Python’s async keyword does not make your code faster. It makes your I/O-bound code more efficient. Understanding the difference determines whether your FastAPI app handles 10 concurrent requests or 10,000.
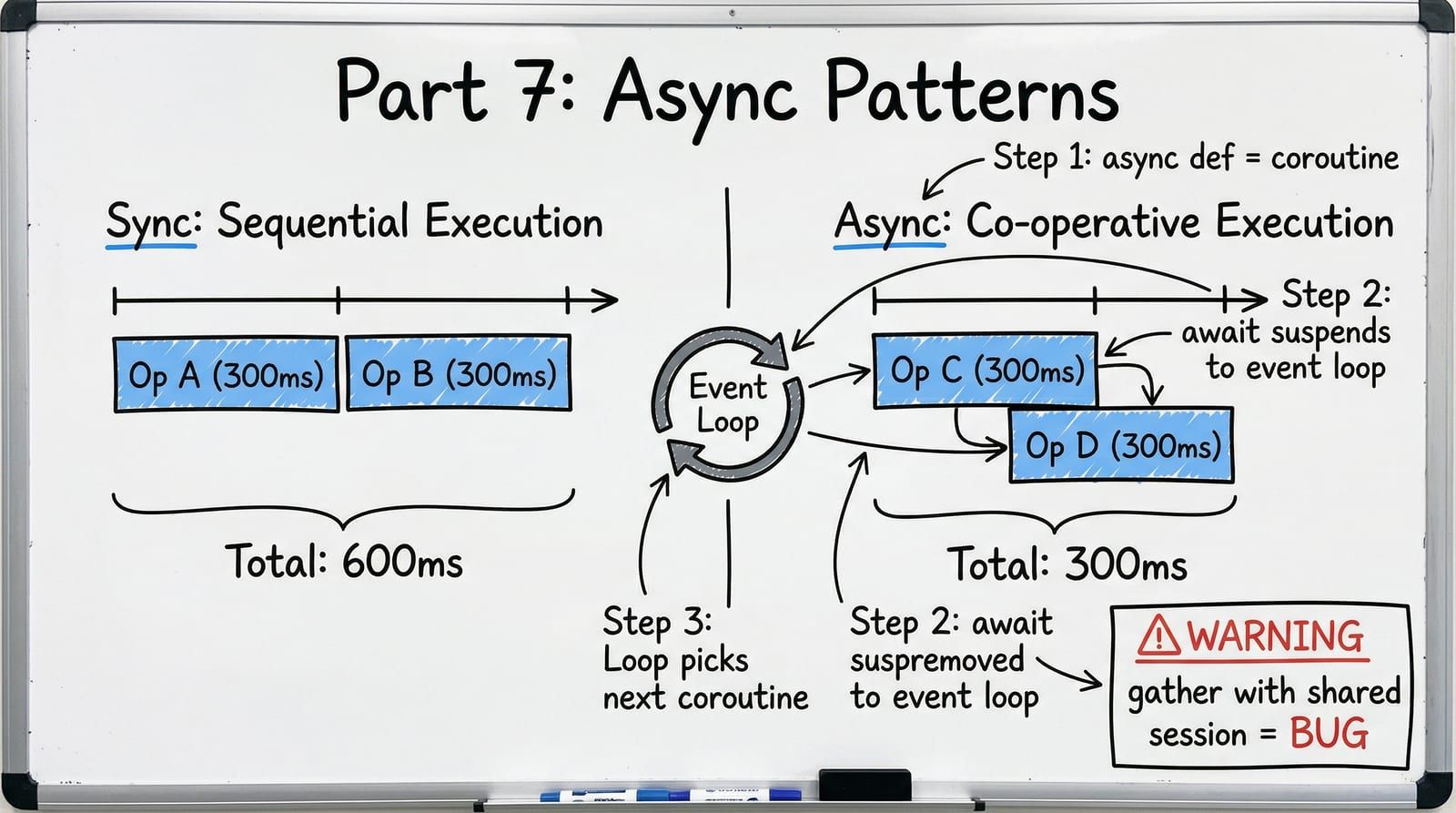
The confusion usually sounds like this: “We added async everywhere, so it should be concurrent now.” Adding async def to a function makes it a coroutine — that is necessary but not sufficient. You also need to avoid blocking the event loop, use asyncio.gather() correctly, and understand when SQLAlchemy’s async session is and is not safe to use concurrently.
Concurrency vs Parallelism in Python
Parallelism means multiple CPU cores executing code simultaneously. Python’s GIL (Global Interpreter Lock) prevents this for CPU-bound work — only one thread executes Python bytecode at a time.
Concurrency means managing multiple tasks by interleaving them — while one task is waiting for I/O (a database response, an HTTP call, a file read), another task runs. This is what asyncio gives you.
The event loop processes one coroutine at a time. When a coroutine hits an await, it suspends and the loop picks up another waiting coroutine. The result: your FastAPI server handles many concurrent requests without spawning a thread per request.
%3bfill:%23eee%3bstroke-width:1%3b%7d%23mermaid-0 rect.actor.outer-path%5bdata-look='neo'%5d%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 rect.note%5bdata-look='neo'%5d%7bstroke:%23999%3bfill:%23666%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 text.actor%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .actor-line%7bstroke:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-0 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-0 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-0 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-0 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .sequenceNumber%7bfill:white%3b%7d%23mermaid-0 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-0 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .labelBox%7bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:%23eee%3bfilter:none%3b%7d%23mermaid-0 .labelText%2c%23mermaid-0 .labelText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .loopText%2c%23mermaid-0 .loopText%26gt%3btspan%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(0%2c 0%25%2c 83%25)%3bfill:hsl(0%2c 0%25%2c 83%25)%3b%7d%23mermaid-0 .note%7bstroke:%23999%3bfill:%23666%3b%7d%23mermaid-0 .noteText%2c%23mermaid-0 .noteText%26gt%3btspan%7bfill:white%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-0 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-0 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23eee%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-0 .actor-man circle%2c%23mermaid-0 line%7bfill:%23eee%3bstroke-width:2px%3b%7d%23mermaid-0 g rect.rect%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3bstroke:%23999%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-0-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-0-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-0-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-0-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cg data-et='note' data-id='i0'%3e%3crect x='50' y='75' fill='%23EDF2AE' stroke='%23666' width='250' height='37' class='note'/%3e%3ctext x='175' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='noteText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='175'%3eSynchronous (one at a time)%3c/tspan%3e%3c/text%3e%3c/g%3e%3cg data-et='note' data-id='i9'%3e%3crect x='50' y='474' fill='%23EDF2AE' stroke='%23666' width='250' height='37' class='note'/%3e%3ctext x='175' y='479' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='noteText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='175'%3eAsync (concurrent I/O)%3c/tspan%3e%3c/text%3e%3c/g%3e%3ctext x='317' y='127' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRequest A%3c/text%3e%3cline x1='76' y1='156' x2='557' y2='156' class='messageLine0' data-et='message' data-id='i1' data-from='Client1' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='697' y='171' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eQuery (300ms wait)%3c/text%3e%3cline x1='562' y1='200' x2='832' y2='200' class='messageLine0' data-et='message' data-id='i2' data-from='EventLoop' data-to='Database' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='700' y='215' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResult%3c/text%3e%3cline x1='835' y1='244' x2='565' y2='244' class='messageLine1' data-et='message' data-id='i3' data-from='Database' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='320' y='259' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResponse%3c/text%3e%3cline x1='560' y1='288' x2='79' y2='288' class='messageLine1' data-et='message' data-id='i4' data-from='EventLoop' data-to='Client1' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='417' y='303' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRequest B%3c/text%3e%3cline x1='276' y1='332' x2='557' y2='332' class='messageLine0' data-et='message' data-id='i5' data-from='Client2' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='697' y='347' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eQuery (300ms wait)%3c/text%3e%3cline x1='562' y1='376' x2='832' y2='376' class='messageLine0' data-et='message' data-id='i6' data-from='EventLoop' data-to='Database' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='700' y='391' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResult%3c/text%3e%3cline x1='835' y1='420' x2='565' y2='420' class='messageLine1' data-et='message' data-id='i7' data-from='Database' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='420' y='435' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResponse%3c/text%3e%3cline x1='560' y1='464' x2='279' y2='464' class='messageLine1' data-et='message' data-id='i8' data-from='EventLoop' data-to='Client2' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='317' y='526' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRequest A%3c/text%3e%3cline x1='76' y1='555' x2='557' y2='555' class='messageLine0' data-et='message' data-id='i10' data-from='Client1' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='697' y='570' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eQuery A (await %e2%80%94 suspends)%3c/text%3e%3cline x1='562' y1='599' x2='832' y2='599' class='messageLine0' data-et='message' data-id='i11' data-from='EventLoop' data-to='Database' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='417' y='614' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eRequest B (runs while A waits)%3c/text%3e%3cline x1='276' y1='643' x2='557' y2='643' class='messageLine0' data-et='message' data-id='i12' data-from='Client2' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='697' y='658' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eQuery B (await %e2%80%94 suspends)%3c/text%3e%3cline x1='562' y1='687' x2='832' y2='687' class='messageLine0' data-et='message' data-id='i13' data-from='EventLoop' data-to='Database' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='fill: none%3b'/%3e%3ctext x='700' y='702' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResult A%3c/text%3e%3cline x1='835' y1='731' x2='565' y2='731' class='messageLine1' data-et='message' data-id='i14' data-from='Database' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='320' y='746' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResponse A%3c/text%3e%3cline x1='560' y1='775' x2='79' y2='775' class='messageLine1' data-et='message' data-id='i15' data-from='EventLoop' data-to='Client1' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='700' y='790' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResult B%3c/text%3e%3cline x1='835' y1='819' x2='565' y2='819' class='messageLine1' data-et='message' data-id='i16' data-from='Database' data-to='EventLoop' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='420' y='834' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eResponse B%3c/text%3e%3cline x1='560' y1='863' x2='279' y2='863' class='messageLine1' data-et='message' data-id='i17' data-from='EventLoop' data-to='Client2' stroke-width='2' stroke='none' marker-end='url(%23mermaid-0-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3c/svg%3e)
Async does not reduce total work. A 300ms database query takes 300ms either way. Async lets your server do other work during that wait instead of blocking a thread.
When asyncio.gather() Is Wrong
The most dangerous misuse of asyncio.gather() is passing coroutines that share a single AsyncSession. This looks correct but produces intermittent production failures:
# BUG: two coroutines sharing the same session in gather()async def get_order_details(order_id: int, session: AsyncSession): order, books = await asyncio.gather( session.execute(select(Order).where(Order.id == order_id)), session.execute(select(Book).join(OrderItem).where(OrderItem.order_id == order_id)), ) # SQLAlchemy async sessions are NOT safe for concurrent use. # This causes: sqlalchemy.exc.InvalidRequestError # It may work in tests (sequential execution under low load) # and fail in production under concurrent traffic.The reason is that AsyncSession maintains internal state (transaction context, identity map, pending flush queue) that is not designed for concurrent access. Two coroutines modifying this state simultaneously corrupts it.
Correct Pattern: Separate Sessions for Parallel Work
When you genuinely need to parallelize independent database queries — for example, loading a dashboard that needs both recent orders and a reading list — give each coroutine its own session:
# CORRECT: independent sessions for parallel queriesasync def fetch_dashboard_data(user_id: int): async def get_recent_orders(): async with AsyncSessionLocal() as session: result = await session.execute( select(Order).where(Order.user_id == user_id).limit(5) ) return result.scalars().all()
async def get_reading_list(): async with AsyncSessionLocal() as session: result = await session.execute( select(Book).join(ReadingList).where(ReadingList.user_id == user_id) ) return result.scalars().all()
orders, books = await asyncio.gather( get_recent_orders(), get_reading_list(), ) return {"orders": orders, "books": books}This works because the two coroutines are genuinely independent. They query different tables, hold separate connections from the pool, and do not share any mutable state. The total wall-clock time approaches max(query_a, query_b) instead of query_a + query_b.
When the queries are dependent — when query B uses a result from query A — do not parallelize them. Run them sequentially in the same session:
# CORRECT: dependent queries run sequentially in one sessionasync def get_order_with_user(order_id: int, session: AsyncSession): result = await session.execute( select(Order).where(Order.id == order_id) ) order = result.scalar_one_or_none() if order is None: raise OrderNotFoundError(order_id)
user_result = await session.execute( select(User).where(User.id == order.user_id) ) return order, user_result.scalar_one()Lazy Loading Is a Trap in Async SQLAlchemy
SQLAlchemy’s lazy loading fires a synchronous database query when you access a relationship attribute. In a synchronous context, this just works (and is part of why it is a common pitfall — it looks fine in sync code). In async SQLAlchemy, it raises a MissingGreenlet error because there is no event loop thread to execute the synchronous query on:
# N+1 bug in async context — raises MissingGreenletasync def list_orders(session: AsyncSession): result = await session.execute(select(Order)) orders = result.scalars().all() for order in orders: # Triggers a SYNC lazy load — raises: # sqlalchemy.exc.MissingGreenlet: greenlet_spawn has not been called print(order.user.name)The fix is to use eager loading strategies — selectinload or joinedload — so the related objects are fetched as part of the original query:
# CORRECT: eager load with selectinloadasync def list_orders(session: AsyncSession): result = await session.execute( select(Order) .options(selectinload(Order.user)) .options(selectinload(Order.items).selectinload(OrderItem.book)) ) orders = result.scalars().all() # order.user and order.items are pre-loaded — no lazy queries, no MissingGreenlet for order in orders: print(order.user.name) # safe| Strategy | selectinload | joinedload |
|---|---|---|
| How it works | Runs a second SELECT IN query for the relationship | Uses SQL JOIN in the original query |
| SQL queries generated | 2 queries (parent + children batch) | 1 query (larger result set) |
| Async safe | Yes | Yes |
| Best for | Collections (one-to-many) | Single objects (many-to-one) |
| Memory usage | Lower (separate result sets) | Higher (cartesian product for collections) |
Use selectinload for one-to-many relationships (an order’s items, an author’s posts). Use joinedload for many-to-one relationships where the JOIN does not multiply rows (an order’s user, a post’s author).
Timeouts and Cancellation
A slow database query blocks the coroutine awaiting it and delays other requests that need the same event loop iteration. Production systems need query timeouts to prevent one slow query from cascading:
import asynciofrom sqlalchemy import selectfrom sqlalchemy.ext.asyncio import AsyncSessionfrom src.core.exceptions import ServiceTimeoutErrorfrom src.models import Bookfrom src.schemas.book import BookResponse
async def get_book_with_timeout(book_id: int, session: AsyncSession) -> BookResponse | None: try: async with asyncio.timeout(5.0): # Python 3.11+ result = await session.execute( select(Book).where(Book.id == book_id) ) book = result.scalar_one_or_none() return BookResponse.model_validate(book) if book else None except TimeoutError: await session.rollback() raise ServiceTimeoutError("Database query exceeded 5 second limit")Always rollback() the session after a timeout. A session that times out mid-transaction may have partial writes. Rolling back ensures the session is in a consistent state before being returned to the pool.
Background Tasks Without Blocking the Response
Some work should happen after the response is sent — not before. Sending a confirmation email, triggering a webhook, updating analytics counters. These do not affect the response body, so making the client wait for them is pure overhead.
FastAPI’s BackgroundTasks is the correct tool here:
from fastapi import BackgroundTasksfrom src.api.deps import OrderServiceDepfrom src.schemas.order import OrderCreate, OrderResponse
@router.post("/orders/")async def create_order( data: OrderCreate, background_tasks: BackgroundTasks, service: OrderServiceDep,) -> OrderResponse: order = await service.place_order(data) # Response is sent to the client immediately. # send_order_confirmation runs after — client does not wait. background_tasks.add_task(send_order_confirmation, order.id, data.user_email) return order
async def send_order_confirmation(order_id: int, email: str) -> None: # Runs in the same event loop after the response is returned. # Use a fresh session here — the request-scoped session is already closed. async with AsyncSessionLocal() as session: order = await session.get(Order, order_id) await email_client.send( to=email, subject=f"Order #{order_id} confirmed", body=render_confirmation_email(order), )BackgroundTasks runs the task in the same event loop as the request, but after the response is fully sent. It is appropriate for lightweight async tasks. For CPU-heavy work or tasks that must survive server restarts, use a task queue (Celery, ARQ) instead.
Detecting Blocking Code in an Async Server
The hardest async bugs are the ones that work locally and fail at scale — blocking code that appears to work because load is low. A synchronous time.sleep() or a requests.get() call inside an async def blocks the entire event loop, not just the current coroutine.
The tool to find these: asyncio.set_event_loop_policy(asyncio.DefaultEventLoopPolicy()) with debug mode enabled during testing:
# In your test setup or dev startup:import asyncioasyncio.get_event_loop().set_debug(True)# Logs a warning for coroutines that take longer than 0.1s# Also warns on blocking calls that hold the loop for > 0.1sThe most common sources of accidental blocking in FastAPI code:
requests.get()— usehttpx.AsyncClientinsteadopen()/Path.read_text()— useaiofilesfor I/O-heavy file work- CPU-heavy work — offload to
asyncio.run_in_executor(None, sync_fn)with a thread pool
Key Takeaways
- Async is concurrency, not parallelism. Python’s GIL prevents true parallel execution.
asynciomakes I/O-bound waiting efficient, not CPU-bound computation faster. AsyncSessionis not concurrent-safe. Never pass a shared session to coroutines insideasyncio.gather(). Give each coroutine its own session.- Lazy loading raises
MissingGreenletin async context. Useselectinloadfor one-to-many andjoinedloadfor many-to-one relationships in all async queries. - Separate sessions for
gather(). Independent queries can run in parallel safely — but each coroutine must own its session. The session factory is cheap. - Use
BackgroundTasksfor post-response work. Email, webhooks, analytics counters — none of these should block the client response.
Next: Part 8 brings everything together — a complete testing strategy for the BookStore API covering unit tests (with fakes), integration tests (with a real test database), and API-level tests with TestClient and dependency overrides.