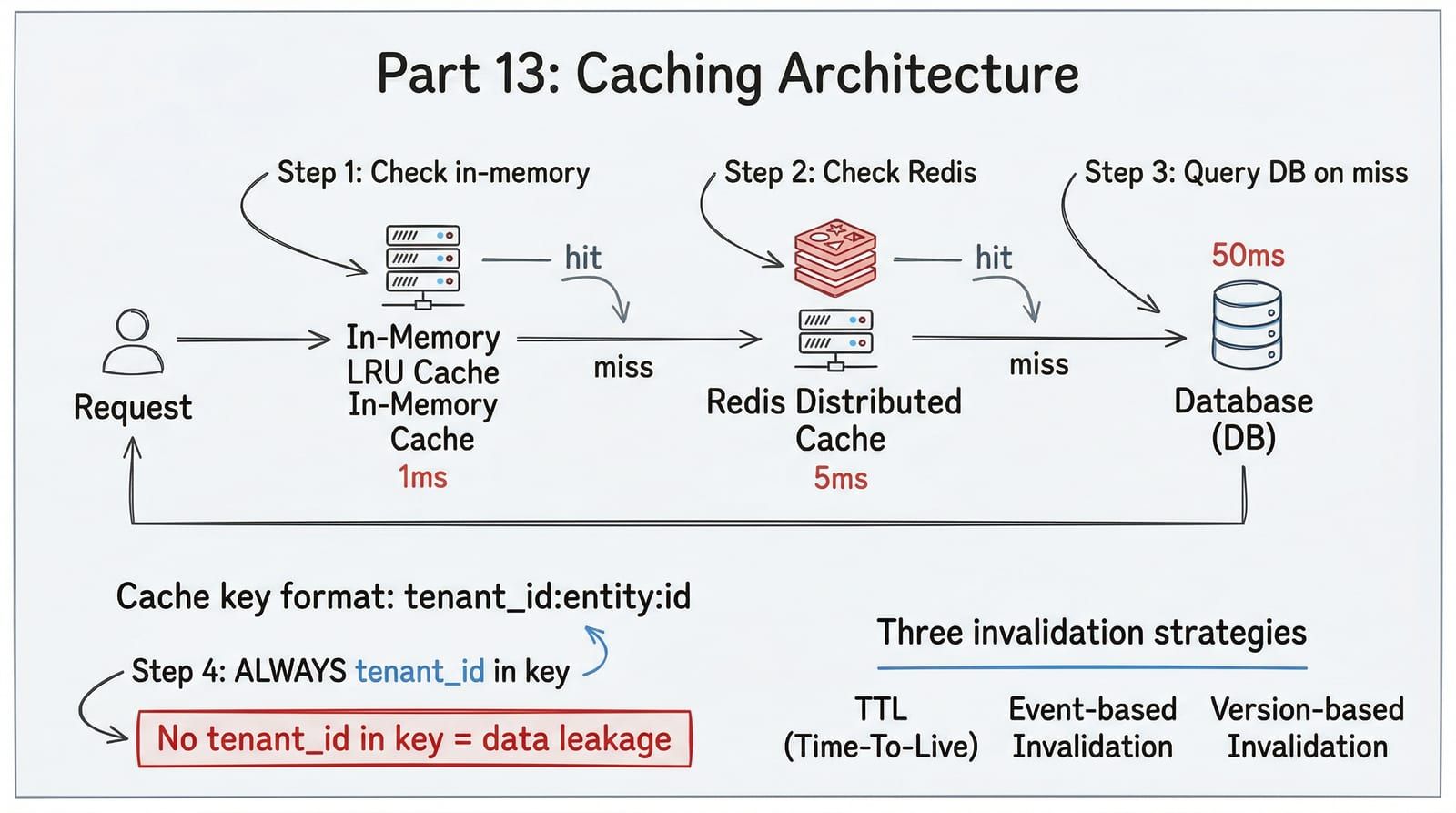
Without caching, every request hits the database. At ShelfWise’s scale of 1M transactions per day, that means the catalog endpoint alone generates 500 queries per second for data that changes once a day. The database becomes the bottleneck within weeks, and the fix is not a bigger database — the fix is not asking the database for data it already gave you.
But caching with multi-tenancy is treacherous. A cache key of catalog:fiction without a tenant prefix means Powell’s Books sees Strand’s catalog. That is not a performance bug. That is a data breach. Every cache key in a multi-tenant system must be scoped to a tenant, and the architecture must make it impossible to forget.
Multi-Layer Cache Architecture
A production caching system has three layers. Each layer trades capacity for speed:
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M216.438%2c62L216.438%2c66.167C216.438%2c70.333%2c216.438%2c78.667%2c216.438%2c86.333C216.438%2c94%2c216.438%2c101%2c216.438%2c104.5L216.438%2c108' id='mermaid-0-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MjE2LjQzNzUsInkiOjYyfSx7IngiOjIxNi40Mzc1LCJ5Ijo4N30seyJ4IjoyMTYuNDM3NSwieSI6MTEyfV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M150.81%2c281.31L129.157%2c298.415C107.504%2c315.519%2c64.197%2c349.728%2c42.544%2c396.544C20.891%2c443.359%2c20.891%2c502.781%2c20.891%2c562.203C20.891%2c621.625%2c20.891%2c681.047%2c20.891%2c723.424C20.891%2c765.802%2c20.891%2c791.135%2c20.891%2c816.469C20.891%2c841.802%2c20.891%2c867.135%2c20.891%2c890.469C20.891%2c913.802%2c20.891%2c935.135%2c20.891%2c954.469C20.891%2c973.802%2c20.891%2c991.135%2c20.891%2c1008.469C20.891%2c1025.802%2c20.891%2c1043.135%2c20.891%2c1060.469C20.891%2c1077.802%2c20.891%2c1095.135%2c32.81%2c1107.759C44.729%2c1120.382%2c68.568%2c1128.295%2c80.487%2c1132.252L92.406%2c1136.209' id='mermaid-0-L_B_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_R_0' data-points='W3sieCI6MTUwLjgxMDAwOTg3Njc5MTIsInkiOjI4MS4zMTAwMDk4NzY3OTEyNH0seyJ4IjoyMC44OTA2MjUsInkiOjM4My45Mzc1fSx7IngiOjIwLjg5MDYyNSwieSI6NTYyLjIwMzEyNX0seyJ4IjoyMC44OTA2MjUsInkiOjc0MC40Njg3NX0seyJ4IjoyMC44OTA2MjUsInkiOjgxNi40Njg3NX0seyJ4IjoyMC44OTA2MjUsInkiOjg5Mi40Njg3NX0seyJ4IjoyMC44OTA2MjUsInkiOjk1Ni40Njg3NX0seyJ4IjoyMC44OTA2MjUsInkiOjEwMDguNDY4NzV9LHsieCI6MjAuODkwNjI1LCJ5IjoxMDYwLjQ2ODc1fSx7IngiOjIwLjg5MDYyNSwieSI6MTExMi40Njg3NX0seyJ4Ijo5Ni4yMDIzNzM3OTgwNzY5MiwieSI6MTEzNy40Njg3NX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M259.112%2c304.263L266.688%2c317.542C274.265%2c330.821%2c289.417%2c357.379%2c296.994%2c376.158C304.57%2c394.938%2c304.57%2c405.938%2c304.57%2c411.438L304.57%2c416.938' id='mermaid-0-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MjU5LjExMTc5Nzc3MzE2MjA0LCJ5IjozMDQuMjYzMjAyMjI2ODM3OTZ9LHsieCI6MzA0LjU3MDMxMjUsInkiOjM4My45Mzc1fSx7IngiOjMwNC41NzAzMTI1LCJ5Ijo0MjAuOTM3NX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M245.791%2c644.689L234.416%2c660.653C223.04%2c676.616%2c200.29%2c708.542%2c188.914%2c737.172C177.539%2c765.802%2c177.539%2c791.135%2c177.539%2c816.469C177.539%2c841.802%2c177.539%2c867.135%2c177.539%2c890.469C177.539%2c913.802%2c177.539%2c935.135%2c177.539%2c954.469C177.539%2c973.802%2c177.539%2c991.135%2c177.539%2c1003.302C177.539%2c1015.469%2c177.539%2c1022.469%2c177.539%2c1025.969L177.539%2c1029.469' id='mermaid-0-L_C_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_D_0' data-points='W3sieCI6MjQ1Ljc5MDk3MjE0MjI1Mzk2LCJ5Ijo2NDQuNjg5NDA5NjQyMjU0fSx7IngiOjE3Ny41MzkwNjI1LCJ5Ijo3NDAuNDY4NzV9LHsieCI6MTc3LjUzOTA2MjUsInkiOjgxNi40Njg3NX0seyJ4IjoxNzcuNTM5MDYyNSwieSI6ODkyLjQ2ODc1fSx7IngiOjE3Ny41MzkwNjI1LCJ5Ijo5NTYuNDY4NzV9LHsieCI6MTc3LjUzOTA2MjUsInkiOjEwMDguNDY4NzV9LHsieCI6MTc3LjUzOTA2MjUsInkiOjEwMzMuNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M177.539%2c1087.469L177.539%2c1091.635C177.539%2c1095.802%2c177.539%2c1104.135%2c177.539%2c1111.802C177.539%2c1119.469%2c177.539%2c1126.469%2c177.539%2c1129.969L177.539%2c1133.469' id='mermaid-0-L_D_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_R_0' data-points='W3sieCI6MTc3LjUzOTA2MjUsInkiOjEwODcuNDY4NzV9LHsieCI6MTc3LjUzOTA2MjUsInkiOjExMTIuNDY4NzV9LHsieCI6MTc3LjUzOTA2MjUsInkiOjExMzcuNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M363.35%2c644.689L374.725%2c660.653C386.1%2c676.616%2c408.851%2c708.542%2c420.226%2c730.006C431.602%2c751.469%2c431.602%2c762.469%2c431.602%2c767.969L431.602%2c773.469' id='mermaid-0-L_C_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_E_0' data-points='W3sieCI6MzYzLjM0OTY1Mjg1Nzc0NjA0LCJ5Ijo2NDQuNjg5NDA5NjQyMjU0fSx7IngiOjQzMS42MDE1NjI1LCJ5Ijo3NDAuNDY4NzV9LHsieCI6NDMxLjYwMTU2MjUsInkiOjc3Ny40Njg3NX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M431.602%2c855.469L431.602%2c861.635C431.602%2c867.802%2c431.602%2c880.135%2c431.602%2c891.802C431.602%2c903.469%2c431.602%2c914.469%2c431.602%2c919.969L431.602%2c925.469' id='mermaid-0-L_E_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_F_0' data-points='W3sieCI6NDMxLjYwMTU2MjUsInkiOjg1NS40Njg3NX0seyJ4Ijo0MzEuNjAxNTYyNSwieSI6ODkyLjQ2ODc1fSx7IngiOjQzMS42MDE1NjI1LCJ5Ijo5MjkuNDY4NzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M431.602%2c983.469L431.602%2c987.635C431.602%2c991.802%2c431.602%2c1000.135%2c431.602%2c1007.802C431.602%2c1015.469%2c431.602%2c1022.469%2c431.602%2c1025.969L431.602%2c1029.469' id='mermaid-0-L_F_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_G_0' data-points='W3sieCI6NDMxLjYwMTU2MjUsInkiOjk4My40Njg3NX0seyJ4Ijo0MzEuNjAxNTYyNSwieSI6MTAwOC40Njg3NX0seyJ4Ijo0MzEuNjAxNTYyNSwieSI6MTAzMy40Njg3NX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M431.602%2c1087.469L431.602%2c1091.635C431.602%2c1095.802%2c431.602%2c1104.135%2c405.287%2c1113.688C378.973%2c1123.24%2c326.344%2c1134.012%2c300.03%2c1139.398L273.716%2c1144.784' id='mermaid-0-L_G_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_G_R_0' data-points='W3sieCI6NDMxLjYwMTU2MjUsInkiOjEwODcuNDY4NzV9LHsieCI6NDMxLjYwMTU2MjUsInkiOjExMTIuNDY4NzV9LHsieCI6MjY5Ljc5Njg3NSwieSI6MTE0NS41ODU5NzAxNzIyMDE4fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(20.890625%2c 892.46875)'%3e%3cg class='label' data-id='L_B_R_0' transform='translate(-12.890625%2c -12)'%3e%3cforeignObject width='25.78125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHIT%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(304.5703125%2c 383.9375)'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(-19.5625%2c -12)'%3e%3cforeignObject width='39.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eMISS%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(177.5390625%2c 892.46875)'%3e%3cg class='label' data-id='L_C_D_0' transform='translate(-12.890625%2c -12)'%3e%3cforeignObject width='25.78125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHIT%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_R_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(431.6015625%2c 740.46875)'%3e%3cg class='label' data-id='L_C_E_0' transform='translate(-19.5625%2c -12)'%3e%3cforeignObject width='39.125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eMISS%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_G_R_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-A-0' data-look='classic' transform='translate(216.4375%2c 35)'%3e%3crect class='basic label-container' style='' x='-94.484375' y='-27' width='188.96875' height='54'/%3e%3cg class='label' style='' transform='translate(-64.484375%2c -12)'%3e%3crect/%3e%3cforeignObject width='128.96875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eIncoming Request%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B-1' data-look='classic' transform='translate(216.4375%2c 229.46875)'%3e%3cpolygon points='117.46875%2c0 234.9375%2c-117.46875 117.46875%2c-234.9375 0%2c-117.46875' class='label-container' transform='translate(-116.96875%2c 117.46875)' style='fill:%23e8f5e9 !important%3bstroke:%232e7d32 !important'/%3e%3cg class='label' style='' transform='translate(-66.46875%2c -36)'%3e%3crect/%3e%3cforeignObject width='132.9375' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eIn-Memory Cache%3cbr /%3eTTLCache%3cbr /%3e~1ms%2c per-process%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-R-3' data-look='classic' transform='translate(177.5390625%2c 1164.46875)'%3e%3crect class='basic label-container' style='' x='-92.2578125' y='-27' width='184.515625' height='54'/%3e%3cg class='label' style='' transform='translate(-62.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='124.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eReturn Response%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-C-5' data-look='classic' transform='translate(304.5703125%2c 562.203125)'%3e%3cpolygon points='141.265625%2c0 282.53125%2c-141.265625 141.265625%2c-282.53125 0%2c-141.265625' class='label-container' transform='translate(-140.765625%2c 141.265625)' style='fill:%23fff3e0 !important%3bstroke:%23e65100 !important'/%3e%3cg class='label' style='' transform='translate(-90.265625%2c -36)'%3e%3crect/%3e%3cforeignObject width='180.53125' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRedis Cache%3cbr /%3eShared across processes%3cbr /%3e~2-5ms%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-D-7' data-look='classic' transform='translate(177.5390625%2c 1060.46875)'%3e%3crect class='basic label-container' style='' x='-102.03125' y='-27' width='204.0625' height='54'/%3e%3cg class='label' style='' transform='translate(-72.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='144.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePopulate In-Memory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-E-10' data-look='classic' transform='translate(431.6015625%2c 816.46875)'%3e%3crect class='basic label-container' style='fill:%23ffcdd2 !important%3bstroke:%23c62828 !important' x='-88.2578125' y='-39' width='176.515625' height='78'/%3e%3cg class='label' style='' transform='translate(-58.2578125%2c -24)'%3e%3crect/%3e%3cforeignObject width='116.515625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase Query%3cbr /%3e~20-200ms%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-F-12' data-look='classic' transform='translate(431.6015625%2c 956.46875)'%3e%3crect class='basic label-container' style='' x='-84.2578125' y='-27' width='168.515625' height='54'/%3e%3cg class='label' style='' transform='translate(-54.2578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='108.515625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePopulate Redis%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-G-13' data-look='classic' transform='translate(431.6015625%2c 1060.46875)'%3e%3crect class='basic label-container' style='' x='-102.03125' y='-27' width='204.0625' height='54'/%3e%3cg class='label' style='' transform='translate(-72.03125%2c -12)'%3e%3crect/%3e%3cforeignObject width='144.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePopulate In-Memory%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
In-memory is fastest but limited to a single process and lost on restart. Redis is shared across all processes but requires a network round-trip. The database is the source of truth but the slowest layer. A cache miss cascades downward; a cache hit returns at the highest available layer.
Tenant-Scoped Cache Keys
The universal pattern for multi-tenant cache keys: {tenant_id}:{entity}:{identifier}. No exceptions.
from typing import Final
CACHE_VERSION: Final[str] = "v1"
def cache_key(tenant_id: str, entity: str, identifier: str | int) -> str: """Build a tenant-scoped, versioned cache key.
Format: v1:{tenant_id}:{entity}:{identifier} Example: v1:powells:catalog:fiction """ return f"{CACHE_VERSION}:{tenant_id}:{entity}:{identifier}"
def tenant_pattern(tenant_id: str) -> str: """Pattern for all keys belonging to a tenant. Used for bulk invalidation.""" return f"{CACHE_VERSION}:{tenant_id}:*"The version prefix allows cache-wide invalidation during schema changes. Bump CACHE_VERSION to v2 and all existing keys become orphans that expire naturally — no explicit flush needed during deployments.
In-Memory Cache: TTLCache for Hot Data
Tenant configuration and feature flags (from Part 10) are read on every request and change rarely. These are ideal candidates for in-memory caching with cachetools.TTLCache:
from cachetools import TTLCachefrom typing import Any
from src.cache.keys import cache_key
class InMemoryCache: """Per-process in-memory cache with TTL expiration.
Best for: tenant config, feature flags, static lookups. Not for: user-specific data, frequently changing data. """
def __init__(self, maxsize: int = 2048, ttl: float = 60.0) -> None: self._store: TTLCache[str, Any] = TTLCache(maxsize=maxsize, ttl=ttl)
def get(self, tenant_id: str, entity: str, identifier: str | int) -> Any | None: key = cache_key(tenant_id, entity, identifier) return self._store.get(key)
def set( self, tenant_id: str, entity: str, identifier: str | int, value: Any ) -> None: key = cache_key(tenant_id, entity, identifier) self._store[key] = value
def delete(self, tenant_id: str, entity: str, identifier: str | int) -> None: key = cache_key(tenant_id, entity, identifier) self._store.pop(key, None)
def flush_tenant(self, tenant_id: str) -> int: """Remove all entries for a tenant. Returns count of removed entries.""" prefix = f"v1:{tenant_id}:" keys_to_remove = [k for k in self._store if k.startswith(prefix)] for key in keys_to_remove: del self._store[key] return len(keys_to_remove)The TTLCache evicts entries after ttl seconds and caps total entries at maxsize. For tenant config that changes via admin API, the 60-second TTL means at most 60 seconds of stale config after a change — acceptable for most use cases.
Redis Cache: Shared State Across Processes
In-memory cache is per-process. Redis gives you a shared cache that survives process restarts and is accessible to all workers. Use orjson for serialization — it is 3-10x faster than the standard json module and handles datetime, UUID, and Decimal natively.
import orjsonfrom redis.asyncio import Redisfrom typing import Any
from src.cache.keys import cache_key, tenant_pattern
class RedisCache: """Shared Redis cache with tenant-scoped keys and TTL management."""
def __init__(self, redis: Redis, default_ttl: int = 300) -> None: self._redis = redis self._default_ttl = default_ttl
async def get( self, tenant_id: str, entity: str, identifier: str | int ) -> Any | None: key = cache_key(tenant_id, entity, identifier) raw = await self._redis.get(key) if raw is None: return None return orjson.loads(raw)
async def set( self, tenant_id: str, entity: str, identifier: str | int, value: Any, ttl: int | None = None, ) -> None: key = cache_key(tenant_id, entity, identifier) raw = orjson.dumps(value) await self._redis.set(key, raw, ex=ttl or self._default_ttl)
async def delete( self, tenant_id: str, entity: str, identifier: str | int ) -> None: key = cache_key(tenant_id, entity, identifier) await self._redis.delete(key)
async def flush_tenant(self, tenant_id: str) -> int: """Delete all keys for a tenant. Used for GDPR deletion and tenant offboarding.""" pattern = tenant_pattern(tenant_id) cursor, keys = b"0", [] while True: cursor, batch = await self._redis.scan( cursor=cursor, match=pattern, count=500 ) keys.extend(batch) if cursor == b"0": break
if keys: await self._redis.delete(*keys) return len(keys)Cache-Aside Pattern: The Cached Repository
The cleanest way to add caching is the cached repository decorator. It wraps the base repository from Part 3 and adds caching transparently. The service layer does not know or care whether the repository is cached:
import structlogfrom typing import override
from src.cache.memory import InMemoryCachefrom src.cache.redis import RedisCachefrom src.core.protocols import CatalogRepositoryProtocolfrom src.schemas.catalog import CatalogItem
logger = structlog.get_logger()
class CachedCatalogRepository: """Cache-aside wrapper around the real catalog repository.
Lookup order: in-memory -> Redis -> database. On DB hit: populate both Redis and in-memory. On write: invalidate both caches. """
def __init__( self, *, repo: CatalogRepositoryProtocol, memory: InMemoryCache, redis: RedisCache, ) -> None: self._repo = repo self._memory = memory self._redis = redis
async def get_by_category( self, tenant_id: str, category: str ) -> list[CatalogItem]: # Layer 1: In-memory cached = self._memory.get(tenant_id, "catalog", category) if cached is not None: logger.debug("cache_hit", layer="memory", entity="catalog") return [CatalogItem.model_validate(item) for item in cached]
# Layer 2: Redis cached = await self._redis.get(tenant_id, "catalog", category) if cached is not None: logger.debug("cache_hit", layer="redis", entity="catalog") self._memory.set( tenant_id, "catalog", category, cached ) return [CatalogItem.model_validate(item) for item in cached]
# Layer 3: Database logger.debug("cache_miss", entity="catalog") items = await self._repo.get_by_category(tenant_id, category)
# Populate both cache layers serializable = [item.model_dump(mode="json") for item in items] self._memory.set(tenant_id, "catalog", category, serializable) await self._redis.set( tenant_id, "catalog", category, serializable, ttl=600 )
return items
async def update(self, tenant_id: str, item: CatalogItem) -> CatalogItem: result = await self._repo.update(tenant_id, item)
# Invalidate cache for the affected category self._memory.delete(tenant_id, "catalog", item.category) await self._redis.delete(tenant_id, "catalog", item.category)
logger.info("cache_invalidated", entity="catalog", category=item.category) return resultThe service layer receives a CatalogRepositoryProtocol. In production, dependency injection (Part 5) provides CachedCatalogRepository. In tests, it provides FakeRepository. The caching layer is an infrastructure concern — it never leaks into business logic.
The ShelfWise Impact
Before caching: the catalog endpoint handles 500 requests per second, each executing a database query. That is 500 queries per second for data that changes when a publisher updates their catalog — roughly once per day.
After caching with a 10-minute Redis TTL and 60-second in-memory TTL: the first request after TTL expiry hits the database. The next 499 requests serve from cache. Database queries drop from 500/s to roughly 8/s (one per TTL expiry window across categories). Latency drops from 200ms (database) to 2ms (in-memory) or 5ms (Redis).
Cache Stampede Prevention
When a popular cache key expires, hundreds of concurrent requests see a cache miss simultaneously and all hit the database. This is a cache stampede, and it can take down the database during traffic spikes.
Probabilistic Early Expiration
Recompute the cache slightly before it expires. Each request that reads a nearly-expired key has a probability of triggering a background refresh:
import randomimport timefrom typing import Any
from src.cache.redis import RedisCache
async def get_with_early_expiry( cache: RedisCache, tenant_id: str, entity: str, identifier: str | int, ttl: int, beta: float = 1.0,) -> tuple[Any | None, bool]: """Return cached value and whether an early refresh should be triggered.
Uses probabilistic early expiration (XFetch algorithm) to prevent stampedes. As the key approaches expiry, the probability of triggering a refresh increases. """ pipe = cache._redis.pipeline() key = f"v1:{tenant_id}:{entity}:{identifier}" pipe.get(key) pipe.ttl(key) raw, remaining_ttl = await pipe.execute()
if raw is None: return None, True # Cache miss — must refresh
# Probability of early refresh increases as TTL approaches 0 # At TTL=300 with remaining=30, this triggers ~10% of requests gap = ttl - remaining_ttl if gap > 0: expiry_probability = beta * random.random() threshold = gap / ttl if expiry_probability < threshold: return orjson.loads(raw), True # Return stale, signal refresh
return orjson.loads(raw), False # Fresh enough, no refresh neededDistributed Lock for Single Recomputation
When a refresh is needed, only one process should recompute. Use a Redis lock to serialize cache rebuilds:
# src/cache/stampede.py (continued)import orjsonfrom redis.asyncio import Redis
async def refresh_with_lock( redis: Redis, tenant_id: str, entity: str, identifier: str | int, ttl: int, compute_fn: Any,) -> Any: """Recompute a cache value with distributed locking.
Only one process acquires the lock and recomputes. Others wait briefly and retry from cache. Prevents N processes hitting the database simultaneously. """ lock_key = f"lock:v1:{tenant_id}:{entity}:{identifier}"
lock = redis.lock(lock_key, timeout=10, blocking_timeout=1) acquired = await lock.acquire(blocking=False)
if not acquired: # Another process is recomputing — wait and read from cache await asyncio.sleep(0.1) return await RedisCache(redis).get(tenant_id, entity, identifier)
try: value = await compute_fn() cache = RedisCache(redis) await cache.set(tenant_id, entity, identifier, value, ttl=ttl) return value finally: await lock.release()Cache Invalidation Strategies
| Strategy | How It Works | Best For | Drawback |
|---|---|---|---|
| TTL-based | Key expires after fixed duration | Data that tolerates staleness (catalog, config) | Stale for up to TTL duration after source changes |
| Event-based | Invalidate on write/update event | Data that must be fresh immediately (inventory, pricing) | Requires event propagation infrastructure |
| Version-based | Include version in key; bump version on change | Schema migrations, deployment rollouts | Old versions linger until TTL expires |
Use TTL-based invalidation as the default. Add event-based invalidation only for data where staleness causes business impact — inventory counts, pricing, and account status.
Event-Based Invalidation
When a publisher updates Powell’s catalog, invalidate only Powell’s catalog cache. Other tenants are unaffected:
import structlogfrom src.cache.memory import InMemoryCachefrom src.cache.redis import RedisCache
logger = structlog.get_logger()
class CatalogCacheInvalidator: """Listens for catalog update events and invalidates affected cache entries."""
def __init__(self, *, memory: InMemoryCache, redis: RedisCache) -> None: self._memory = memory self._redis = redis
async def on_catalog_updated( self, tenant_id: str, category: str ) -> None: """Invalidate cache for a specific tenant's category.""" self._memory.delete(tenant_id, "catalog", category) await self._redis.delete(tenant_id, "catalog", category) logger.info( "catalog_cache_invalidated", tenant_id=tenant_id, category=category, )
async def on_tenant_deleted(self, tenant_id: str) -> None: """GDPR: flush all cached data for a deleted tenant.""" memory_count = self._memory.flush_tenant(tenant_id) redis_count = await self._redis.flush_tenant(tenant_id) logger.info( "tenant_cache_flushed", tenant_id=tenant_id, memory_keys=memory_count, redis_keys=redis_count, )Graceful Degradation When Redis Is Unavailable
Redis is a cache, not the source of truth. When Redis is down, the application must continue serving requests from the database — slower, but functional. Never let a cache failure become an application failure.
import structlogfrom redis.asyncio import Redisfrom redis.exceptions import RedisErrorfrom typing import Any
from src.cache.keys import cache_key
logger = structlog.get_logger()
class ResilientRedisCache: """Redis cache that degrades gracefully on connection failures.
Every Redis operation is wrapped in a try/except. On failure: - GET returns None (cache miss -> falls through to database) - SET is silently skipped (data is still in the database) - DELETE is silently skipped (key will expire via TTL) """
def __init__(self, redis: Redis, default_ttl: int = 300) -> None: self._redis = redis self._default_ttl = default_ttl
async def get( self, tenant_id: str, entity: str, identifier: str | int ) -> Any | None: try: key = cache_key(tenant_id, entity, identifier) raw = await self._redis.get(key) if raw is None: return None return orjson.loads(raw) except RedisError: logger.warning("redis_unavailable", operation="get") return None # Degrade to database
async def set( self, tenant_id: str, entity: str, identifier: str | int, value: Any, ttl: int | None = None, ) -> None: try: key = cache_key(tenant_id, entity, identifier) raw = orjson.dumps(value) await self._redis.set(key, raw, ex=ttl or self._default_ttl) except RedisError: logger.warning("redis_unavailable", operation="set") # Silently skip — data is in the database
async def delete( self, tenant_id: str, entity: str, identifier: str | int ) -> None: try: key = cache_key(tenant_id, entity, identifier) await self._redis.delete(key) except RedisError: logger.warning("redis_unavailable", operation="delete") # Key will expire via TTLWrite-Through vs Write-Behind
Not all data uses cache-aside. Some data benefits from writing to the cache at the same time as the database (write-through) or writing to the cache first and syncing to the database later (write-behind):
| Pattern | Write Flow | Best For | Risk |
|---|---|---|---|
| Cache-aside | Write to DB, invalidate cache | Read-heavy data (catalog, config) | Stale reads between write and next cache miss |
| Write-through | Write to DB and cache simultaneously | Data read immediately after write (user profile) | Write latency increases by cache write time |
| Write-behind | Write to cache, async sync to DB | High-write-frequency data (analytics, counters) | Data loss if cache crashes before sync |
For ShelfWise, catalog data uses cache-aside (read-heavy, changes rarely). User session data uses write-through (read immediately after login). Analytics counters use write-behind (high frequency, eventual consistency is acceptable).
Key Takeaways
- Every cache key must include the tenant ID. The
cache_key()function enforces the{version}:{tenant_id}:{entity}:{id}pattern. Missing the tenant prefix is a data breach, not a bug. - Two cache layers. In-memory
TTLCachefor hot data at ~1ms. Redis for shared data at ~5ms. Database as the source of truth at ~200ms. Each layer fills the one above on miss. - Cached repository decorator. Wraps the base repository from Part 3 without modifying business logic. Caching is an infrastructure concern injected via DI from Part 5.
- Prevent cache stampedes. Probabilistic early expiration and distributed locks prevent hundreds of concurrent cache misses from overwhelming the database.
- Degrade gracefully. Redis is a cache, not a dependency. When Redis is down, every operation returns a cache miss and the database handles the load. Log at WARNING, not ERROR.
- Flush tenant data on deletion. GDPR requires removing all tenant data, including cached copies.
flush_tenant()with cursor-basedSCANremoves tenant keys without blocking Redis.
Next: Part 14 covers background tasks — async queues, worker context propagation, and the critical problem of tenant context disappearing when work moves off the request cycle.