlalchemy.ext.asyncio import ( AsyncSession, async_sessionmaker,)
from src.db.engine import create_engine
engine = create_engine()AsyncSessionLocal = async_sessionmaker( engine, class_=AsyncSession, expire_on_commit=False, # Prevent lazy loads after commit)
async def get_session() -> AsyncIterator[AsyncSession]: """FastAPI dependency that provides a request-scoped session.
The session is committed on success, rolled back on exception, and always closed — guaranteeing the connection returns to the pool. """ async with AsyncSessionLocal() as session: try: yield session await session.commit() except Exception: await session.rollback() raiseThe FastAPI dependency wires it into route handlers:
from typing import Annotated
from fastapi import Dependsfrom sqlalchemy.ext.asyncio import AsyncSession
from src.db.session import get_session
SessionDep = Annotated[AsyncSession, Depends(get_session)]from src.api.deps import SessionDep
@router.get("/books/{book_id}")async def get_book(book_id: int, session: SessionDep): # session is created for this request, closed after response result = await session.execute( select(Book).where(Book.id == book_id) ) return result.scalar_one_or_none()The critical guarantee: the async with AsyncSessionLocal() as session block ensures the session is closed even if the route handler raises an exception. A closed session returns its connection to the pool. If sessions leak (not closed), connections leak, and pool exhaustion follows.
Read/Write Splitting
ShelfWise’s read traffic outweighs writes 10:1. Catalog browsing, search results, book detail pages — all reads. Writes happen on order placement, inventory updates, and admin operations. Sending all traffic to a single primary database wastes the read replicas you are paying for.
# src/db/engine.py (extended)from sqlalchemy.ext.asyncio import create_async_engine, AsyncEngine
from src.core.config import settings
def create_primary_engine() -> AsyncEngine: """Engine for write operations — connects to the primary.""" return create_async_engine( settings.database.primary_url.get_secret_value(), pool_size=10, max_overflow=15, pool_timeout=10, pool_pre_ping=True, pool_recycle=1800, )
def create_replica_engine() -> AsyncEngine: """Engine for read operations — connects to a read replica.
Larger pool because reads dominate traffic. Shorter recycle because replicas may rotate during maintenance. """ return create_async_engine( settings.database.replica_url.get_secret_value(), pool_size=25, max_overflow=40, pool_timeout=10, pool_pre_ping=True, pool_recycle=900, # 15 minutes — replicas rotate more often )The session factory routes reads and writes to different engines:
# src/db/session.py (extended)from collections.abc import AsyncIterator
from sqlalchemy.ext.asyncio import AsyncSession, async_sessionmaker
from src.db.engine import create_primary_engine, create_replica_engine
primary_engine = create_primary_engine()replica_engine = create_replica_engine()
PrimarySession = async_sessionmaker(primary_engine, class_=AsyncSession, expire_on_commit=False)ReplicaSession = async_sessionmaker(replica_engine, class_=AsyncSession, expire_on_commit=False)
async def get_write_session() -> AsyncIterator[AsyncSession]: """Session routed to the primary database (reads + writes).""" async with PrimarySession() as session: try: yield session await session.commit() except Exception: await session.rollback() raise
async def get_read_session() -> AsyncIterator[AsyncSession]: """Session routed to the read replica (reads only).
Do NOT use this session for writes — they will either fail (read-only replica) or create split-brain inconsistency. """ async with ReplicaSession() as session: yield session # No commit — reads do not need itRoute handlers declare their intent:
# Read endpoint — routed to replica@router.get("/books/")async def list_books( session: Annotated[AsyncSession, Depends(get_read_session)],): result = await session.execute(select(Book).limit(50)) return result.scalars().all()
# Write endpoint — routed to primary@router.post("/books/")async def create_book( data: BookCreate, session: Annotated[AsyncSession, Depends(get_write_session)],): book = Book(**data.model_dump()) session.add(book) await session.flush() return bookCircuit Breaker on the Connection Pool
When the database goes down, every request tries to connect, waits for pool_timeout, and fails. Meanwhile, the application is accumulating requests in the queue, consuming memory, and providing no useful service. A circuit breaker detects the failure pattern and fails fast — immediately returning an error without attempting a connection.
import asyncioimport timeimport loggingfrom enum import StrEnumfrom collections.abc import AsyncIteratorfrom contextlib import asynccontextmanager
from sqlalchemy.ext.asyncio import AsyncSession
logger = logging.getLogger("shelfwise.db")
class CircuitState(StrEnum): CLOSED = "closed" # Normal operation — requests flow through OPEN = "open" # Failing — reject immediately HALF_OPEN = "half_open" # Testing — allow one request through
class DatabaseCircuitBreaker: """Circuit breaker for database connections.
Transitions: - CLOSED → OPEN: after `failure_threshold` consecutive failures - OPEN → HALF_OPEN: after `recovery_timeout` seconds - HALF_OPEN → CLOSED: on first success - HALF_OPEN → OPEN: on first failure """
def __init__( self, failure_threshold: int = 5, recovery_timeout: float = 30.0, ): self._failure_threshold = failure_threshold self._recovery_timeout = recovery_timeout self._failure_count = 0 self._last_failure_time = 0.0 self._state = CircuitState.CLOSED
@property def state(self) -> CircuitState: if self._state == CircuitState.OPEN: # Check if recovery timeout has elapsed if time.monotonic() - self._last_failure_time >= self._recovery_timeout: self._state = CircuitState.HALF_OPEN logger.info("Circuit breaker → HALF_OPEN (testing recovery)") return self._state
def record_success(self) -> None: self._failure_count = 0 if self._state == CircuitState.HALF_OPEN: self._state = CircuitState.CLOSED logger.info("Circuit breaker → CLOSED (recovered)")
def record_failure(self) -> None: self._failure_count += 1 self._last_failure_time = time.monotonic() if self._failure_count >= self._failure_threshold: self._state = CircuitState.OPEN logger.warning( "Circuit breaker → OPEN after %d failures (blocking requests for %ds)", self._failure_count, self._recovery_timeout, )
@asynccontextmanager async def protect( self, session_factory ) -> AsyncIterator[AsyncSession]: """Wrap session creation with circuit breaker logic.""" if self.state == CircuitState.OPEN: raise ConnectionError( "Database circuit breaker is OPEN. " "Failing fast to prevent cascade." )
try: async with session_factory() as session: yield session self.record_success() except Exception as exc: self.record_failure() raise
# Global instancedb_circuit_breaker = DatabaseCircuitBreaker( failure_threshold=5, recovery_timeout=30.0,)Integrate with the session dependency:
# src/db/session.py (with circuit breaker)from src.db.circuit_breaker import db_circuit_breaker
async def get_session() -> AsyncIterator[AsyncSession]: async with db_circuit_breaker.protect(AsyncSessionLocal) as session: try: yield session await session.commit() except Exception: await session.rollback() raiseWhen the database is down, the first 5 requests fail normally (waiting for pool_timeout). The 6th request and all subsequent ones fail immediately with ConnectionError — no waiting, no queue buildup. After 30 seconds, the circuit breaker enters HALF_OPEN and allows one request through. If it succeeds, the breaker closes and traffic resumes. If it fails, the breaker reopens for another 30 seconds.
PgBouncer: When Application Pooling Is Not Enough
At extreme scale — thousands of requests per second across dozens of application instances — application-level pooling hits a wall. Each instance maintains its own pool, and the aggregate connection count can exceed PostgreSQL’s max_connections (default: 100). PgBouncer sits between your application and PostgreSQL, multiplexing thousands of application connections onto a smaller set of database connections.
%3b%7d%23mermaid-1 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-1-gradient)%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-1-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M176.078%2c47L180.466%2c47C184.854%2c47%2c193.63%2c47%2c214.46%2c69.958C235.291%2c92.916%2c268.175%2c138.832%2c284.617%2c161.79L301.06%2c184.748' id='mermaid-1-L_A1_PG_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A1_PG_0' data-points='W3sieCI6MTc2LjA3ODEyNSwieSI6NDd9LHsieCI6MjAyLjQwNjI1LCJ5Ijo0N30seyJ4IjozMDMuMzg4NTQ5ODA0Njg3NSwieSI6MTg4fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M176.078%2c175L180.466%2c175C184.854%2c175%2c193.63%2c175%2c202.069%2c176.885C210.508%2c178.771%2c218.609%2c182.541%2c222.66%2c184.427L226.711%2c186.312' id='mermaid-1-L_A2_PG_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A2_PG_0' data-points='W3sieCI6MTc2LjA3ODEyNSwieSI6MTc1fSx7IngiOjIwMi40MDYyNSwieSI6MTc1fSx7IngiOjIzMC4zMzc1MjQ0MTQwNjI1LCJ5IjoxODh9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M176.078%2c303L180.466%2c303C184.854%2c303%2c193.63%2c303%2c202.069%2c301.115C210.508%2c299.229%2c218.609%2c295.459%2c222.66%2c293.573L226.711%2c291.688' id='mermaid-1-L_A3_PG_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A3_PG_0' data-points='W3sieCI6MTc2LjA3ODEyNSwieSI6MzAzfSx7IngiOjIwMi40MDYyNSwieSI6MzAzfSx7IngiOjIzMC4zMzc1MjQ0MTQwNjI1LCJ5IjoyOTB9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M177.406%2c431L181.573%2c431C185.74%2c431%2c194.073%2c431%2c214.682%2c408.042C235.291%2c385.084%2c268.175%2c339.168%2c284.617%2c316.21L301.06%2c293.252' id='mermaid-1-L_A4_PG_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A4_PG_0' data-points='W3sieCI6MTc3LjQwNjI1LCJ5Ijo0MzF9LHsieCI6MjAyLjQwNjI1LCJ5Ijo0MzF9LHsieCI6MzAzLjM4ODU0OTgwNDY4NzUsInkiOjI5MH1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M452.422%2c239L456.589%2c239C460.755%2c239%2c469.089%2c239%2c476.755%2c239C484.422%2c239%2c491.422%2c239%2c494.922%2c239L498.422%2c239' id='mermaid-1-L_PG_DB_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PG_DB_0' data-points='W3sieCI6NDUyLjQyMTg3NSwieSI6MjM5fSx7IngiOjQ3Ny40MjE4NzUsInkiOjIzOX0seyJ4Ijo1MDIuNDIxODc1LCJ5IjoyMzl9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A1_PG_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A2_PG_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A3_PG_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A4_PG_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_PG_DB_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-A1-0' data-look='classic' transform='translate(92.703125%2c 47)'%3e%3crect class='basic label-container' style='' x='-83.375' y='-39' width='166.75' height='78'/%3e%3cg class='label' style='' transform='translate(-53.375%2c -24)'%3e%3crect/%3e%3cforeignObject width='106.75' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eApp Instance 1%3cbr /%3epool_size=5%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-PG-1' data-look='classic' transform='translate(339.9140625%2c 239)'%3e%3crect class='basic label-container' style='fill:%23fff3e0 !important%3bstroke:%23e65100 !important' x='-112.5078125' y='-51' width='225.015625' height='102'/%3e%3cg class='label' style='' transform='translate(-82.5078125%2c -36)'%3e%3crect/%3e%3cforeignObject width='165.015625' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePgBouncer%3cbr /%3emax_client_conn=1000%3cbr /%3edefault_pool_size=50%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-A2-2' data-look='classic' transform='translate(92.703125%2c 175)'%3e%3crect class='basic label-container' style='' x='-83.375' y='-39' width='166.75' height='78'/%3e%3cg class='label' style='' transform='translate(-53.375%2c -24)'%3e%3crect/%3e%3cforeignObject width='106.75' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eApp Instance 2%3cbr /%3epool_size=5%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-A3-4' data-look='classic' transform='translate(92.703125%2c 303)'%3e%3crect class='basic label-container' style='' x='-83.375' y='-39' width='166.75' height='78'/%3e%3cg class='label' style='' transform='translate(-53.375%2c -24)'%3e%3crect/%3e%3cforeignObject width='106.75' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eApp Instance 3%3cbr /%3epool_size=5%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-A4-6' data-look='classic' transform='translate(92.703125%2c 431)'%3e%3crect class='basic label-container' style='' x='-84.703125' y='-39' width='169.40625' height='78'/%3e%3cg class='label' style='' transform='translate(-54.703125%2c -24)'%3e%3crect/%3e%3cforeignObject width='109.40625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eApp Instance N%3cbr /%3epool_size=5%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-DB-9' data-look='classic' transform='translate(590.203125%2c 239)'%3e%3cpath d='M0%2c14.602828030775628 a87.78125%2c14.602828030775628 0%2c0%2c0 175.5625%2c0 a87.78125%2c14.602828030775628 0%2c0%2c0 -175.5625%2c0 l0%2c77.60282803077563 a87.78125%2c14.602828030775628 0%2c0%2c0 175.5625%2c0 l0%2c-77.60282803077563' class='basic label-container outer-path' style='' transform='translate(-87.78125%2c -53.40424204616344)'/%3e%3cg class='label' style='' transform='translate(-80.28125%2c -14)'%3e%3crect/%3e%3cforeignObject width='160.5625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePostgreSQL%3cbr /%3emax_connections=100%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-1-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
When using PgBouncer in transaction mode (the recommended mode for modern applications), each application connection is mapped to a PostgreSQL connection only for the duration of a transaction. Between transactions, the PostgreSQL connection is returned to PgBouncer’s pool and can be used by other application connections.
[databases]shelfwise = host=postgres port=5432 dbname=shelfwise
[pgbouncer]listen_port = 6432pool_mode = transaction ; connection released after each transactionmax_client_conn = 1000 ; total client connections PgBouncer acceptsdefault_pool_size = 50 ; PostgreSQL connections per databasereserve_pool_size = 10 ; extra connections for burstreserve_pool_timeout = 3 ; seconds before using reserve poolserver_idle_timeout = 300 ; close idle server connections after 5 minWith PgBouncer in the path, your application pool settings change:
# With PgBouncer — application pool is now "client connections to PgBouncer"engine = create_async_engine( "postgresql+asyncpg://pgbouncer:6432/shelfwise", pool_size=5, # Small — PgBouncer does the real pooling max_overflow=10, pool_timeout=5, # Short — PgBouncer queues are faster pool_pre_ping=True, pool_recycle=600, # PgBouncer recycles too, so keep this shorter)Schema-Per-Tenant: Connection Pool Interactions
For ShelfWise enterprise tenants using schema-per-tenant isolation (from Part 9), the pool needs to set search_path on every session checkout. The session event from Part 9 extends naturally:
from sqlalchemy import event, textfrom sqlalchemy.pool import Pool
from src.core.context import get_current_tenant, is_system_context
@event.listens_for(Pool, "checkout")def set_tenant_search_path(dbapi_conn, connection_record, connection_proxy): """Set PostgreSQL search_path to the tenant's schema on checkout.
This runs every time a connection is checked out from the pool, ensuring the correct schema regardless of which connection we get. """ if is_system_context(): # System context uses the public schema dbapi_conn.execute("SET search_path TO public") return
try: tenant = get_current_tenant() except RuntimeError: # No tenant context (health check, startup) — use public dbapi_conn.execute("SET search_path TO public") return
schema_name = f"tenant_{tenant.slug}" # Parameterized to prevent SQL injection via tenant slug dbapi_conn.execute(f"SET search_path TO {schema_name}, public")This interacts with PgBouncer’s transaction mode: because PgBouncer releases the server connection after each transaction, the SET search_path must be issued at the start of every transaction, not just at checkout. The pool checkout event fires at the right time — when the application acquires a connection from the pool, which in PgBouncer’s case happens at transaction start.
Monitoring Pool Health
A pool that silently exhausts is worse than one that fails loudly. Instrument the pool to expose metrics:
import loggingfrom sqlalchemy import eventfrom sqlalchemy.pool import Pool
logger = logging.getLogger("shelfwise.pool")
@event.listens_for(Pool, "checkout")def on_checkout(dbapi_conn, connection_record, connection_proxy): pool = connection_proxy._pool logger.debug( "Pool checkout", extra={ "pool_size": pool.size(), "checked_in": pool.checkedin(), "checked_out": pool.checkedout(), "overflow": pool.overflow(), }, )
@event.listens_for(Pool, "checkin")def on_checkin(dbapi_conn, connection_record): logger.debug("Pool checkin")
def get_pool_stats(engine) -> dict: """Expose pool stats for health check endpoints and metrics.""" pool = engine.pool return { "pool_size": pool.size(), "checked_in": pool.checkedin(), "checked_out": pool.checkedout(), "overflow": pool.overflow(), "utilization_pct": round( pool.checkedout() / (pool.size() + pool.overflow()) * 100 if (pool.size() + pool.overflow()) > 0 else 0, 1, ), }Expose it in the health check endpoint:
@router.get("/health")async def health(): stats = get_pool_stats(engine) status = "healthy" if stats["utilization_pct"] < 80 else "degraded" return {"status": status, "pool": stats}Set alerts at 70% pool utilization. At 80%, you are one traffic spike away from exhaustion. At 90%, you are already in the incident.
Key Takeaways
pool_size=5default is a time bomb. Any non-trivial production workload needs explicit pool configuration. Start withpool_size=20, max_overflow=30for medium traffic and tune from there.pool_pre_ping=Trueis non-negotiable. The 1ms cost per checkout prevents hard errors from stale connections. Without it, database failovers and network blips cause immediate application errors.pool_timeout=10fails fast. The default 30 seconds means users wait half a minute before seeing an error. 10 seconds absorbs short bursts without hiding pool exhaustion.- Request-scoped sessions guarantee connection return. The
async withblock ensures the session is closed and the connection returns to the pool even if the route handler raises. - Read/write splitting offloads 90% of queries to read replicas. Route catalog browsing and search to replicas, orders and updates to the primary.
- Circuit breakers prevent cascade failures. When the database is down, fail fast instead of queuing requests that will all timeout. Five failures trigger the breaker; 30 seconds later it tests recovery.
- PgBouncer handles extreme scale. When aggregate application connections exceed PostgreSQL’s limits, PgBouncer multiplexes thousands of clients onto dozens of database connections.
- Monitor pool utilization, alert at 70%. A pool at 80% is one traffic spike from exhaustion. Metrics and alerts are cheaper than incidents.
ShelfWise now has a database layer that handles Black Friday traffic without cascading failures. The connection pool is sized for production, reads are split to replicas, the circuit breaker prevents cascade, and PgBouncer handles the multiplexing at extreme scale. The next post in the series tackles the API layer: rate limiting, pagination, and versioning for a multi-tenant SaaS.