Six weeks after ShelfWise launched, we needed to add a fulfillment_status column to the orders table. A developer ran ALTER TABLE orders ADD COLUMN fulfillment_status VARCHAR(20). The table had 50 million rows. PostgreSQL took an ACCESS EXCLUSIVE lock for eight minutes. During those eight minutes, every INSERT, UPDATE, and SELECT on the orders table queued behind the lock. Every tenant’s checkout flow failed. Every order status page returned a 504.
The developer did nothing wrong by PostgreSQL standards. But in a multi-tenant SaaS serving real customers, a migration that blocks reads for eight minutes is an eight-minute outage.
This post covers the patterns that make migrations safe: expand-contract, online DDL, tenant-aware migration runners, and recovery from partial failures.
The Expand-Contract Pattern
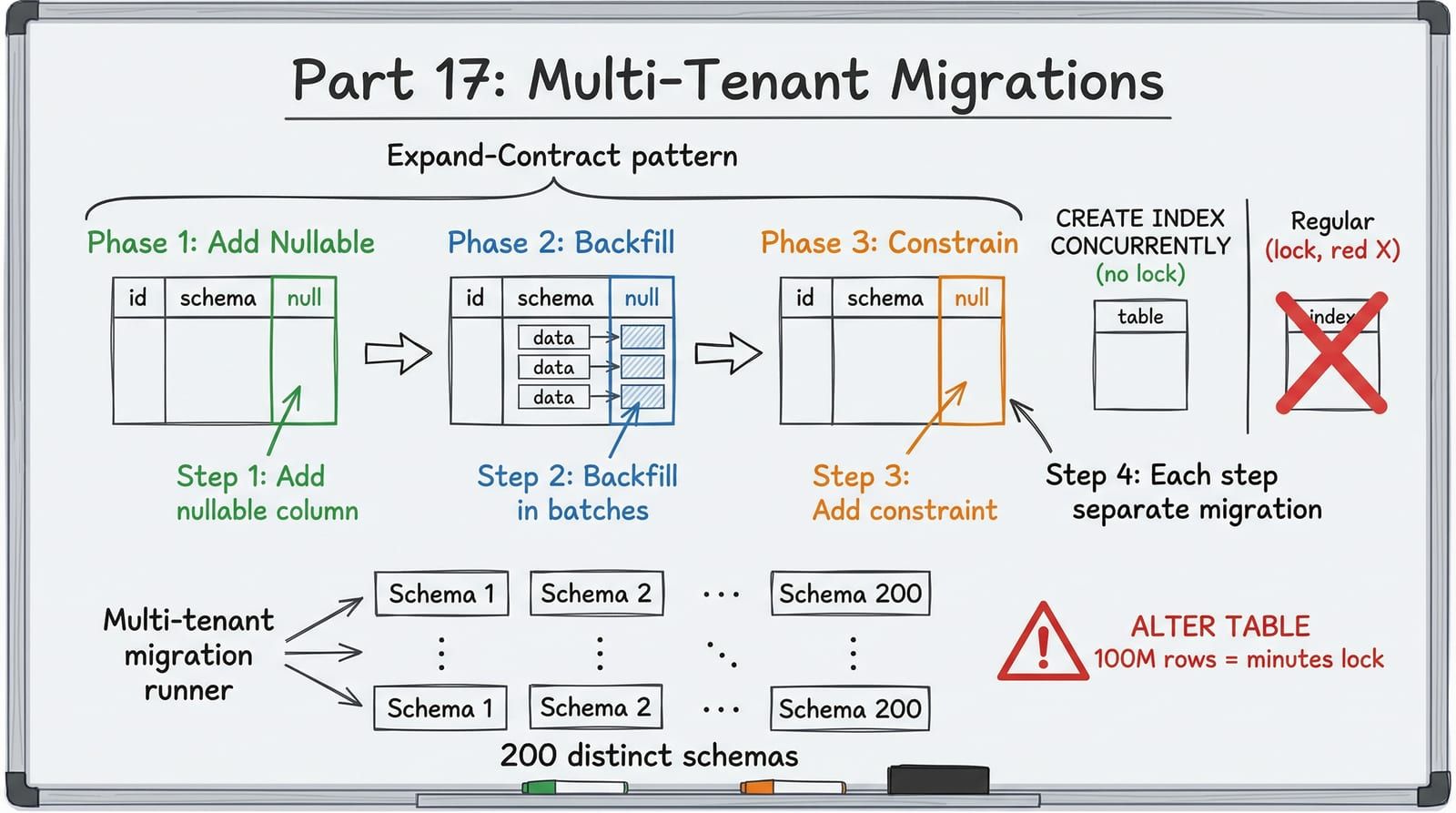
The core idea is to never make a breaking schema change in a single step. Instead, every migration is split into phases that are each individually backward-compatible.
%3b%7d%23mermaid-0 .cluster rect%7bfill:hsl(0%2c 0%25%2c 98.9215686275%25)%3bstroke:%23707070%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(-160%2c 0%25%2c 93.3333333333%25)%3bborder:1px solid %23707070%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:black%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:white%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:white%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:white%3bfill:white%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%23999%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:url(%23mermaid-0-gradient)%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%23999%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:url(%23mermaid-0-gradient)%3bfilter:drop-shadow( 1px 2px 2px rgba(185%2c185%2c185%2c1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M235.172%2c59L239.339%2c59C243.505%2c59%2c251.839%2c59%2c259.505%2c59C267.172%2c59%2c274.172%2c59%2c277.672%2c59L281.172%2c59' id='mermaid-0-L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MjM1LjE3MTg3NSwieSI6NTl9LHsieCI6MjYwLjE3MTg3NSwieSI6NTl9LHsieCI6Mjg1LjE3MTg3NSwieSI6NTl9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M483.031%2c59L487.198%2c59C491.365%2c59%2c499.698%2c59%2c507.365%2c59C515.031%2c59%2c522.031%2c59%2c525.531%2c59L529.031%2c59' id='mermaid-0-L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6NDgzLjAzMTI1LCJ5Ijo1OX0seyJ4Ijo1MDguMDMxMjUsInkiOjU5fSx7IngiOjUzMy4wMzEyNSwieSI6NTl9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-A-0' data-look='classic' transform='translate(121.5859375%2c 59)'%3e%3crect class='basic label-container' style='fill:%23e3f2fd !important%3bstroke:%231565c0 !important' x='-113.5859375' y='-51' width='227.171875' height='102'/%3e%3cg class='label' style='' transform='translate(-83.5859375%2c -36)'%3e%3crect/%3e%3cforeignObject width='167.171875' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePhase 1: Expand%3cbr /%3eADD COLUMN nullable%3cbr /%3eNo code changes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-B-1' data-look='classic' transform='translate(384.1015625%2c 59)'%3e%3crect class='basic label-container' style='fill:%23fff3e0 !important%3bstroke:%23e65100 !important' x='-98.9296875' y='-51' width='197.859375' height='102'/%3e%3cg class='label' style='' transform='translate(-68.9296875%2c -36)'%3e%3crect/%3e%3cforeignObject width='137.859375' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePhase 2: Migrate%3cbr /%3eBackfill data%3cbr /%3eCode writes to both%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-C-3' data-look='classic' transform='translate(627.0703125%2c 59)'%3e%3crect class='basic label-container' style='fill:%23c8e6c9 !important%3bstroke:%232e7d32 !important' x='-94.0390625' y='-51' width='188.078125' height='102'/%3e%3cg class='label' style='' transform='translate(-64.0390625%2c -36)'%3e%3crect/%3e%3cforeignObject width='128.078125' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePhase 3: Contract%3cbr /%3eSET NOT NULL%3cbr /%3eDrop old column%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3clinearGradient id='mermaid-0-gradient' gradientUnits='objectBoundingBox' x1='0%25' y1='0%25' x2='100%25' y2='0%25'%3e%3cstop offset='0%25' stop-color='hsl(0%2c 0%25%2c 83.3333333333%25)' stop-opacity='1'/%3e%3cstop offset='100%25' stop-color='hsl(0%2c 0%25%2c 88.9215686275%25)' stop-opacity='1'/%3e%3c/linearGradient%3e%3c/svg%3e)
Each phase is a separate deployment. If Phase 2 reveals a problem, you roll back Phase 2’s code without touching the schema. The database is always in a state that works with both the current and previous versions of the application.
| Strategy | Downtime Risk | Rollback Safety | Complexity | When to Use |
|---|---|---|---|---|
| Single ALTER TABLE | High — locks table | None — cannot undo | Trivial | Never in production |
| Expand-Contract | None — each step is safe | High — each phase reversible | Moderate | Default for all migrations |
| Shadow Table | None — writes to both | High — switch back to original | High | Large-scale restructuring |
| Blue-Green Database | None — full DB copy | Complete — switch DNS | Very high | Major version upgrades |
Concrete Example: Adding fulfillment_status
Here is how ShelfWise should have added that fulfillment_status column.
Phase 1: Expand — Add the column as nullable with no default. This is an instant metadata-only operation in PostgreSQL 11+. No table rewrite, no lock beyond a brief ACCESS EXCLUSIVE for catalog update (milliseconds).
"""Add fulfillment_status column (nullable, no default)."""
from alembic import opimport sqlalchemy as sa
revision = "001_expand"down_revision = "000_previous"
def upgrade() -> None: # Instant in PG 11+ — no table rewrite for nullable column op.add_column( "orders", sa.Column("fulfillment_status", sa.String(20), nullable=True), )
def downgrade() -> None: op.drop_column("orders", "fulfillment_status")Phase 2: Migrate — Deploy code that writes to the new column. Backfill existing rows in batches.
"""Backfill fulfillment_status from existing order status."""
from alembic import opimport sqlalchemy as sa
revision = "002_migrate"down_revision = "001_expand"
# Data migration — separate from schema migrationdef upgrade() -> None: conn = op.get_bind()
# Backfill in batches of 10,000 to avoid long-running transactions while True: result = conn.execute( sa.text(""" UPDATE orders SET fulfillment_status = CASE WHEN status = 'shipped' THEN 'shipped' WHEN status = 'delivered' THEN 'delivered' ELSE 'pending' END WHERE fulfillment_status IS NULL AND id IN ( SELECT id FROM orders WHERE fulfillment_status IS NULL LIMIT 10000 ) """) ) if result.rowcount == 0: break
def downgrade() -> None: # Nullify the column — code still handles NULL conn = op.get_bind() conn.execute(sa.text("UPDATE orders SET fulfillment_status = NULL"))Phase 3: Contract — After confirming all rows are backfilled and the new code is stable, add the NOT NULL constraint and drop any old columns.
"""Make fulfillment_status NOT NULL."""
from alembic import opimport sqlalchemy as sa
revision = "003_contract"down_revision = "002_migrate"
def upgrade() -> None: # Add NOT NULL constraint using ADD CONSTRAINT NOT VALID + VALIDATE # to avoid full table lock op.execute( "ALTER TABLE orders ADD CONSTRAINT orders_fulfillment_status_nn " "CHECK (fulfillment_status IS NOT NULL) NOT VALID" ) op.execute( "ALTER TABLE orders VALIDATE CONSTRAINT orders_fulfillment_status_nn" )
def downgrade() -> None: op.execute( "ALTER TABLE orders DROP CONSTRAINT orders_fulfillment_status_nn" )The NOT VALID + VALIDATE two-step is critical. NOT VALID adds the constraint without scanning existing rows (instant). VALIDATE scans existing rows but only takes a SHARE UPDATE EXCLUSIVE lock, which does not block reads or writes. A plain ALTER COLUMN SET NOT NULL takes an ACCESS EXCLUSIVE lock and scans the entire table.
Online DDL for PostgreSQL
PostgreSQL has specific patterns for safe DDL. Here are the operations that matter most and how to run them without locking.
CREATE INDEX CONCURRENTLY
A standard CREATE INDEX takes a SHARE lock on the table, blocking all writes for the duration. On a 50M-row table, that can be minutes.
"""Add index on fulfillment_status for query performance."""
from alembic import op
revision = "004_index"down_revision = "003_contract"
def upgrade() -> None: # CONCURRENTLY does not block writes — takes longer but is safe op.execute( "CREATE INDEX CONCURRENTLY IF NOT EXISTS " "ix_orders_fulfillment_status ON orders (fulfillment_status)" )
def downgrade() -> None: op.execute("DROP INDEX CONCURRENTLY IF EXISTS ix_orders_fulfillment_status")Instant ADD COLUMN (PostgreSQL 11+)
Since PostgreSQL 11, ADD COLUMN with a non-volatile default is instant — no table rewrite. But there is a trap: ADD COLUMN ... NOT NULL DEFAULT 'value' is instant for the default, but adding the NOT NULL constraint still requires a full table scan to verify no existing NULLs. Use the expand-contract pattern instead.
# Safe: instant metadata changeop.add_column("orders", sa.Column("priority", sa.Integer, nullable=True))
# Safe: instant with default (PG 11+)op.add_column("orders", sa.Column("priority", sa.Integer, server_default="0"))
# DANGEROUS: NOT NULL requires full table scan to verify# op.add_column("orders", sa.Column("priority", sa.Integer, nullable=False))Multi-Tenant Migration Runner
In a schema-per-tenant architecture, every migration must run across every tenant schema. A naive loop runs them sequentially — if you have 200 tenants and each migration takes 5 seconds, that is 16 minutes.
Worse, if migration 150 fails, tenants 1-149 are on the new schema and tenants 150-200 are on the old one. Your application must handle both schema versions simultaneously.
Tenant Schema Version Tracking
Track which schema version each tenant is on. This is the foundation for safe rollouts and partial failure recovery.
from dataclasses import dataclassfrom datetime import UTC, datetimefrom enum import StrEnum
from sqlalchemy import String, Integer, DateTime, select, updatefrom sqlalchemy.ext.asyncio import AsyncSession, AsyncEnginefrom sqlalchemy.orm import Mapped, mapped_column
from src.db.base import Base
class MigrationStatus(StrEnum): PENDING = "pending" RUNNING = "running" COMPLETED = "completed" FAILED = "failed" ROLLED_BACK = "rolled_back"
class TenantSchemaVersion(Base): """Track migration state per tenant — stored in the shared schema.""" __tablename__ = "tenant_schema_versions"
tenant_id: Mapped[int] = mapped_column(Integer, primary_key=True) current_revision: Mapped[str] = mapped_column(String(50)) target_revision: Mapped[str] = mapped_column(String(50), nullable=True) status: Mapped[str] = mapped_column(String(20), default=MigrationStatus.COMPLETED) last_error: Mapped[str | None] = mapped_column(String(500), nullable=True) updated_at: Mapped[datetime] = mapped_column( DateTime(timezone=True), default=lambda: datetime.now(UTC), )
@dataclassclass TenantMigrationResult: tenant_id: int success: bool from_revision: str to_revision: str error: str | None = None duration_ms: float = 0.0The Migration Runner
The runner processes tenants with controlled concurrency. It does not blindly run all tenants in parallel — that would overload the database. Instead, it uses a semaphore to limit concurrent migrations.
import asyncioimport timeimport structlogfrom collections.abc import Sequence
from alembic import commandfrom alembic.config import Config
from src.db.tenant_migrations import ( TenantSchemaVersion, TenantMigrationResult, MigrationStatus,)
logger = structlog.get_logger()
MAX_CONCURRENT_MIGRATIONS = 5
class TenantMigrationRunner: """Run Alembic migrations across all tenant schemas with concurrency control."""
def __init__(self, alembic_config: Config, engine: AsyncEngine) -> None: self._config = alembic_config self._engine = engine self._semaphore = asyncio.Semaphore(MAX_CONCURRENT_MIGRATIONS)
async def migrate_all( self, target_revision: str, ) -> list[TenantMigrationResult]: """Migrate all tenants to the target revision.""" tenants = await self._get_tenants()
tasks = [ self._migrate_tenant(tenant, target_revision) for tenant in tenants ] results = await asyncio.gather(*tasks, return_exceptions=False)
succeeded = sum(1 for r in results if r.success) failed = sum(1 for r in results if not r.success) logger.info( "migration_batch_complete", total=len(results), succeeded=succeeded, failed=failed, target=target_revision, )
return results
async def _migrate_tenant( self, tenant: TenantSchemaVersion, target_revision: str, ) -> TenantMigrationResult: async with self._semaphore: start = time.monotonic() try: await self._mark_status( tenant.tenant_id, MigrationStatus.RUNNING, target_revision, )
# Run Alembic upgrade for this tenant's schema self._config.set_main_option( "sqlalchemy.url", str(self._engine.url), ) self._config.set_main_option( "tenant_schema", f"tenant_{tenant.tenant_id}", ) command.upgrade(self._config, target_revision)
await self._mark_status( tenant.tenant_id, MigrationStatus.COMPLETED, target_revision, )
duration = (time.monotonic() - start) * 1000 logger.info( "tenant_migration_completed", tenant_id=tenant.tenant_id, revision=target_revision, duration_ms=duration, ) return TenantMigrationResult( tenant_id=tenant.tenant_id, success=True, from_revision=tenant.current_revision, to_revision=target_revision, duration_ms=duration, )
except Exception as exc: duration = (time.monotonic() - start) * 1000 error_msg = str(exc)[:500] await self._mark_status( tenant.tenant_id, MigrationStatus.FAILED, target_revision, error=error_msg, ) logger.error( "tenant_migration_failed", tenant_id=tenant.tenant_id, error=error_msg, duration_ms=duration, ) return TenantMigrationResult( tenant_id=tenant.tenant_id, success=False, from_revision=tenant.current_revision, to_revision=target_revision, error=error_msg, duration_ms=duration, )
async def retry_failed(self, target_revision: str) -> list[TenantMigrationResult]: """Retry only tenants that failed the previous migration attempt.""" async with AsyncSessionLocal() as session: stmt = select(TenantSchemaVersion).where( TenantSchemaVersion.status == MigrationStatus.FAILED, ) failed = (await session.execute(stmt)).scalars().all()
tasks = [ self._migrate_tenant(tenant, target_revision) for tenant in failed ] return await asyncio.gather(*tasks, return_exceptions=False)
async def _get_tenants(self) -> Sequence[TenantSchemaVersion]: async with AsyncSessionLocal() as session: stmt = select(TenantSchemaVersion).order_by( TenantSchemaVersion.tenant_id, ) return (await session.execute(stmt)).scalars().all()
async def _mark_status( self, tenant_id: int, status: MigrationStatus, target_revision: str, error: str | None = None, ) -> None: async with AsyncSessionLocal() as session: stmt = ( update(TenantSchemaVersion) .where(TenantSchemaVersion.tenant_id == tenant_id) .values( status=status, target_revision=target_revision, last_error=error, updated_at=datetime.now(UTC), ) ) await session.execute(stmt) await session.commit()The retry_failed method is the recovery mechanism. When migration 151 fails, you fix the issue, then call retry_failed — it picks up only the tenants that failed, not the 150 that already succeeded.
Blue-Green Schema Compatibility
During the expand phase, two versions of your application are running simultaneously: the old version (pre-migration) and the new version (post-migration). Both must work with the current schema.
The rule is strict: new code must handle the column being NULL. Old code must ignore the new column. If either assumption breaks, you get errors during the rolling deploy.
# src/models/order.py — Phase 2 code (handles both states)class Order(TenantMixin, TimestampMixin, Base): __tablename__ = "orders"
id: Mapped[int] = mapped_column(primary_key=True) customer_id: Mapped[int] = mapped_column(ForeignKey("customers.id")) status: Mapped[str] = mapped_column(String(20)) total: Mapped[Decimal] = mapped_column(Numeric(10, 2))
# New column — nullable during expand phase fulfillment_status: Mapped[str | None] = mapped_column( String(20), nullable=True, )
@property def effective_fulfillment_status(self) -> str: """Backward-compatible accessor during migration.""" if self.fulfillment_status is not None: return self.fulfillment_status # Derive from old status column for unbackfilled rows if self.status == "shipped": return "shipped" if self.status == "delivered": return "delivered" return "pending"The effective_fulfillment_status property provides a consistent interface regardless of whether the row has been backfilled. Service layer code uses this property instead of the raw column. After Phase 3, the property simplifies to a direct column access.
Data Migrations: Separate and Batchable
Data migrations (backfilling values, transforming formats) are fundamentally different from schema migrations (adding columns, creating indexes). They should never be in the same Alembic revision.
The reason is operational: a schema migration that takes 50 milliseconds becomes a schema migration that takes 20 minutes when you add a backfill. If the backfill fails at row 40 million, you cannot cleanly downgrade the schema portion.
"""Standalone backfill script — run independently of Alembic."""
import asyncioimport structlogfrom sqlalchemy import textfrom sqlalchemy.ext.asyncio import create_async_engine
logger = structlog.get_logger()
BATCH_SIZE = 5_000SLEEP_BETWEEN_BATCHES = 0.1 # seconds — reduce DB pressure
async def backfill(database_url: str) -> int: engine = create_async_engine(database_url) total_updated = 0
async with engine.begin() as conn: while True: result = await conn.execute(text(""" WITH batch AS ( SELECT id FROM orders WHERE fulfillment_status IS NULL LIMIT :batch_size FOR UPDATE SKIP LOCKED ) UPDATE orders SET fulfillment_status = CASE WHEN status = 'shipped' THEN 'shipped' WHEN status = 'delivered' THEN 'delivered' ELSE 'pending' END FROM batch WHERE orders.id = batch.id """), {"batch_size": BATCH_SIZE})
if result.rowcount == 0: break
total_updated += result.rowcount logger.info( "backfill_progress", updated_this_batch=result.rowcount, total_updated=total_updated, ) await asyncio.sleep(SLEEP_BETWEEN_BATCHES)
logger.info("backfill_complete", total_updated=total_updated) return total_updated
if __name__ == "__main__": import sys asyncio.run(backfill(sys.argv[1]))Key decisions in this script:
FOR UPDATE SKIP LOCKEDprevents conflicts with concurrent writes and other backfill instancesSLEEP_BETWEEN_BATCHESreduces sustained load on the database — without it, the backfill monopolizes I/O- Batch size of 5,000 is small enough to avoid long-running transactions but large enough to be efficient
- CTE-based update ensures the
SELECTandUPDATEare in the same statement, preventing TOCTOU races
Migration Rollback Strategy
Every migration must have a working downgrade. This is not optional. If Phase 3 reveals a bug, you need to roll back to Phase 2 without data loss.
The test is straightforward: run upgrade, insert test data, run downgrade, verify the application works, run upgrade again, verify the test data survived. If any step fails, the migration is not ready.
import pytestfrom alembic import commandfrom alembic.config import Config
@pytest.fixturedef alembic_config(test_database_url: str) -> Config: config = Config("alembic.ini") config.set_main_option("sqlalchemy.url", test_database_url) return config
def test_migration_round_trip(alembic_config: Config) -> None: """Every migration must survive upgrade → downgrade → upgrade.""" command.upgrade(alembic_config, "head") command.downgrade(alembic_config, "base") command.upgrade(alembic_config, "head") # If we get here without errors, the migrations are reversiblePartial Failure Recovery
The worst migration scenario is partial success across tenants. Tenants 1-150 are on revision 003_contract. Tenant 151 failed because it had a row violating the new constraint. Tenants 152-200 are still on 002_migrate.
The migration runner’s status tracking handles this:
# CLI command for migration operationsasync def migration_status(engine: AsyncEngine) -> None: """Print migration status for all tenants.""" async with AsyncSessionLocal() as session: stmt = select(TenantSchemaVersion).order_by( TenantSchemaVersion.status, TenantSchemaVersion.tenant_id, ) versions = (await session.execute(stmt)).scalars().all()
by_status: dict[str, list[int]] = {} for v in versions: by_status.setdefault(v.status, []).append(v.tenant_id)
for status, tenant_ids in by_status.items(): print(f"{status}: {len(tenant_ids)} tenants") if status == MigrationStatus.FAILED: for tid in tenant_ids: tenant = next(v for v in versions if v.tenant_id == tid) print(f" Tenant {tid}: {tenant.last_error}")The recovery workflow:
- Run
migration_statusto identify failed tenants - Fix the data issue on the failed tenant (remove constraint-violating rows, fix bad data)
- Run
retry_failedto resume from where it stopped - Verify all tenants report
COMPLETED
Your application code must work with tenants on different schema versions during this window. The effective_fulfillment_status property pattern from earlier handles this at the model level.
What Happens Without This
That eight-minute CREATE INDEX without CONCURRENTLY was ShelfWise’s first production incident. The lesson was expensive: 200 tenants lost order processing for eight minutes. The postmortem identified three root causes: no expand-contract discipline, no concurrent DDL, and no migration testing against production-scale data.
The second incident was worse. A data migration ran inside the schema migration. It failed at row 30 million on tenant 151. The migration had already modified the schema for tenants 1-150. The downgrade path had not been tested. Recovery took four hours and a point-in-time backup restore.
Both incidents were entirely preventable with the patterns in this post.
Checklist
Before running any migration in production:
- Schema changes use expand-contract: nullable first, backfill second, constrain third
CREATE INDEX CONCURRENTLYfor all index creation on existing tablesNOT VALID+VALIDATE CONSTRAINTfor adding NOT NULL constraints- Data migrations are separate scripts, not Alembic revisions
- Backfills run in batches with sleep intervals between them
- Every migration has a tested downgrade path
- Multi-tenant runner tracks per-tenant migration status
retry_failedrecovers from partial failure without re-running successful tenants- Application code handles both old and new schema during the migration window
- New code runs against old schema in CI before deploying the migration
The next post in this series will tackle API versioning — how to evolve your endpoints without breaking existing integrations, and how multi-tenancy adds a layer of complexity when different tenants need to stay on different API versions.